
OKF:LLM Wiki 知识库的落地实践标准
技术调研做到一定深度,往往会有一种熟悉的感觉:资料搜集了一大堆,关键结论心里也有数,可真要让 AI 帮忙整合出个清晰的知识结构,对方却总是一副“信息太多,我抓不住重点”的样子。
这种情况,本质上不是笔记没写好,而是笔记之间缺乏了一张“地图”。AI 无法判断哪一篇是深入分析方案 A 的缺陷、哪一篇是在对比方案 B 的适用场景。它面对的只是一锅乱炖的文本,而不是一个有序的知识库。
Karpathy 提出的 LLM Wiki 概念——采集、整理、生成可查询的 wiki——指明了方向。但一旦进入实操阶段,一堆实际问题就冒了出来:frontmatter 到底放哪些字段才合适?目录该怎么组织才最高效?AI 应该按什么路径来检索知识?这些关键环节长期缺乏公认标准,大家都在摸着石头过河。
OKF 正是在这个背景下,补上了最关键的一环。
OKF 是什么
OKF 说白了就是 Google Cloud 在 2026 年初推出的一套
知识表示格式规范
这套规范异常轻量,核心原则只有三条:
最小化偏见
type。其余字段完全自由定义。
生产者/消费者独立
格式不绑定平台
.md 文件。用 Git 管理也好,归档成 tarball 也罢,甚至直接拷贝,都行,没有任何专属依赖。
所以 OKF 真正回答的实践问题集中在三点:header 该写什么(type 必填,其余自定)、数据如何组织(index.md + 分类目录 + references)、以及 AI 该怎么找(从 index.md 开始,顺着链接逐层深入)。
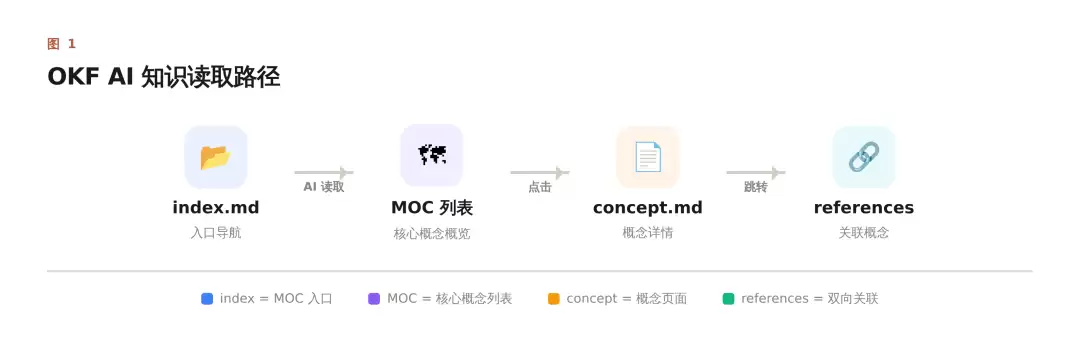
OKF 和 PKM 已有实践的对应关系
如果你用过 Obsidian 等笔记工具,看到 OKF 的结构应该会感到熟悉——它们的底层逻辑几乎一致,只是术语有所区别:
| OKF 概念 | PKM 对应 | 说明 |
|---|---|---|
index.md | MOC(Map of Content) | 入口导航页,列出该领域的核心页面 |
| 目录分层结构 | PARA / 主题文件夹 | 按领域组织,不是扁平文件列表 |
frontmatter type | 页面类型标签(Concept / Note / Reference) | 定义这篇笔记是什么类型的知识 |
| references | 双向链接 [[wikilink]] | 概念之间的关联 |
type: Reference | Literature Note | 引用来源 |
OKF 把这些分散的做法系统化、标准化了,并配套了工具链。但如果你已经在用 Obsidian 做日常知识管理,完全可以理解为:你早就用自己的方式践行 OKF 的思路了,只是没有意识到这和 Google 提出的正式规范是同一件事。
一个关键分类:Skill 和 OKF 各司其职
在 AI Agent 的语境里,Skill 和 OKF 经常被混为一谈,但它们解决的是完全不同的问题:
- = 程序性知识,回答「怎么做」
Skill
- = Declarative 知识,回答「是什么」以及「知识在哪里」
OKF
一个典型的技术调研场景中:OKF 负责告诉 AI「方法 A 是什么、适用场景是什么、和方法 B 的核心差异是什么」;而 Skill 负责「用方法 A 写一段示例代码、用 pip 安装这个包」。两者缺一不可,而且分工明确。
这与 CoALA 框架也是一一对应的:
- :怎么做(Skill)
程序性记忆
- :是什么、在哪里(OKF)
语义记忆
- :发生了什么(Chat History / Daily Notes)
情景记忆
OKF vs RAG:不是替代,是分工
| RAG | OKF | |
|---|---|---|
| 本质 | 检索技术 | 知识表示格式 |
| 知识组织 | 非结构化 Chunk,向量索引 | 结构化图谱,预先定义关联 |
| 查询方式 | 语义相似度搜索 | 精确路由(读索引 → 读概念 → 读详情) |
| 维护成本 | 低,追加文档即可 | 高,需要同步更新 |
| 适用场景 | 变化频繁的非结构化知识 | 相对稳定、有明确 Schema 的领域 |
可以理解成:
RAG 是搜索引擎
OKF 则是翻目录
更合理的组合方式是:
先用 OKF 定义知识的边界和关联,让 AI 先确定该查哪个库;再用 RAG 在具体库内做精细的语义搜索。
enrichment_agent 工具链
OKF 官方提供了一套参考实现工具 enrichment_agent,基于 Google ADK(Agent Development Kit)构建,包含两个 AI Agent:
| Agent | 能力 |
|---|---|
build_bq_agent | 读取 BigQuery 表结构,自动生成 metrics + joins |
build_web_agent | 抓取官方文档,生成对应的 reference 文档 |
背后默认调用的是 gemini-flash-latest,这意味着整个生成过程是高度 AI 密集型的,而不是简单的硬编码规则。
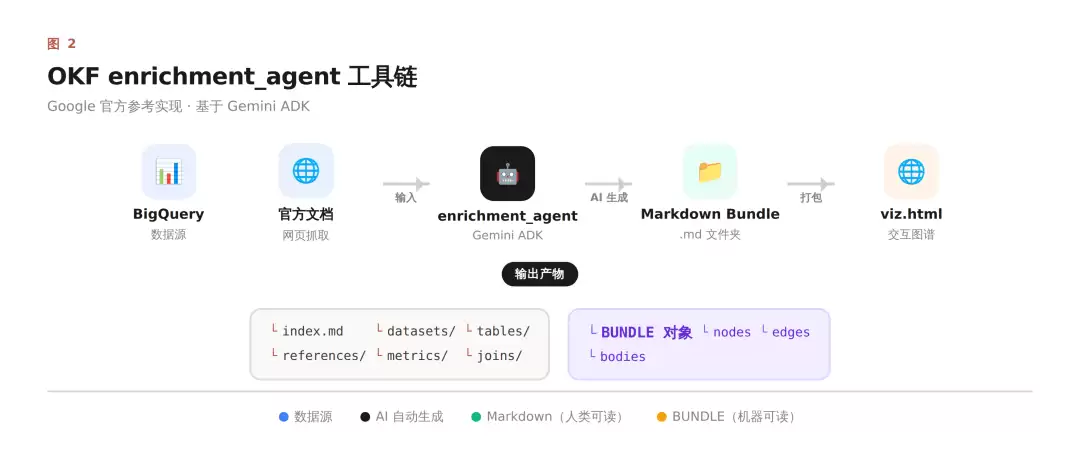
生成完 Markdown 文件后,writer.py 会把所有内容整合进 viz.html——一个自包含的交互图谱,用 Cytoscape.js 渲染节点关系,点击节点就能看到完整的文档内容。
最终交付两个核心产物:
人类可读的 Markdown 文件
AI 可消费的 BUNDLE 对象
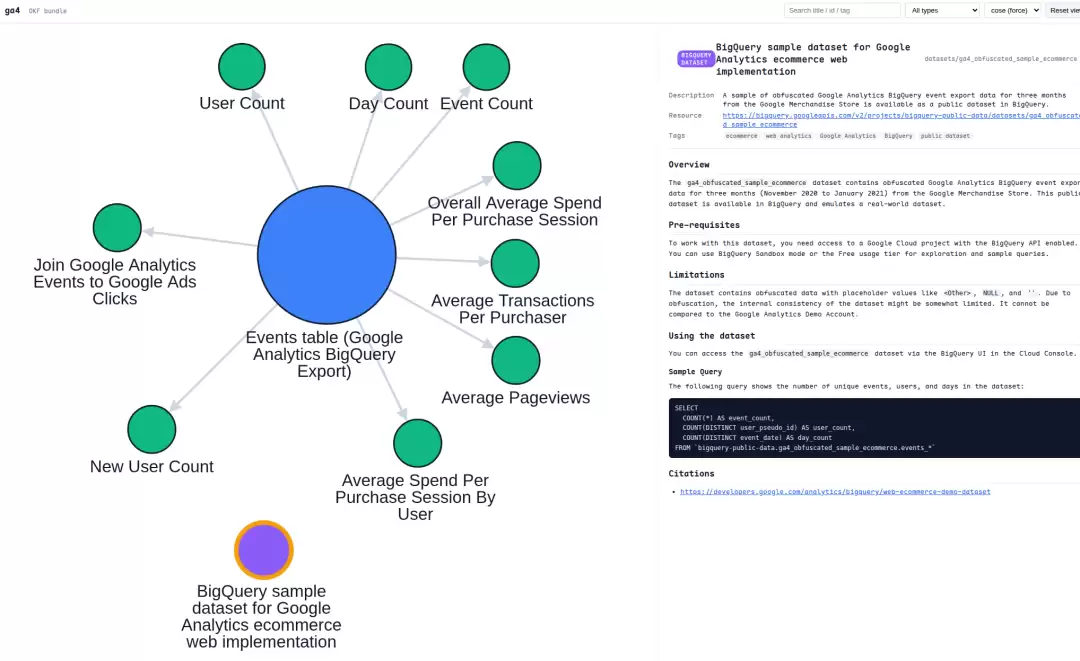
viz.html 图谱:实际效果
OKF 官方提供的 viz.html 用 Cytoscape.js 渲染成了一个交互式知识图谱。以 GA4 Bundle 为例:
点击任意节点,右侧面板会立刻展示该概念的完整文档,包括其 frontmatter 元数据和 Markdown 正文:
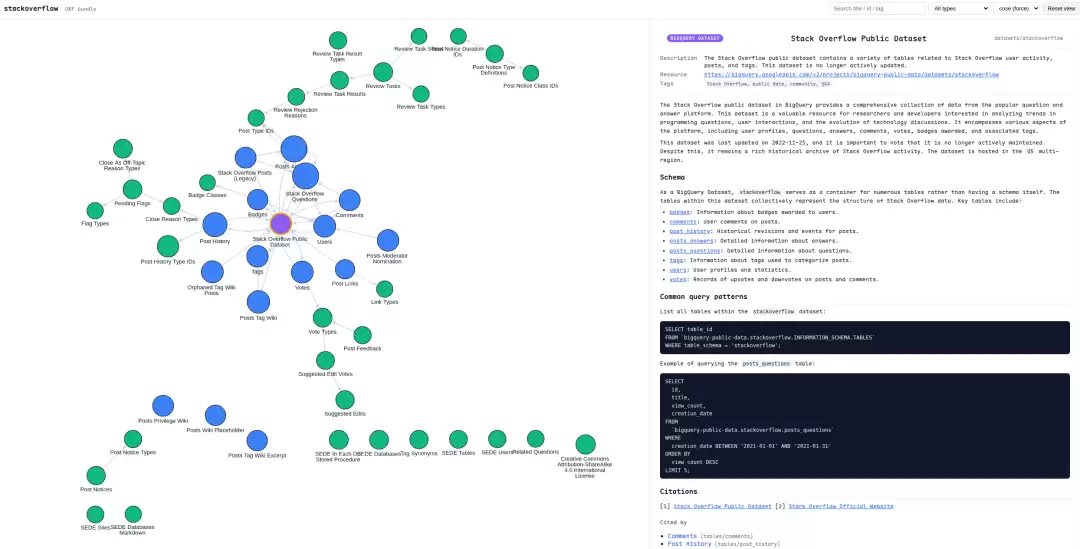
它还支持按节点类型过滤、快速搜索、以及查看每个节点的「Cited by」反向引用:
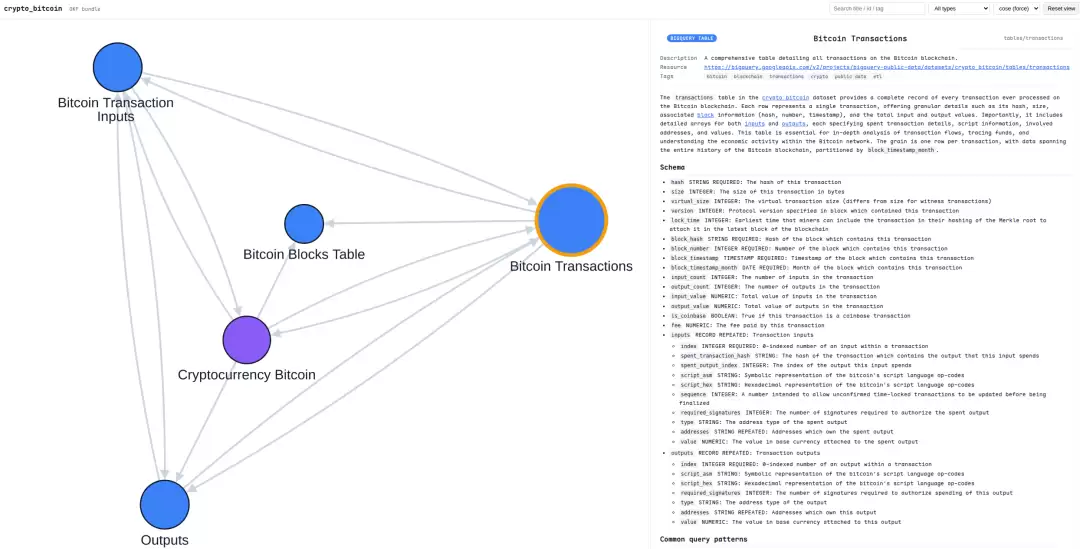
这里有一个值得注意的细节:
OKF 使用的是标准 Markdown 链接 [text](path.md),而 Obsidian 则使用双向链接 [[wikilink]]。如果你把一个 OKF Bundle 直接拖进 Obsidian,它的 graph 视图会是一片空白——因为 Obsidian 只识别 [[]] 语法。目前这两者之间并没有很好的兼容解决方案。
Bundle 结构:知识如何分层组织
一个 OKF Bundle 本质上就是一个目录,承载着某个知识领域的所有完整文档:
ga4/
├── index.md # 入口(MOC 导航页)
├── datasets/
│ └── ga4_obfuscated_sample_ecommerce.md
├── tables/
│ └── events_.md
└── references/
├── metrics/
│ ├── event_count.md
│ └── user_count.md
└── joins/
└── events___ads_clickstats.md
每个 .md 文件的结构都是
YAML frontmatter + Markdown body
---
type: BigQuery Table
title: Events table
description: 包含 Google Analytics 事件导出数据
resource: https://bigquery.googleapis.com/...
tags: [events, Google Analytics, BigQuery]
---
body 则分层写入:Overview → Schema → Metrics → Joins → Citations。
对个人知识库的启发
OKF 最大的价值,不是让你再引入一套新系统,而是促使你重新审视并精进已有的几个关键实践:
MOC 是入口,不是装饰
路由
frontmatter 的 type 字段值得认真填写
type,这并非随意设计。类型标签是机器理解一篇笔记「是什么」的最直接且高效的路径。
