
GLM-5.2 技术解读:智谱百万上下文的新一代旗舰模型
AI 领域这几天出了个大新闻——智谱AI 正式开源了他们的最新旗舰模型 GLM-5.2。这款专门为长程任务设计的模型,在百万级超长上下文上实现了稳定可靠的工程表现,为开发者和研究社区提供了一个相当扎实的开源选择。
先快速梳理一下这次升级的硬核要点:
- 四大核心能力全面进化,外加MIT协议的完全开源
- 在多项长程任务基准测试中,拿下开源模型第一名的成绩
- 引入灵活的推理投入度控制,兼顾性能与成本
- 标准编程基准测试上,相比前代有了质的飞跃

GLM-5.2 的核心升级
GLM-5.2 是智谱AI针对长程任务场景推出的最新旗舰模型。相比上一代 GLM-5.1,这次的重点突破在于:它首次在 100 万 token 的超长上下文上,拿出了真正稳定可靠的工程表现。
四大核心能力升级一览:
| 能力 | 说明 |
|---|---|
| ? 稳定百万上下文 | 真正可用的 1M token 上下文,稳定支撑长程工程任务 |
| ? 灵活编码能力 | 多档"推理投入度",按需平衡性能与延迟 |
| ? 架构级优化 | 提出 IndexShare + MTP 改进,推理性价比更高 |
| ? 完全开源 | MIT 协议,无区域限制,开放获取无壁垒 |
1. 稳定的百万级上下文
长上下文的真正挑战,不在于参数上能接受多少 token,而在于面对超长且杂乱无章的 Agent 轨迹时,能否始终保持质量稳定。1M context 谁都可以声称,但要在真实工程压力下保持稳定可靠,这才是真正的分水岭。
GLM-5.2 的做法是大幅扩展面向 Agent 场景的百万 token 训练数据,覆盖大规模代码实现、自动化研究、性能优化和复杂调试等核心场景。简而言之,这个模型的“窗口”不仅宽,而且执行起来相当稳,能够作为可持续工程工作的实用基础。
- 大规模代码实现
- 自动化研究
- 性能优化
- 复杂调试
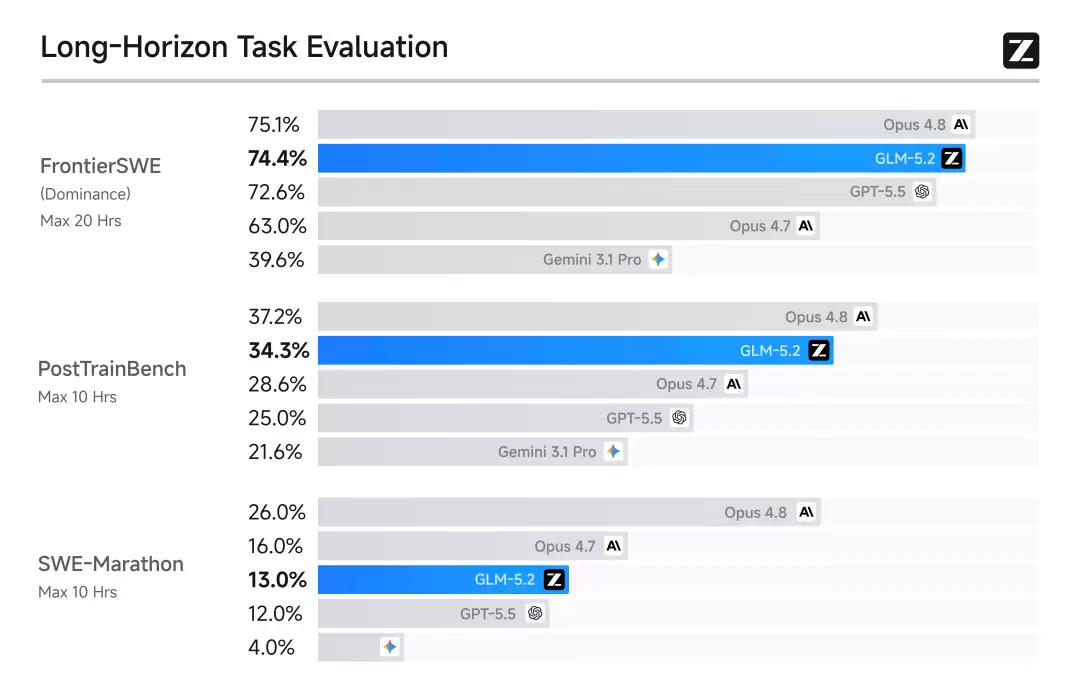
在几项关键的长程任务基准测试中的表现:
| 基准测试 | GLM-5.2 表现 | 排名 |
|---|---|---|
FrontierSWE | 距 Opus 4.8 仅差 1%,领先 GPT-5.5 约 1%,领先 Opus 4.7 约 11% | 开源第一 |
PostTrainBench | 超越 Opus 4.7 和 GPT-5.5,仅次于 Opus 4.8 | 排名第二 |
SWE-Marathon | 距 Opus 4.8 差 13%,但稳居开源第一,仅次于 Opus 系列 | 开源第一 |
在三项长程基准测试中,GLM-5.2 均为开源模型第一名。这说明它的 1M 上下文能力已经实实在在地转化成了长程任务的交付能力,不是空谈。
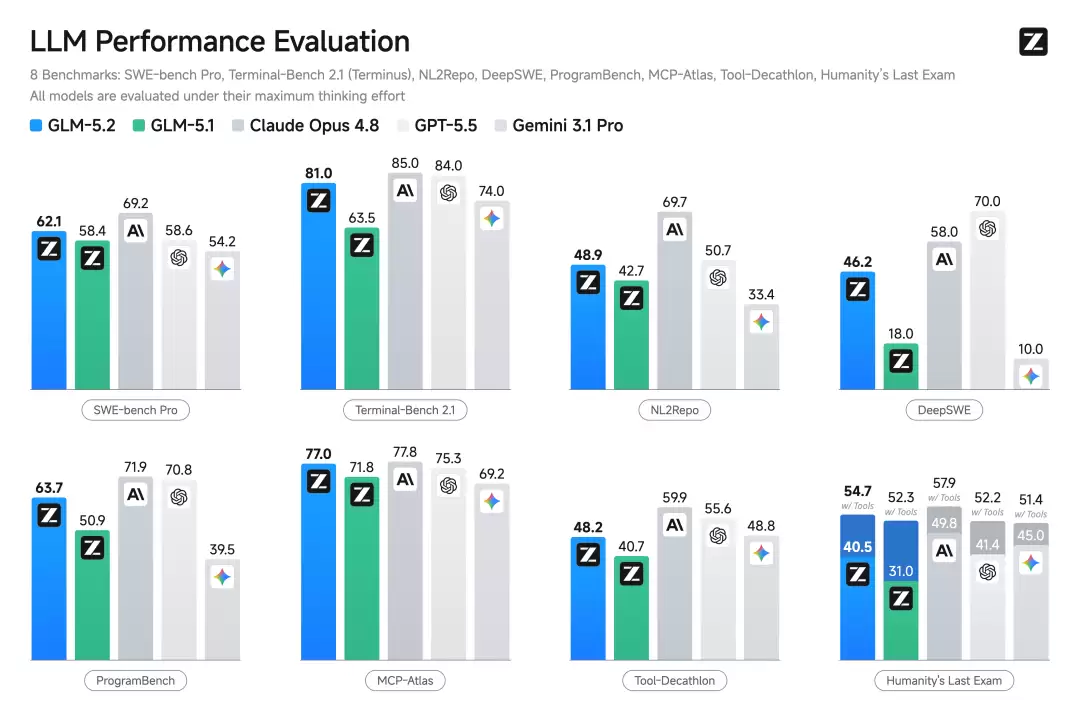
2. 标准编程基准测试
| 基准测试 | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 81.0 | 63.5 | 85.0 | - |
| SWE-bench Pro | 62.1 | 58.4 | - | - |
- GLM-5.2 在标准编程基准上已经是目前最强的开源模型,相比 GLM-5.1 的提升非常显著。
- Terminal-Bench 2.1 上仅落后 Claude Opus 4.8 几个百分点,且超越了 Gemini 3.1 Pro。
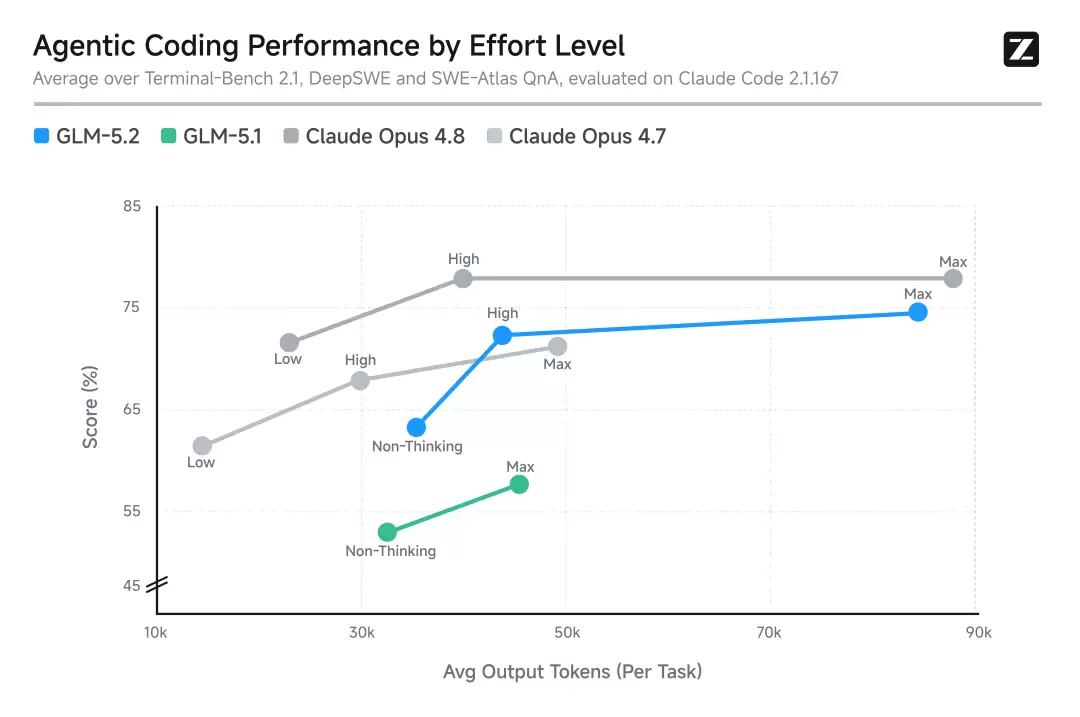
3. 灵活推理投入度控制
GLM-5.2 引入了一个很实用的功能——多档推理投入度控制。这意味着用户可以根据具体场景,在模型能力与任务执行速度/计算成本之间自由选择。
- 在相同的 token 消耗下,GLM-5.2 的 Agent 编程性能远强于 GLM-5.1,整体能力定位大致在 Claude Opus 4.7 与 Opus 4.8 之间。
- 在极具挑战的任务上,可以分配更多计算资源,进一步提升编程能力。
Max 档位:
- 设计哲学很明确:给用户更大的灵活性,让不同场景都能找到最适合的推理模式。
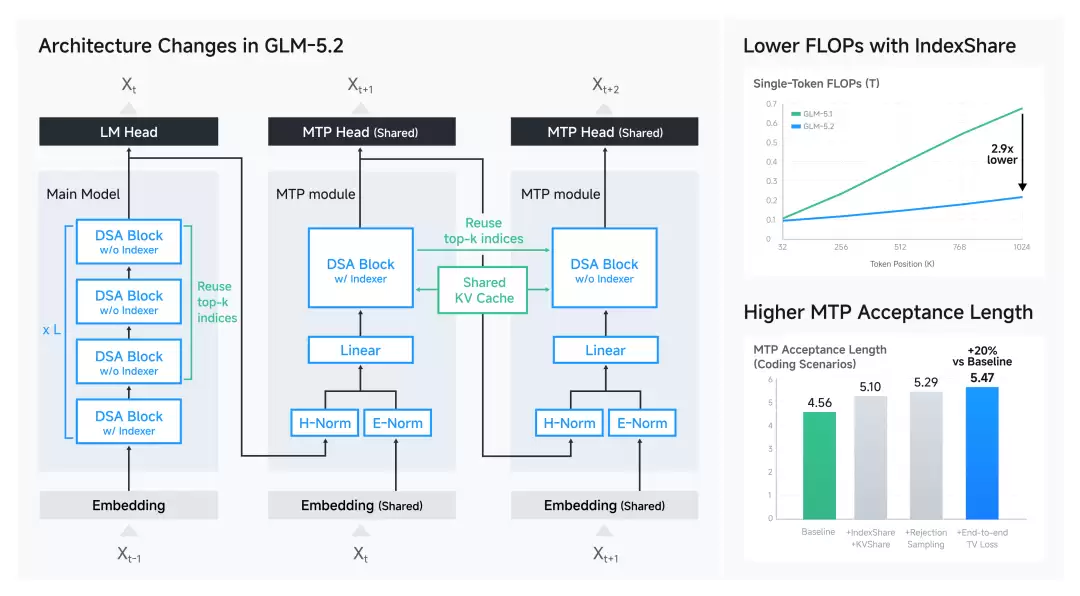
4. 百万上下文架构:IndexShare
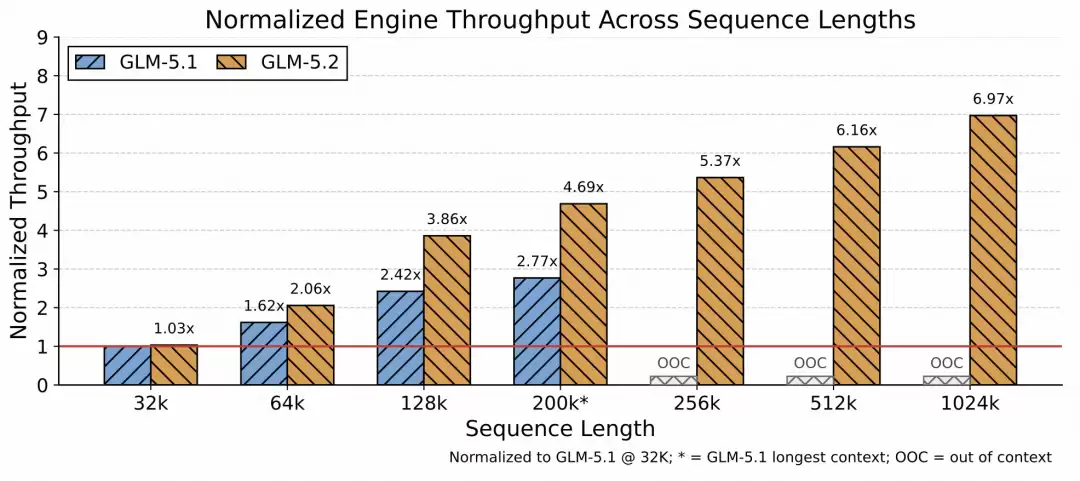
4.1 为什么需要 IndexShare?
当上下文长度达到 1M 时,动态稀疏注意力的 indexer 计算成本会急剧增加。为了解决这个工程难题,GLM-5.2 应用了 IndexShare 技术。
核心做法:
效果相当直观:
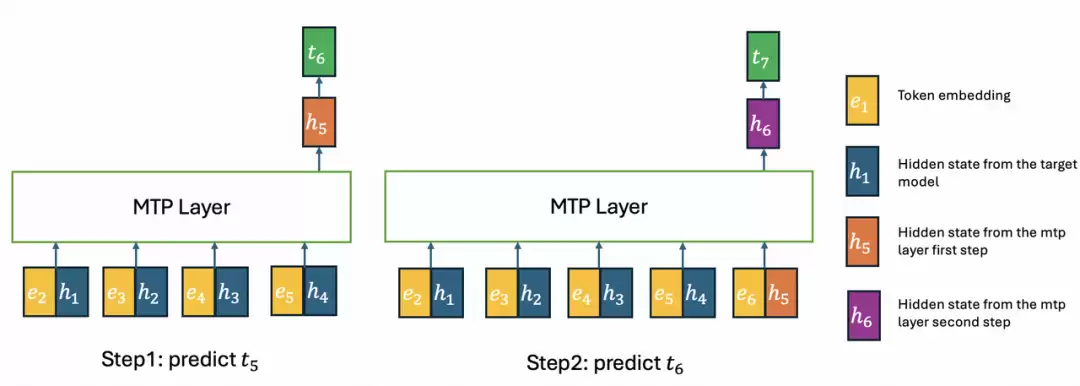
4.2 MTP 层与 KV 优化
GLM-5.2 对多 token 预测层做了两项关键改进,专门服务于投机解码。
目标一:
目标二:
以两步 MTP 推理为例:第一步与训练一致,所有隐状态来自目标模型;第二步时,前四个 token 的隐状态来自目标模型,第五个 token 来自 MTP 层,这会造成 KV 缓存的不一致。IndexShare 完美解决了这个问题——通过在 MTP 各步复用 top-K 索引,保持推理时 KV 缓存的一致性,MTP 接受长度最高提升了 20%。
5. 完全开源
GLM-5.2 采用 MIT 开源协议,这意味着:
- 无区域限制
- 技术获取无国界壁垒
- 可自由商用、修改和分发
总结
GLM-5.2 可以说是智谱在长程 Agent 能力上的一次重大突破:
- 真正从“能接受”变成了“用得住”,大幅扩展了编程 Agent 的任务边界。
百万上下文
- 将 1M 上下文的计算成本降低近 3 倍,实用性大幅提升。
IndexShare 架构
- 让用户按需平衡性能与成本,适配从快速验证到深度研究的多样场景。
多档 Effort Level
- 让全球开发者可以无障碍地获取和使用。
MIT 开源
GLM-5.2 已经是目前开源编程模型的新标杆。在长程任务上,它与闭源顶级模型(Opus 4.8、GPT-5.5)的差距已经大幅缩小,这才是正在重新定义开源编程模型天花板的关键一步。