
Agent 记忆,我们全都理解错了?
Agent 记忆的概念被过度包装?这篇内容直击本质,梳理出 Agent 记忆的四层理解框架,帮你穿透迷雾。
核心要点:
1. 早期记忆理解的局限性
2. CoALA 分类法如何定义广义记忆
3. 从工程实践看记忆演进的未来方向

做 Agent Memory 工程化探索的这几个月里,一种被概念淹没的窒息感始终挥之不去。图结构记忆、AutoMemory、做梦机制,还有层出不穷的 Memory 框架……整个技术社区似乎陷入了一种每遇到一个新场景就要发明一套新词汇的群体焦虑中。
但这恰恰说明,我们连 Agent 记忆究竟是什么都没想清楚。更扎心的是,很多所谓前卫的理解,看似花样繁多,实则舍本逐末,仿佛在开历史的倒车。
更别提 Memory 的发展方向,早在一串眼花缭乱的概念包装之下,成了视野盲区。
基于这数月的工程落地实践,下面围绕这个根源问题逐层拆解,谈谈对 Agent 记忆的四层理解。
第一层:早期的记忆,二元论的雏形
最早的记忆分类,直接搬用了人类心理学最表面的概念:短期记忆与长期记忆。短期记忆,就是大模型上下文还塞得下的部分,或者用简单的 md 文件记下来的临时信息、用户偏好——比如 Claude 走的就是这套。长期记忆,则是把大量历史聊天全部记下来,按需检索调用。

在这一层视角下,记忆的内涵非常狭义——只有你与 Agent 的对话历史,才配被称为记忆。这种理解虽然直观,但很快就在复杂的工程实践中撞了墙。
第二层:CoALA 分类法
2023 年 9 月,一篇名为 CoALA(Cognitive Architectures for Language Agents)的开山论文提出了一套全新的认知架构分类法。2024 年,LangChain 也在博客中引用了这一理论。

坦白讲,第一次看到这篇论文时,觉得它极其抽象,甚至有点迎合学术界造词的嫌疑。它将记忆切分成了三个长期维度(外加一个等同于短期工作空间的 Working Memory):
- Procedural Memory(程序记忆 / 技能记忆):关乎如何做。
- Semantic Memory(语义记忆 / 事实记忆):关乎是什么。
- Episodic Memory(情景记忆 / 事件记忆):关乎经历过什么。
(论文里还有一类 Working Memory,其实就是前面说的短期记忆;上面这三类对应的都是长期记忆。)
今天重新审视这些当初显得有些玄乎的词汇,会发现它们以一种近乎神迹的精确度,踩中了这两年 AI Agent 的全部演进路线:
- 程序记忆,不就是今天卷得如火如荼的 Skill 吗?
- 语义记忆,不就是沉淀了无数业务知识的 RAG 和知识库吗?
- 情景记忆,正是最早期所执着的 Session 历史对白。
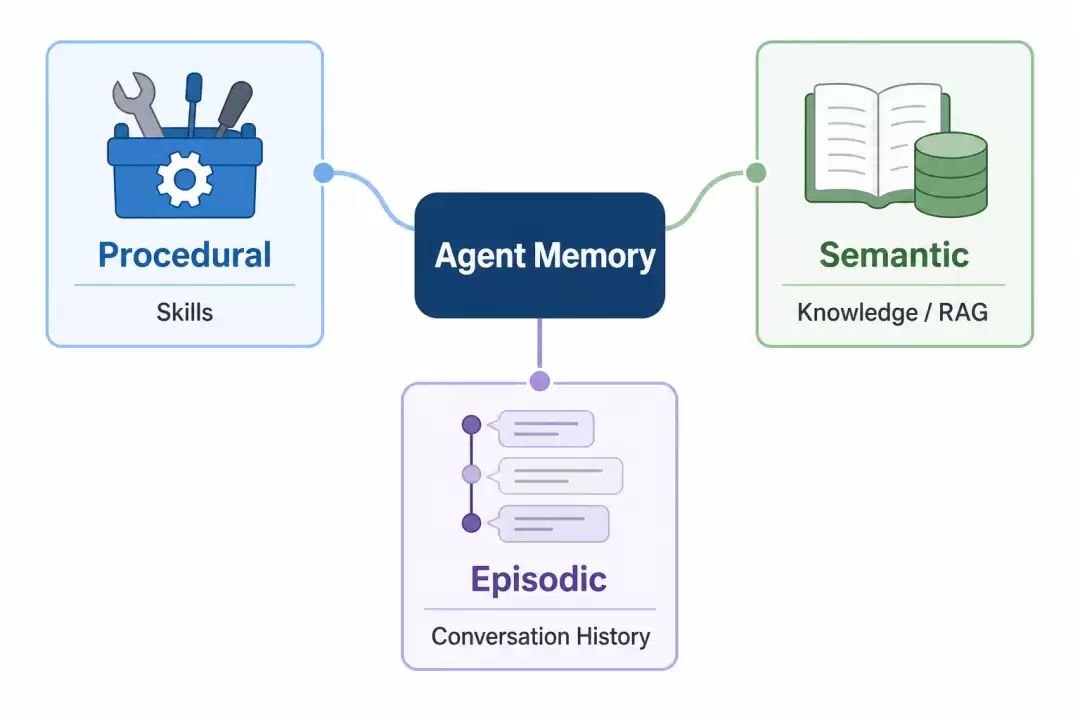
这是一套真正站得住脚的广义记忆分类法。反观人类自身:你的记忆是什么?是你跟谁聊过天、在哪踩过坑(情景);是你读过什么书、背过什么公式(语义);以及你学会了怎么开车、怎么写代码(程序)。更进一步,skill 与知识库都算记忆,两者之间有着微妙的相似与差异:知识库是静态的,像抽象的书本财富;而技能,是从实践中抽象出来的、具体把一件事做成的 SOP(标准作业程序)。
复盘这个思路的演变,会发现:2023 年 CoALA 描绘蓝图,2024 年 LangChain 推波助澜,2025 年 Anthropic 确立 Skill 规范,2026 年初 OpenClaw 引爆记忆技术——优秀的技术架构永远是对人类认知本质的临摹。不管后来的技术怎么折腾,都跳不出这套古典认知的引力场。
第三层:载体的哲学,记忆要不要用 md 存
在工程落地层面,OpenClaw 带来一个极具技术审美的范式:将记忆落盘为原始的 Markdown 文件(Source of Truth),而向量数据库等索引仅仅是它的派生物。

当用户直接修改 md 文件,真相便被修改,索引层随后进行近实时响应更新。这种做法表面上解决了云端结构化存储的隐私焦虑、可读性差与擦除困难的问题,但更深层来说,它解决了记忆的天然形态问题——一个可被用户浏览修改的记忆,应当是自然语言,而非结构化数据。因为记忆天然就是一个需要用自然语言来描述的场景,不该被某种结构化的框架框死。
这背后,其实是自然语言这种非结构化数据本身的强大。过去那种试图将现实世界中流动的、复杂的记忆强行塞进预设的数据库字段里,是一种对信息的粗暴裁剪。举个反例:假设你想记住用户的一个偏好——他喜欢周五下午发版,但如果当周有大版本,就推迟到下周一,除非 PM 在催。试问,在传统的结构化表格中,你的发版时间字段该填什么?周五还是周一?那些微妙的前提条件、情绪博弈和例外情况,又该安放在哪一个字段里?强行切碎的结果,就是记忆深层含义的彻底丢失。
这让人想起 Geoffrey Hinton 去年在上海世界人工智能大会上提出的那个惊艳的比喻:自然语言就像乐高积木。每一个 Token 都是一块最小的积木单元。当你要表达一个意图、一段记忆、一种逻辑时,其实是用这些积木在非线性的高维空间中拼出一个特定的形状。这个比喻太到位了——就在那一瞬间,仿佛看见了自然语言的形状。
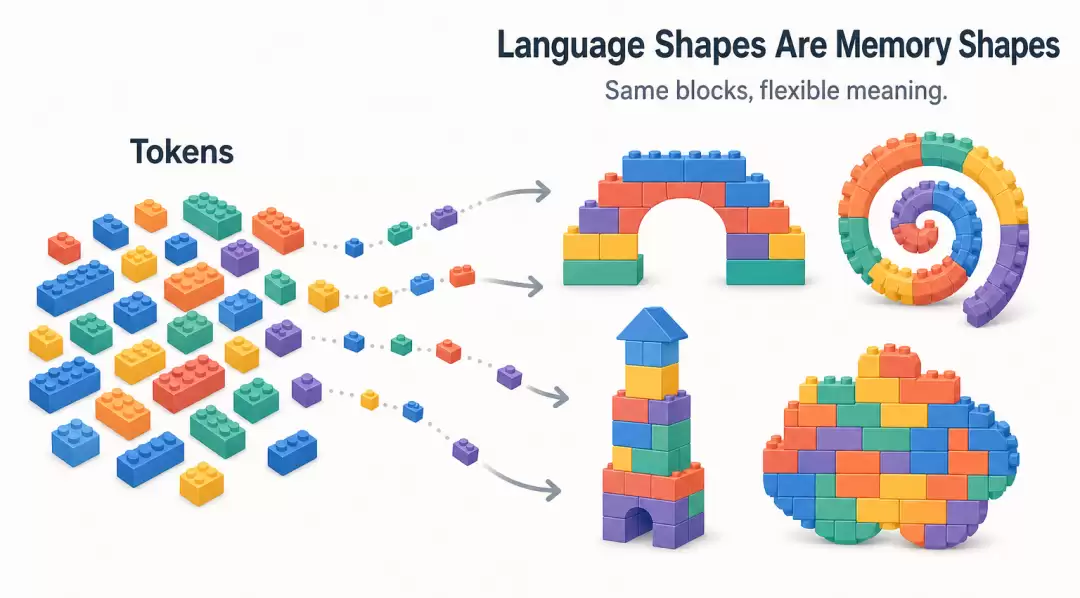
现代 Agent 的大厦——无论是复杂的 Tool Harness、多步骤的长程任务,还是今天讨论的记忆——其最坚固的基石,正是这种具备无穷拓扑可能性的非结构化乐高积木(Token)。用 Markdown 承载记忆,本质上是对自然语言表达力的一种最高敬意。
当然,结构化记忆并非一无是处。在特定象限内,它依然有独特的生态位:
- 。比如营销记录——一笔营销到底是成功、失败、还是中间状态?可以用结构化的方法去标记、打标签。客户怎么分类、属于哪个行业,也适用结构化。
比较专用的场景
- 。把一份记忆内容做结构化分类,比如画成表格、做成 HTML,配上一点炫酷的样式,呈现效果非常好,各维度对比演进一目了然。
展示效果
- 。比如三元组提取、图结构提取。这类方法确实通用:一份记忆,不管用什么自然语言描述,里头总会有主语、谓语、宾语,所以总能提取出三元组。用图结构描述一件事,也能把关系看得很清楚,对那些复杂、专业、带多重依赖的场景,比如金融、法律、医药,确实有帮助。
与场景无关的通用方法

总的来说,这两条路线在短期内不会归一,而是会在不同具体场景中完成各自的利益取舍。
第四层:自举的闭环——Memory-to-Skill
前面讲过,Skill 其实也算一种记忆,叫 Procedural Memory(程序记忆 / 技能记忆)。而当前技术社区最致命的断层就在于:我们把记忆和技能做成了两套完全割裂的系统。或者说,还没想清楚两者之间的关系,缺少描述两者关系的范式,这一块还有很大发展空间。
目前,我们已经解决了 Skill 的查找和调用问题。各个 Agent 自带的 System Prompt 和 harness 里,已经把 Skill 的调用机制做好了,靠的是 Skill 的渐进式披露(progressive disclosure):只要在 md 的 front matter 里写清楚这个 Skill 该在什么条件下调用,Agent 就能根据这些披露出来的触发条件,自动把它调起来。所以查找和使用,已经不是问题了。
然而,Skill 的写入和更新问题,却成了工程灾难。
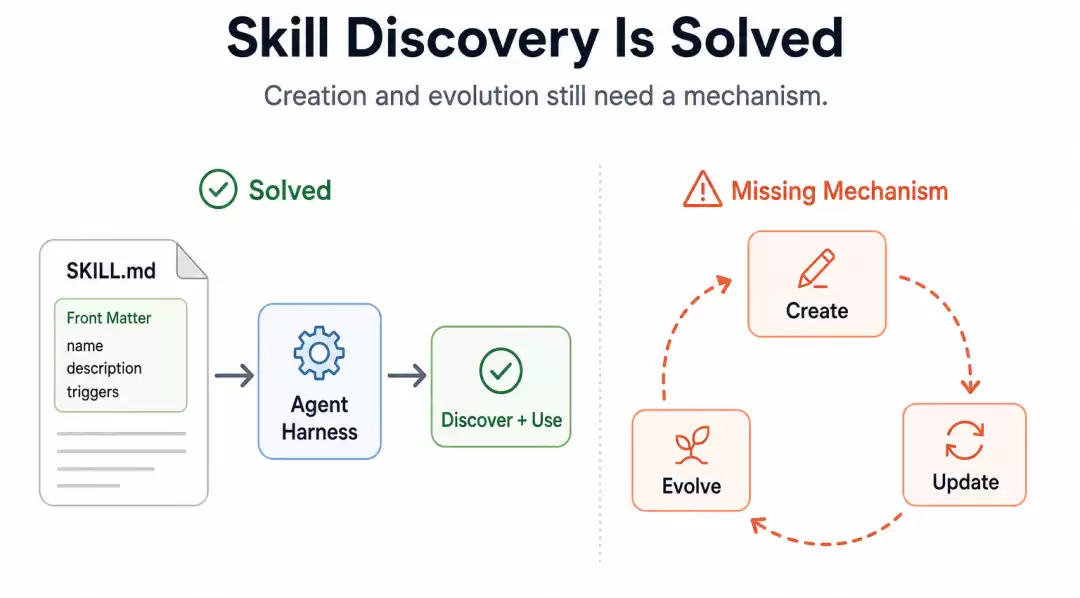
- :现在确实很多工具能让用户从零创建一个 Skill。比如下面这张截图,就是用 Codex 的 Skill Creator 去创建一个 Skill,需要写大量冗长的 prompt,才能把事情讲清楚。
关于写入 Skill

除了要手动写大量来龙去脉的背景,可能还要反复跟 Agent 来回反馈微调,不断手动测试,才能打磨好一个 Skill。而且,Claude 和其他 Agent 的默认 Skill 安装路径也不同,没法方便打通。整体使用体验并不好。
- :最近冒出来的一些项目是关于 Skill 的进化机制的:先准备一些验证数据集,让 Agent 去跑各种 Skill 变体,再根据反馈打分,看哪个变体在验证集上效果更好,从而决定进化方向。这个方法的麻烦在于,你得准备真实的数据集,而且操作非常重,要做大量探索去寻找进化方向,有点像在训练一个 Skill。这套机制太重了,还得依赖准备数据集、铺各种数据场景和环境,特别折腾。
关于 Skill 的更新
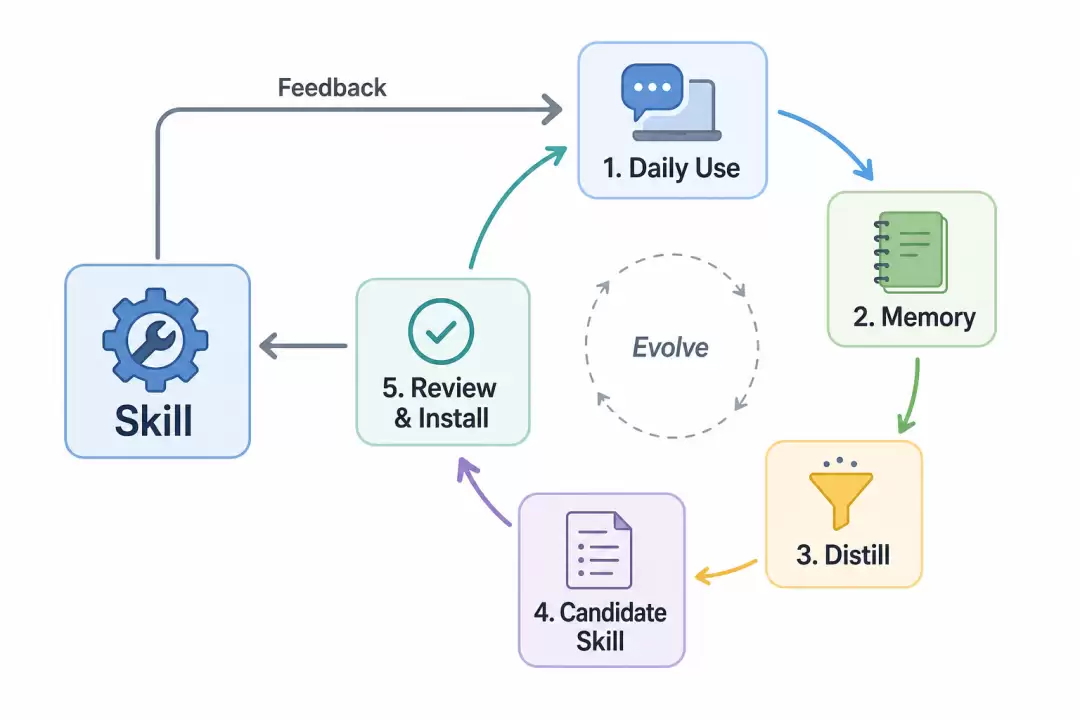
那么,为什么不从 Agent 现有的记忆中,直接长出 Skill?理论上,我们与 Agent 过去发生的每一次对话、每一次 debug、每一次调通 API 的历史(Episodic Memory),本身就是最真实、最具场景特异性的天然数据集。完全可以做一件事:从这些记忆里,把常用的、反复出现的、可复用的操作,抽取成 Skill。更妙的是,它还可以边用边进化——因为你在使用 Agent 的时候,就是在往记忆里写,记忆会更新,这些更新的记忆就能用来自动进化这个 Skill。
顺着这个技术缺口,在开发 MemSearch 时,实现了一个碘伏传统开发范式的动态闭环:Memory-to-Skill。这里想提一点:这个想法虽好,但真做起来还是有不少落地细节。最关键的是:自动抽出来的 Skill 不一定靠谱,需要人来 review、微调。所以设计上拆成了两步。
第一步,自动蒸馏候选。让 Agent 从记忆日记里找出那些反复出现、值得沉淀的操作,抽成候选 Skill,放进一个专门的候选目录里。这一步是后台周期性自动跑的。而且,对于已经抽好的候选 Skill,如果后面的对话里又出现了相关操作的改动,后台会继续往前推一版。也就是说,候选区里的 Skill 是被持续蒸馏、持续演进的,而不是抽完就定死。
第二步,review 并安装。候选永远只是候选,是一份惰性的草稿,放在一个没有任何 Agent 会自动加载的目录里。这时候主动调出 memory-to-skill 这个 Skill,把候选拿出来人工 review 一下,提一些微调意见,最终固化、安装到指定位置,装好就能直接用。
这里刻意守住一条边界:机器只负责提议,人来负责拍板。一条记错的笔记顶多没用,但一个被装上、会自动触发的错误 Skill,是会主动帮倒忙的。而且,有时对模型的反馈仅仅基于单次任务,并不需要模型在所有场景都使用这个经验。所以激活这个动作,必须由人来做。
这套机制对 Claude Code、Codex 等各种 Agent 都适配。你可以指定安装路径,比如装到全局,也可以只装到某个项目,甚至一次装到多个目录、同时覆盖好几个 Agent。
举个真实例子。在开发 MemSearch 的过程中,需要反复发版,每次都得跟 Agent 说一堆类似的话,让它一步步把发版流程走完。自从用上它之后,它就能自动判断出这套操作完全可以抽成 Skill,并整理好,取名 release-memsearch。
将抽出来的版本一装,后续再遇到类似的发版,只要敲 /release-memsearch 几个字,就能直接调用它,完全不用再重复解释那一长串 prompt。那一刻你会真切地感觉到:你做过的事,Agent 替你记住了,还顺手把它变成了你的能力。这是一种高阶的自举(Bootstrap)。交互产生记忆,记忆蒸馏出技能,技能提升下一次交互的效率,而技能本身又在新的记忆中迭代升级。自产自销,无缝闭环。
这套机制已经在 MemSearch 里实现好了。
第 4.5 层:记忆之上,还缺一层 harness
把记忆的四层逻辑全部理通后,站在更高的维度审视,你会发现记忆依然不是终局。对话是记忆,知识库是记忆,Skill 也是记忆。但 Agent 在真实生产环境中要面对的上下文,还包括散落在各处的高壁垒数据:本地的代码仓库、最新的设计文档、Slack 和飞书里的非结构化聊天、Jira 上的 Issue。从广义上讲,这些全都是人类团队在协作中沉淀下来的集体记忆。对 Agent 而言,最痛苦的不是没有这些数据,而是当面对一个具体任务时,在如此广袤且异构的上下文海洋里,哪一小片乐高积木才是此刻唯一需要的?
因此,需要在所有这些零散的记忆与数据源之上,架构一层统一的上下文控制台(Context Harness)。这正是最近正在密集筹备的全新项目 MFS 试图填补的拼图。
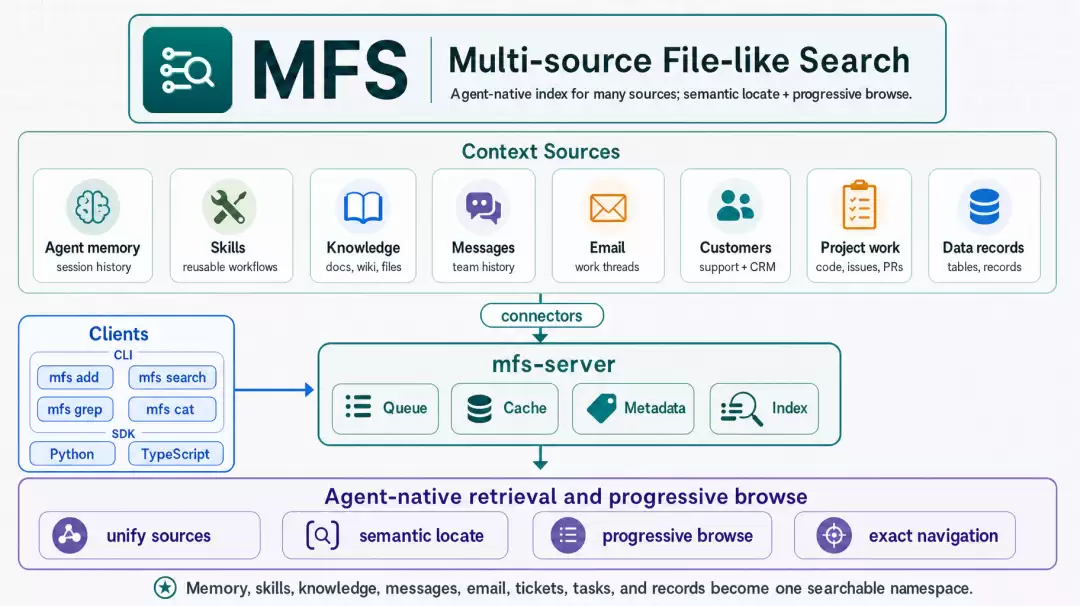
MFS 将代码库、社交软件、历史记忆全部抽象为挂载在统一虚拟路径下的类文件树(File-like Tree)。它只通过两个核心 Skill 驱动 Agent:一个负责动态连接与挂载源,另一个负责跨源的联合检索和渐进式发现。以往,当你想排查系统的失败重试机制到底是怎么设计的,你需要在 IDE 里翻看重试逻辑代码,去 Slack 里搜索半年前技术方案评审时的激烈讨论,还要去翻找自己上个月踩坑时的对话记忆。而在 MFS 的调度下,Agent 能够一句话横跨代码、聊天记录与主观记忆,将这三片散落在不同时空的乐高积木精准地捞出来,严丝合缝地拼在你面前。记忆至此不再是一座孤岛,而是完美融入了统一的上下文图谱中。
这个项目已经在预热了。等正式发布,会再单独写一篇详细聊。
可以看到,记忆走到这一层,就不再是独立系统,而是这张统一上下文大图里的一块。说到底,这是为了让 Agent 和人类的记忆能更好地打通。
写在最后
其实记忆这个场景,一直都还在演进的路上。或许在不久的将来,随着 Loop Engineering(循环工程)等新范式的注入,我们会看到第五层甚至第六层的风光,眼下那些自觉精妙的架构,在未来的全量实时训练或新型硬件面前,可能也会变成阶段性的遗迹。但抛开这些未竟的构想,记忆这件事越往下挖,底层逻辑其实不是一个孤立的功能——它是把 Skill、知识、上下文乃至 Agent 自身的进化全都串起来的那条线。对应人类社会,无非是用最真诚、最没有偏见的自然语言,老老实实地记录下这里发生过什么、什么是真实的、以及一件事该怎么做。剩下的,就交给时间和一块块乐高慢慢去拼吧。
参考链接
- CoALA 论文,Cognitive Architectures for Language Agents:https://arxiv.org/abs/2309.02427
- LangChain 博客,Memory for Agents:https://www.langchain.com/blog/memory-for-agents
- MemSearch(跨平台的 Agent 记忆,含 memory-to-skill):https://github.com/zilliztech/memsearch
- MFS(Agent 的统一上下文 harness):https://github.com/zilliztech/mfs
