
基于Dify和Deepseek打造智能文章改写工具:提取写作风格实现精准改写
先说个现实问题:市面上大多数AI改写工具,底层跑的都是GPT-4o、Claude 3.5这类模型。它们确实能改写文章,但问题也很明显——想要写出质量在线的内容,你得喂进去一大堆提示词,反复调教。这门槛,对普通用户来说,着实不低。
但Deepseek这类新一代推理模型的到来,打破了这种局面。它不需要那么多思维链来引导,在理解甚至模仿写作风格这件事上,表现相当惊艳。这就引出了一个很自然的问题:能不能把“风格提取”这件事彻底交给模型?用户只管给出喜欢的文章链接,剩下的大模型来搞定?
核心思路很简单:
提取B文章的写作风格,直接应用到对A文章的改写上
基于这个想法,我在Dify平台上用Deepseek搭建了一个智能改写工作流。它的特点在于:只需要少量、精准的提示词,就能让模型理解并迁移写作风格,实现高质量的改写。
为什么非要做这样一个风格提取的工作流?
市面上的改写工具太“死”了。用户要告诉它一段提示词,它才生成你想要的内容。但问题的核心在于,大部分用户根本不知道提示词怎么写。作为使用者,真实诉求非常简单:我看到了一个喜欢的文章风格,我想把它套到我需要改写的文章上。仅此而已。分析、写作,都该是模型做的事。
这个工作流就是为了解决这个痛点。
设计思路
传统的长篇累牍式提示词,不仅效率低下,还会束缚模型的创造力。实践表明,要让Deepseek这类推理模型发挥出真正的实力,提示词必须精炼。为此,我设计了一个四阶段分析框架,包含四个关键环节:
文章分析
风格解析
内容重构
质量检查
把复杂任务拆得越细,输出就越能沿着期望的方向走。工作流的几个步骤具体如下:
1、
内容抓取
2、
文章分析
3、
写作风格特征
4、
改写文章
5、
质量检查
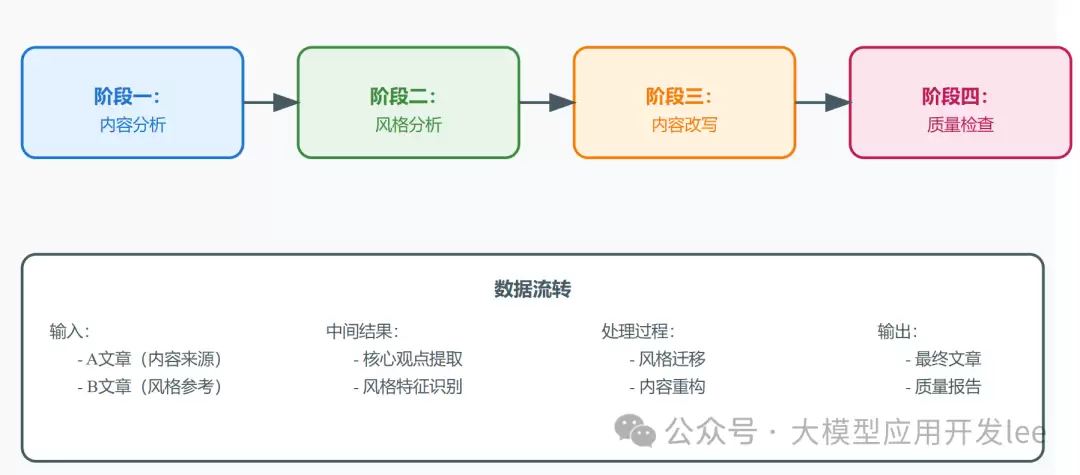
下图是整个工作流的完整图示:
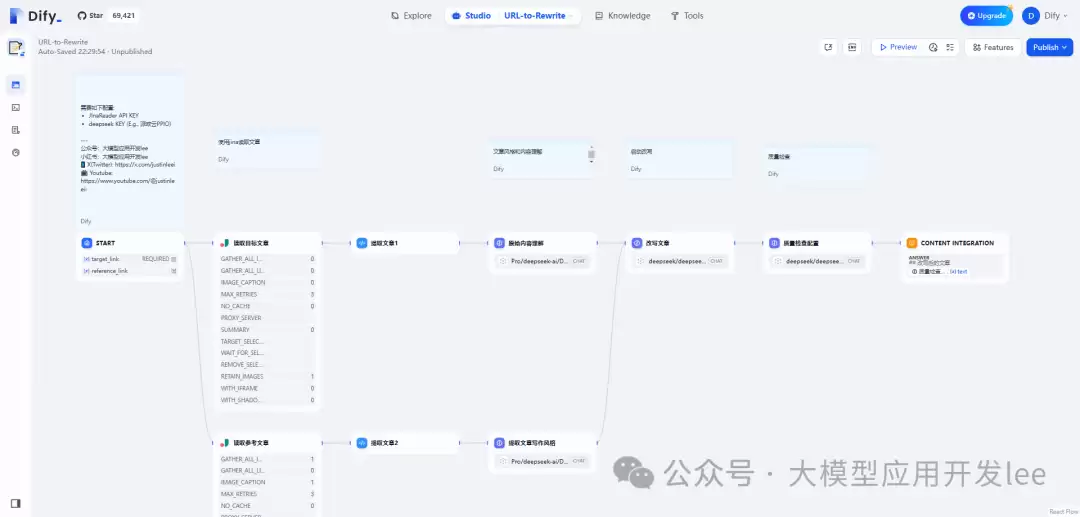
实战步骤
前置工作
1、准备Deepseek的API Key
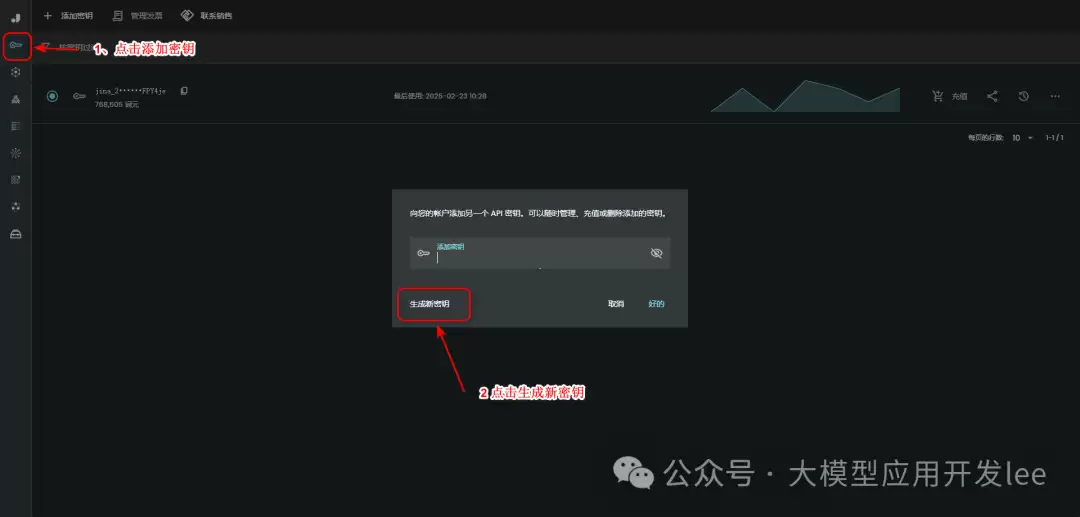
2、准备Jina的API Key
Jina用于提取URL的内容。进入 https://jina.ai 首页,登录后新建密钥,后续工作流中会用到它。
如何搭建这样一个工作流?
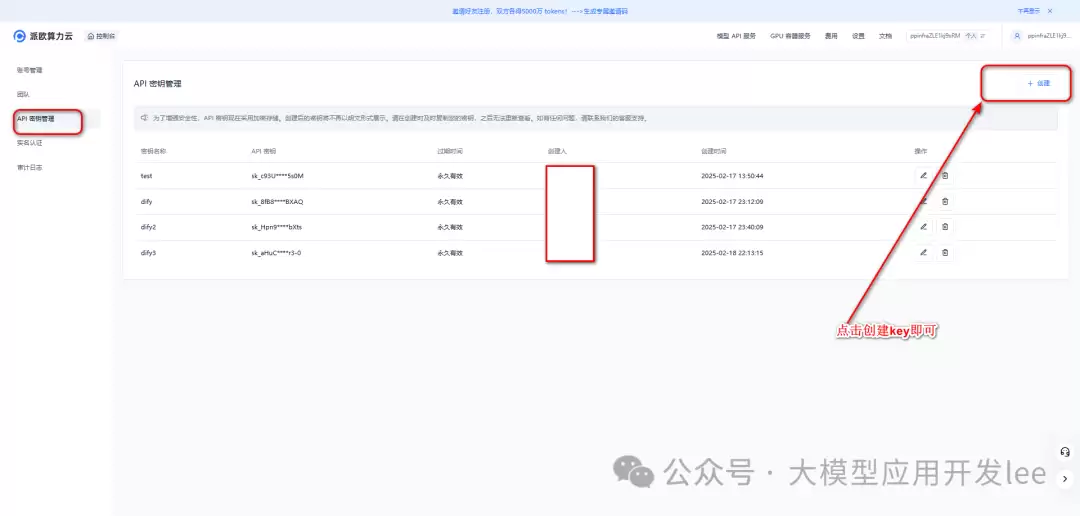
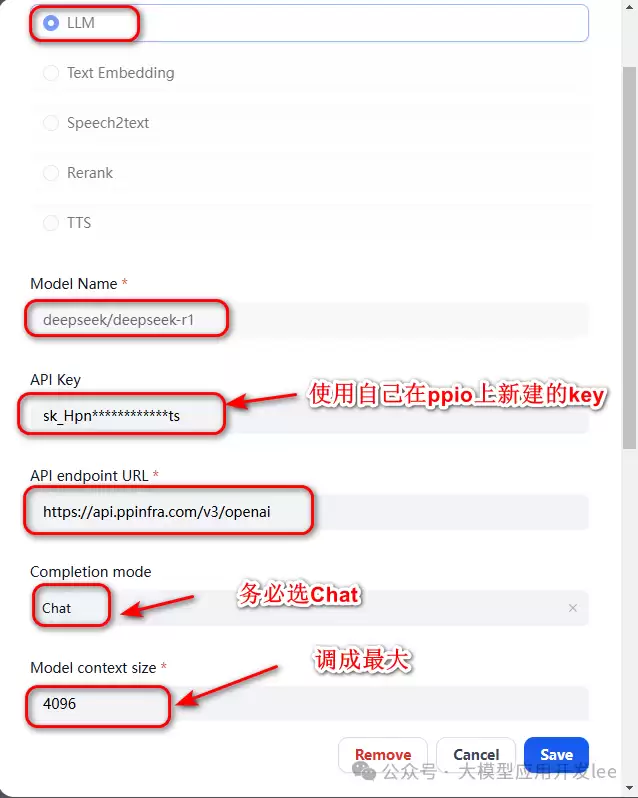
1、首先在Dify中配置Deepseek的Key。注册后,到 https://ppinfra.com/settings/key-management 新建一个Key。
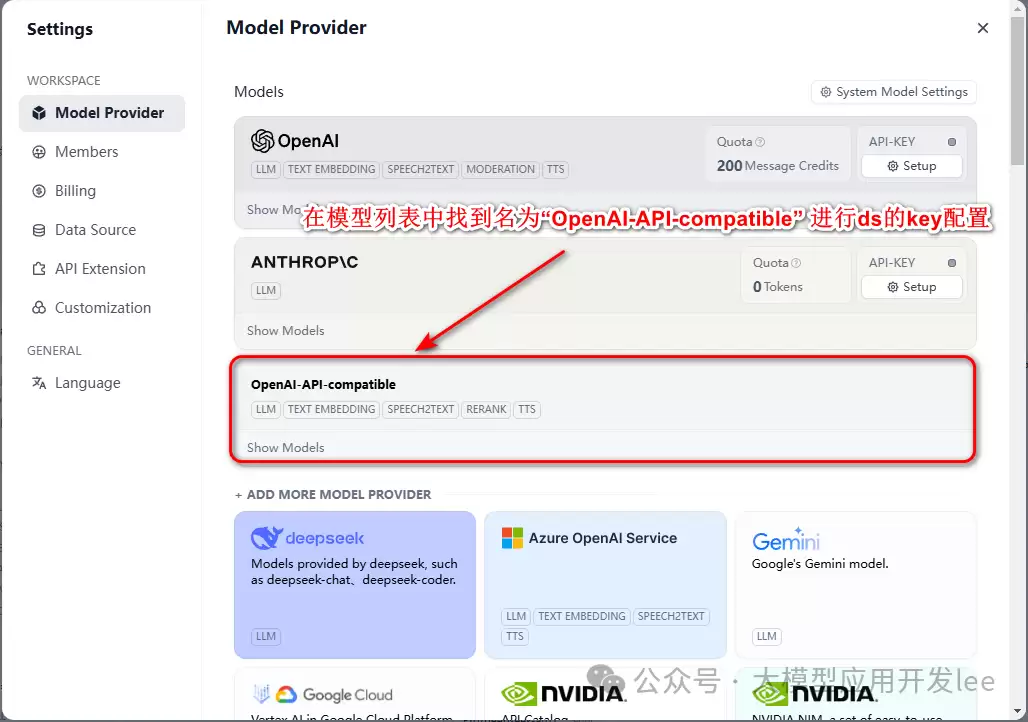
2、接着在Dify中配置上一步获取的Key。在Model Provider中找到【OpenAI-API-compatible】这一项进行配置。
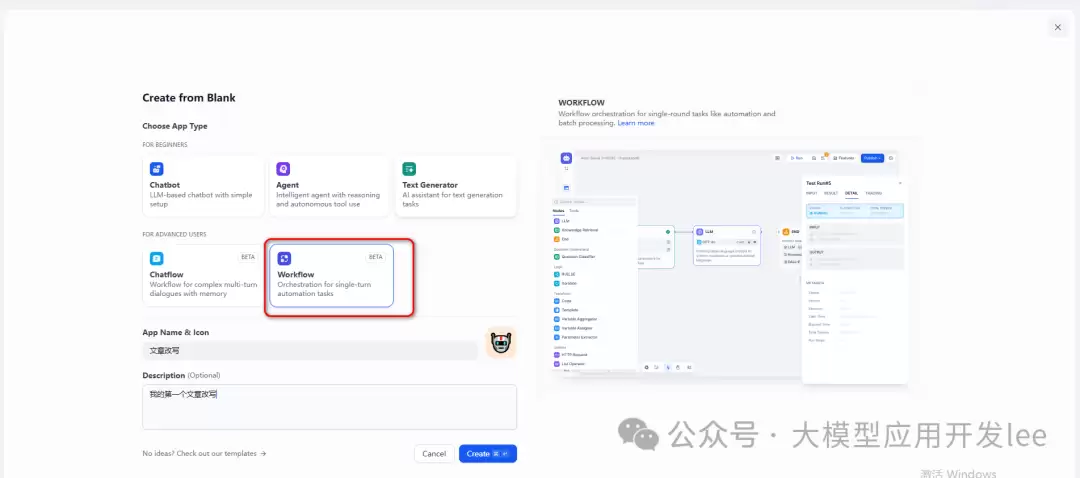
3、然后,一步步使用Dify的Block来实现工作流。首先点击【Create from Blank】创建一个新白板。
4、打开白板后,点击【START】,配置输入变量。本例中需要两个变量:目标文章的URL和参考文章的URL。

5、接下来,需要从URL中提取文章内容,用Jina来完成。在【+】号处新增Block,搜索“
Jina
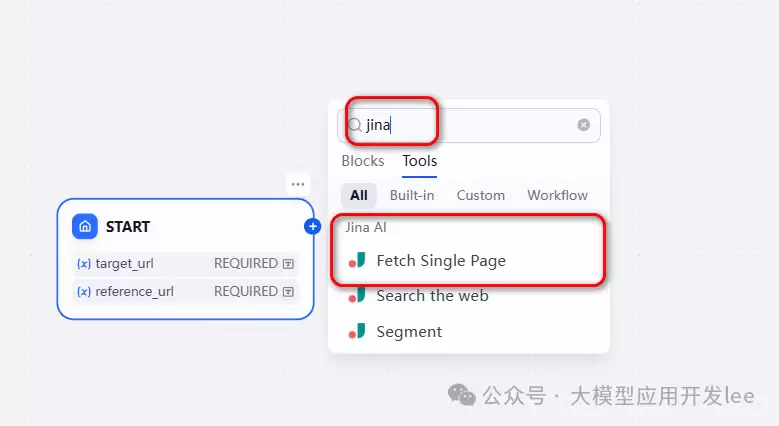 并行获取的好处是不必一个个串行处理,节省时间。
并行获取的好处是不必一个个串行处理,节省时间。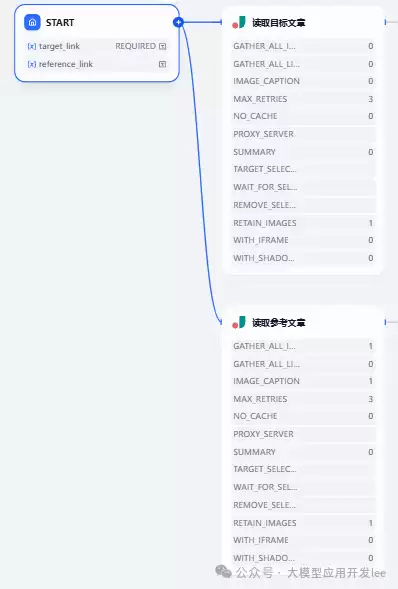
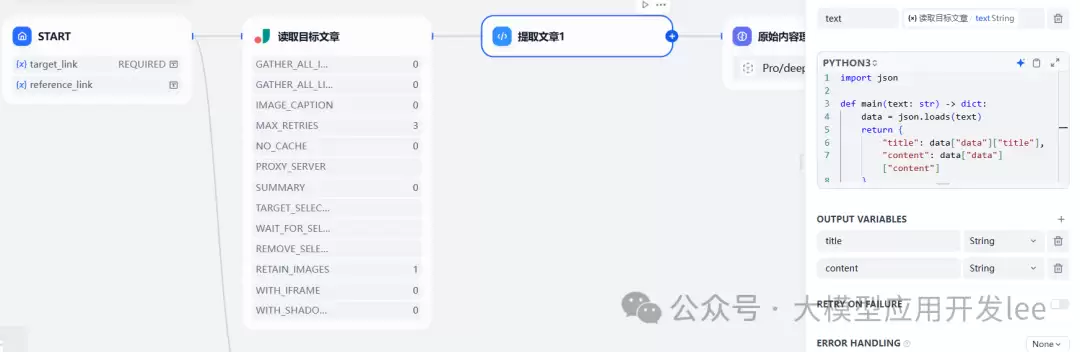
6、接着,对Jina返回的内容做进一步处理。这里用到【Code】模块。本例中,只需要获取标题(title)和内容(content),所以将返回的字符串解析并提取目标值。代码如下:
import json
def main(text: str) -> dict:
data = json.loads(text)
return {
"title": data["data"]["title"],
"content": data["data"]["content"]
}
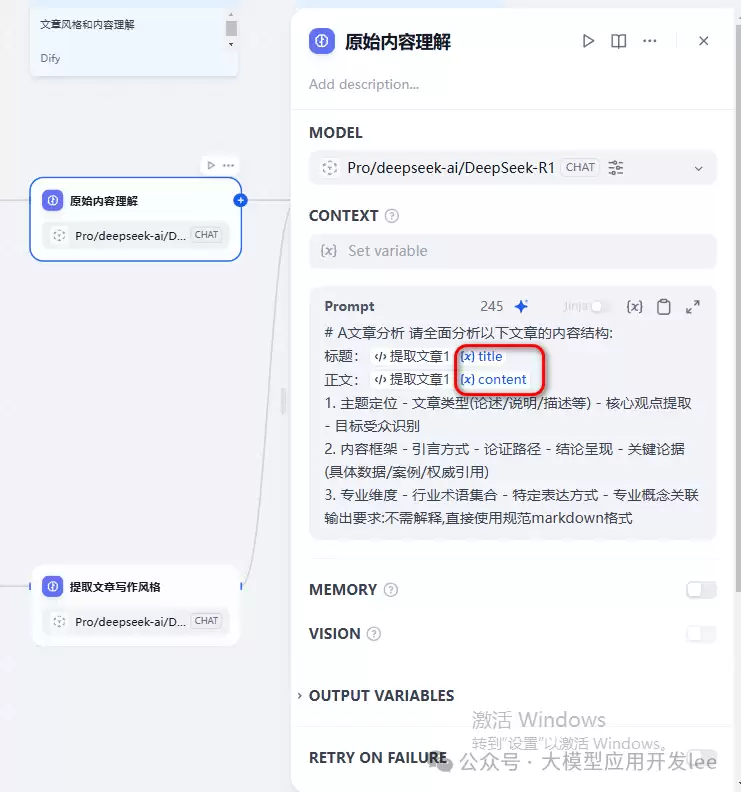
7、现在增加【LLM】Block,用来
分析目标文章内容
参考文章风格
斜线(/)
8、进行
文章改写
质量检查
9、使用【Answer】模块将结果输出,同样引用前一步的结果。
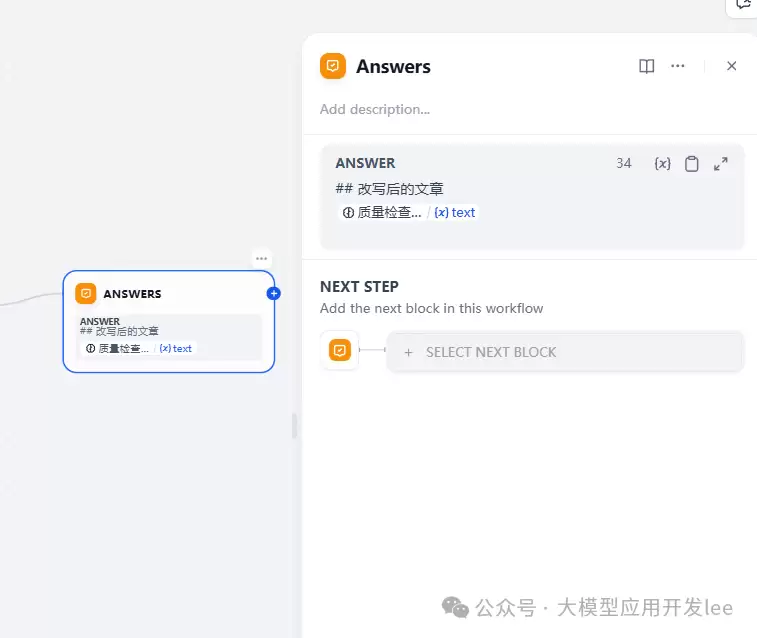
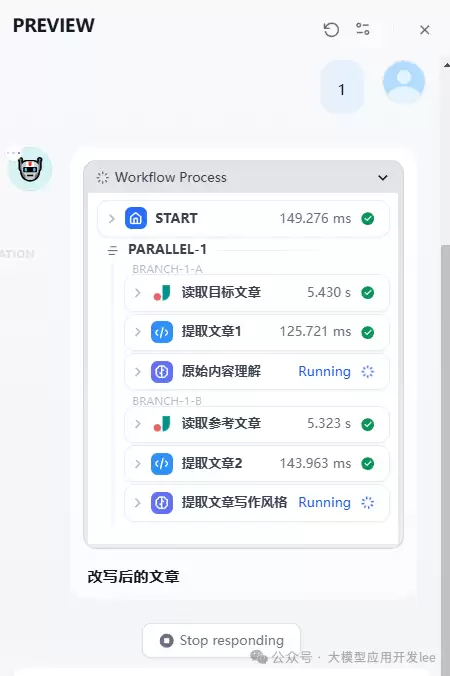
下面是整个流程的输出效果。可以清晰地看到每一步的输出情况,便于修改和调试。
总结
本文介绍了如何利用Dify和Deepseek构建一个文章改写工作流。在前置准备工作中,需要先在PPIO平台获取Deepseek的API Key,并在Dify平台完成模型配置。工作流搭建从创建空白工作流开始,配置文章URL作为输入变量,接着用Jina模块并行提取文章内容,然后通过Code模块处理提取的内容,获取标题和正文。之后配置LLM模块分析原文内容和参考文章风格,设置文章改写和质量检查环节,最后通过Answer模块输出结果。整个工作流采用并行处理提高效率,模块化设计便于调试和维护,结果展示清晰明了,同时提供灵活的Prompt配置以支持个性化需求。通过这个工作流,可以高效地完成文章改写任务,同时保持输出质量的一致性。
参考资料
Dify 官方文档[1] - 全面的Dify平台开发指南。
ppio文档[2] - PPIO Key的获取方法。
注:本文相关技术和工具信息更新于2025年2月,具体功能和特性请以官方文档为准。
