
0.6B VLM重塑AI修图推理流程,支持手机端侧部署,vivo+浙大出品
如今手机拍照已成日常,但想修出一张好照片,往往比拍下它更费功夫。专业工具门槛高,一键滤镜又太死板,现有的AI修图方案要么操作流程割裂,要么模型太大跑不动移动端。最近,
vivo BlueImage Lab、浙江大学计算机学院AiXM实验室、之江实验室和中国科学院大学
VeraRetouch
简单说,这是一个面向多任务推理式影调和色彩修图的轻量框架,全可微分,还支持手机端部署。核心思路是让0.6B的视觉语言模型充当“修图大脑”,再配上一个全可微分的Retouch Renderer作为“修图执行器”,从而把高层语言意图精准转化成像素级调整。效果嘛,既保留图像细节,又完成专业级色调与色彩优化。

让大模型真正“会修图”,而不只是会说怎么修
传统自动修图方法大多像个黑盒:照片丢进去,结果吐出来,中间缺少审美分析和调整逻辑。后来出现的推理式修图方法引入了多模态大模型,让模型先分析问题、给出修图步骤,再调用外部工具执行。这条路更接近人类修图师的工作方式,但有个核心瓶颈——外部修图软件通常不可微分。模型生成的参数到底能不能带来更好的像素结果?很难通过端到端训练直接优化。
VeraRetouch的关键创新就在这里:它不再把专业修图工具当成外部黑盒,而是
用一个全可微分的Retouch Renderer替代了传统调色与调光操作
研究团队把修图空间拆成三个相对独立的控制维度:
- Lighting:曝光、阴影、高光等光照相关调整
- Global Color:色温、色调、整体颜色倾向等全局色彩调整
- Specific Color:针对红色、橙色、蓝色等特定颜色通道的精细调整
这种拆解方式与专业修图流程高度一致,也让模型输出更可解释、更稳定。
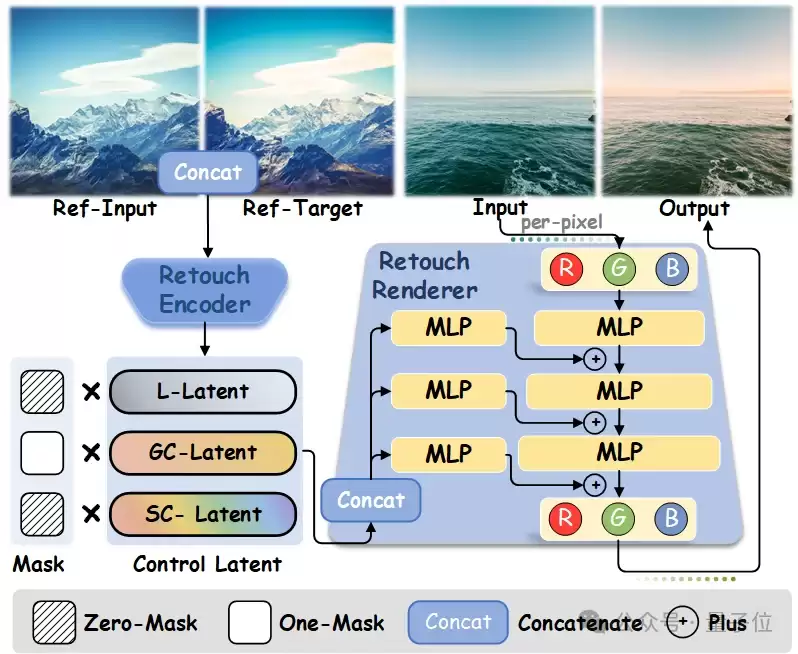 △Retouch Encoder从参考图像对中提取光照、全局色彩和特定色彩控制latent,Retouch Renderer再将这些控制信号映射到像素级修图结果
△Retouch Encoder从参考图像对中提取光照、全局色彩和特定色彩控制latent,Retouch Renderer再将这些控制信号映射到像素级修图结果
三种任务:从“一键变好看”到“按你说的修”
VeraRetouch面向真实用户需求定义了三类修图任务。
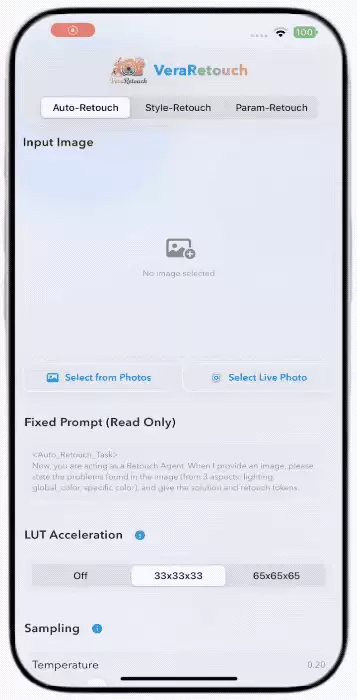
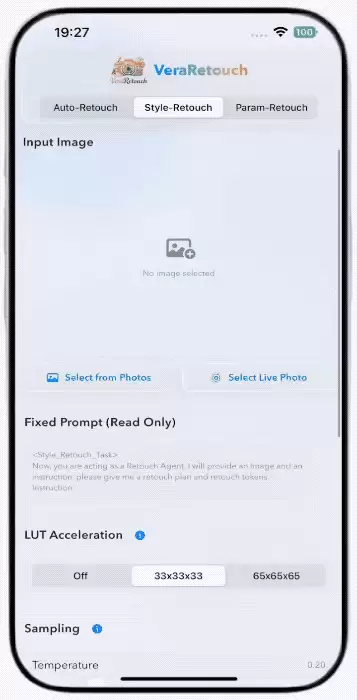
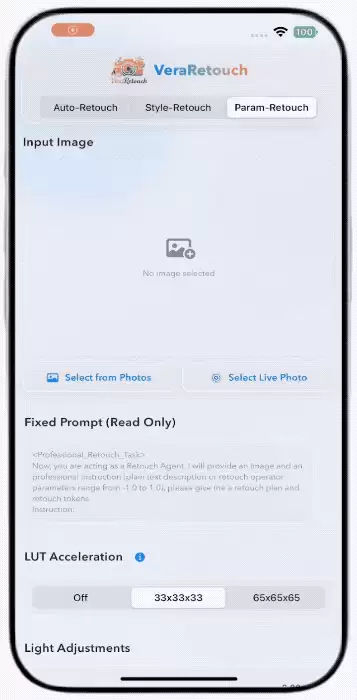
△VeraRetouch支持自动修图、风格修图与参数修图三类典型工作流,让用户可以快速从“这张图需要怎么修”理解到“模型正在做什么”。
第一类是Auto-Retouch。用户只需输入一张照片,模型自动分析光影和色彩问题,生成修图方案。这不是套滤镜,而是在保留原图内容的基础上提升整体观感。
第二类是
Style-Retouch
第三类是
Param-Retouch
数据问题怎么解决?构建百万级专业修图数据集
高质量修图模型离不开高质量数据。但专业修图数据非常稀缺,已有数据集规模有限,很难覆盖真实用户复杂多样的风格需求。为此,研究团队构建了
AetherRetouch-1M+
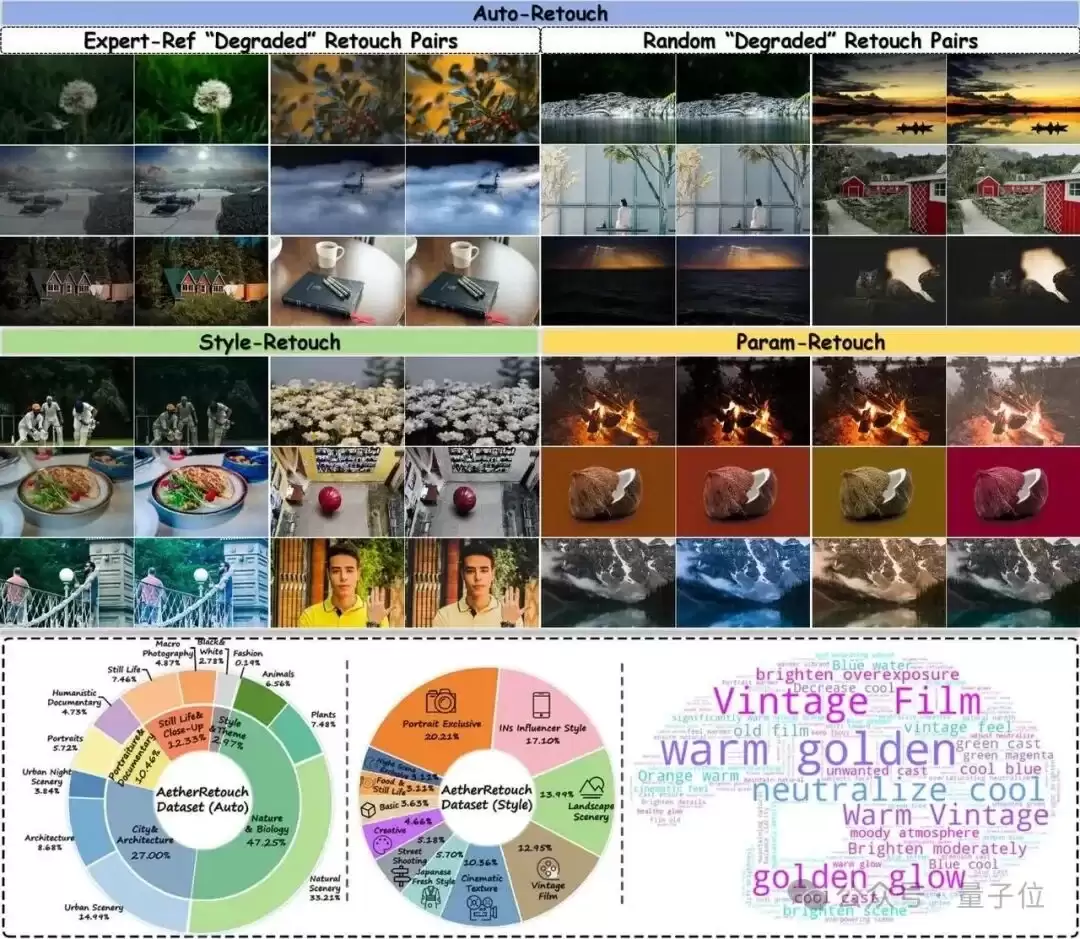 △AetherRetouch-1M+ 覆盖自动修图、风格修图与参数修图三类任务,为多任务推理式修图提供大规模训练数据
△AetherRetouch-1M+ 覆盖自动修图、风格修图与参数修图三类任务,为多任务推理式修图提供大规模训练数据
对于自动修图,团队采用了一个很有意思的“反向退化”思路:先从高质量照片出发,把它们视作“已修好”的结果,再基于专家修图对中的色彩与光照变化,反向生成更像原始照片的“未修图”版本。这样可以在保留真实内容结构的同时,构造大量具有真实缺陷的训练样本。
对于风格修图,团队整理了5030个在线风格预设,覆盖11个大类和193个细分子类,并借助视觉语言模型为图像匹配合适风格,再生成多样化用户指令。对于参数修图,团队围绕光照、全局色彩和特定色彩三类操作随机采样参数组合,生成可用于精确控制训练的数据。
更进一步,数据集中还加入了结构化推理过程:模型不仅学习“输入到输出”,还学习为什么要这样调整——包括画面内容分析、原图问题诊断,以及对应的修图计划。
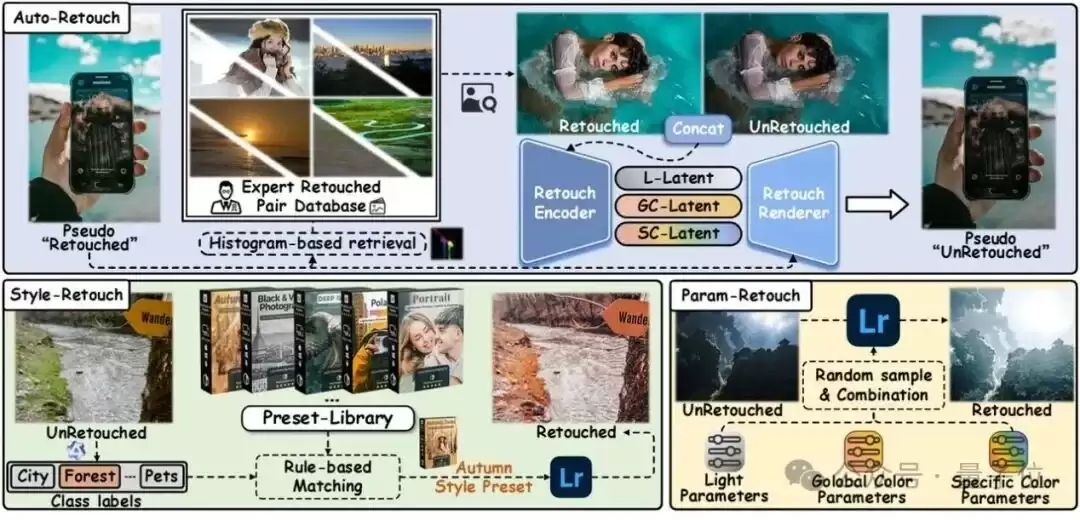 △AetherRetouch-1M+的数据构建流程,包括自动修图的反向退化、风格预设匹配与参数采样三条数据生成路径
△AetherRetouch-1M+的数据构建流程,包括自动修图的反向退化、风格预设匹配与参数采样三条数据生成路径
技术核心:小模型,也能做专业推理修图
VeraRetouch基于FastVLM-0.5B构建。输入图像经过视觉编码器转成视觉token,用户指令经过文本编码器转成prompt token,随后多模态语言模型生成结构化推理内容。
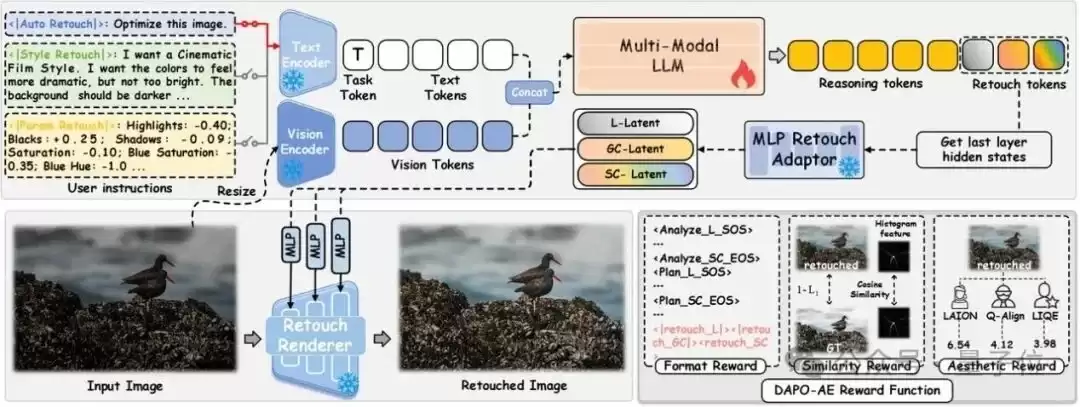 △VeraRetouch整体框架。输入图像与用户指令经过轻量VLM生成结构化推理与控制latent,再由Retouch Renderer输出最终修图结果
△VeraRetouch整体框架。输入图像与用户指令经过轻量VLM生成结构化推理与控制latent,再由Retouch Renderer输出最终修图结果
为了让推理结果真正驱动像素调整,研究团队设计了专门的retouch tokens,分别对应光照、全局色彩和特定色彩三个控制维度。模型最后一层hidden state会被送入MLP Retouch Adaptor,对齐到Retouch Renderer可理解的连续控制latent,再由Retouch Renderer输出最终修图结果。
这套设计带来两个重要优势。首先,它
避免了模型推理时对外部修图软件的依赖
比大型生成式图像编辑模型更轻量
为了进一步提升审美表现,团队还提出了DAPO-AE后训练策略,通过格式奖励、图像相似性奖励和审美奖励,引导模型在保持指令一致性的同时生成更自然、更符合人类美学偏好的修图结果。
实验结果:质量、速度和可部署性同时提升
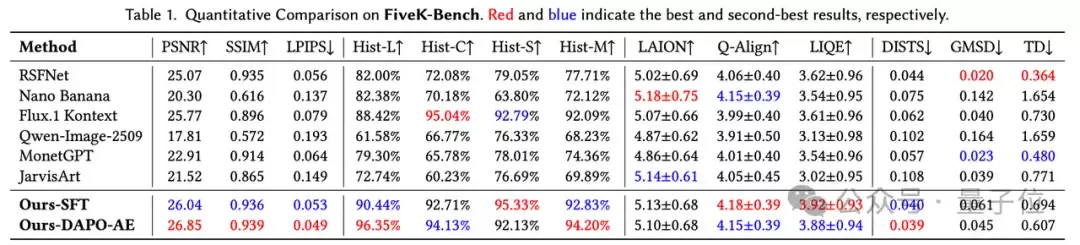
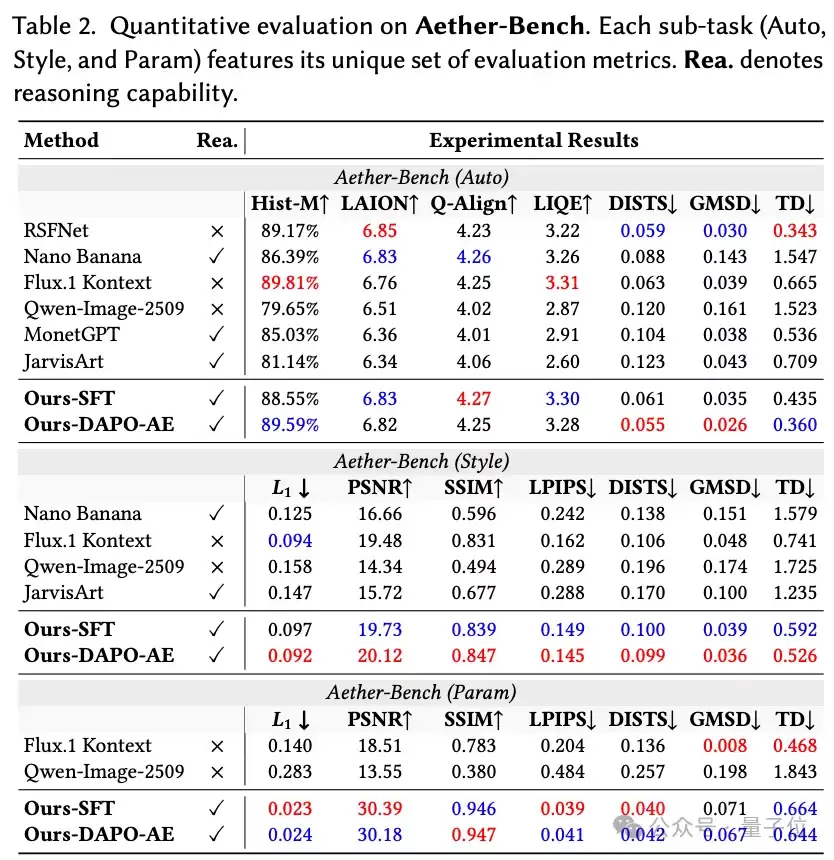
实验显示,VeraRetouch在多个基准上取得了领先表现。在FiveK-Bench自动修图任务上,VeraRetouch-DAPO-AE达到26.85 dB PSNR,相比Flux.1 Kontext提升1.08 dB,同时在SSIM、LPIPS和多项直方图一致性指标上表现突出。
在Aether-Bench的风格修图任务中,VeraRetouch在PSNR、SSIM、LPIPS、DISTS、GMSD和Texture Distortion等指标上均取得最优或领先表现,说明它不仅能跟随风格指令,也能更好地保留原图结构与纹理细节。在参数修图任务中,VeraRetouch的PSNR达到30.18 dB,明显超过微调后的扩散模型基线,展现出对精确修图参数的强执行能力。不过论文也指出,由于构造训练数据时采用联合高斯分布进行参数采样,模型在执行分布外参数时可能会出现一些不一致的情况。
从三个任务视频可以看到,VeraRetouch的修图结果并不是简单改变整体滤镜强度,而是会根据任务类型分别处理画面亮度、色彩倾向、局部颜色与风格氛围。自动修图更强调自然观感;风格修图更关注语言描述与视觉风格的一致性;参数修图则强调调整结果的可控性和可复现性。
速度方面,VeraRetouch在H20 GPU上处理一张512p图像仅需6.90秒,快于Flux.1 Kontext的16.78秒和JarvisArt的14.31秒。更重要的是,模型在消费级设备上也具备部署潜力:未经量化的版本在MacBook Air M4上约7.46秒,在iPhone 16 Pro上约13.56秒即可完成自动修图。
用户研究同样验证了这一点。38名参与者的盲评结果显示,VeraRetouch在视觉美感、指令一致性和纹理保持方面都获得了最高评分。DAPO-AE后训练也带来更明显的人类偏好提升,在对比实验中获得61.62%的偏好率。
当然,论文也指出当前模型在局部修图能力上仍有提升空间。未来若进一步引入像素级mask机制,VeraRetouch有望支持更灵活的区域化编辑——比如只提亮人物面部、只调整天空色彩,或只优化背景氛围。
关于作者
vivo BlueImage Lab是蓝图影像创新实验室,主要负责移动影像算法创新,包括图像/视频处理、图像/视频交互、图像/视频增强、多模态理解大模型等方面的技术前沿探索。致力于不断提升vivo移动影像的算法能力,使用户能够拍摄出更加清晰、美观的照片和视频,同时积极探索增强现实、具身智能等新兴技术领域的应用。
论文链接:https://arxiv.org/pdf/2604.27375
项目主页:https://apollo-yi.github.io/VeraRetouch/
代码链接:https://github.com/OpenVeraTeam/VeraRetouch

