
如何用大模型+向量数据库,帮你搞定出行规划与旅游blog
在Zilliz近期举办的柏林非结构化数据Meetup上,来自海外旅游规划平台GetYourGuide的机器学习工程师Meghna Satish,分享了一套很有意思的实践——如何用LLM搭配向量数据库,来改善客户体验,重塑旅游服务,顺便解决大模型幻觉这个顽疾。这种思路对很多做内容或者做客服的团队来说,都挺有参考价值的。
01. GYG如何使用LLM改善服务
1.1 内容翻译和本地化
GYG最早把LLM用在内容翻译和本地化上。原因很直接:LLM能打破语言壁垒,实时把景点介绍、酒店描述、用户评论这些旅行信息翻成各种语言,让不同地区的用户都能用自己的母语看懂。他们主力用的是ChatGPT,大部分情况下,翻译质量不错,能和品牌调性保持一致。
不过,ChatGPT的训练数据来源大约50%是英语、6%是西班牙语、32%是欧洲语、18%是亚洲语言。这种分布本身就会带来偏见。为了对抗这个偏见,也为了确保翻译准确,GYG并没有完全依赖ChatGPT,而是把它和其他深度学习神经网络结合起来做后期编辑——说白了,就是让机器翻完,再让另一套模型做精细化调校,这样既能保证速度,又能做到更有文化敏感性的本地化。
1.2 内容生成和客户支持
旅游行业“内容为王”,GYG当然也不会放过自动化的机会。他们用LLM来辅助内容创作,比如自动生成景点介绍、目的地指南甚至旅游博客。这些内容都不是人工从头写的,而是通过LLM做自动化产出。
除了创作,客服环节也用上了LLM。基于LLM的客服系统能自动处理FAQ和多轮对话,精准回答海量用户提问。这样一来,专业的客服人员就能把精力集中在那些真正复杂、需要人工介入的案例上,运营成本也顺便降下来了。
1.3 未来可能性:个性化推荐
虽然GYG目前还没有落地这部分,但LLM在个性化推荐上的潜力是巨大的。通过分析用户的搜索历史、预订模式和交互偏好,LLM可以给每个人定制行程、活动推荐,甚至生成符合其旅行兴趣的专属折扣。这种想象空间,确实挺让人期待的。
02. GYG使用LLM的挑战
话又说回来,LLM(尤其是ChatGPT)在实际应用中并非一帆风顺。GYG在做本地化内容后期编辑时就遇到了几个棘手的挑战:
- :如果查询相关的信息不在训练数据里,ChatGPT可能会“脑补”出一些不存在的细节。比如翻译时,它可能会凭空捏造出原文里根本没有的人名、地点或事件。更麻烦的是,它有时候更倾向于回答问题,而不是老老实实执行翻译任务——这会直接导致内容跑偏。
幻觉问题
- :ChatGPT偶尔会在输出中添加原始提示里没有的字符或信息,导致回答和预期目的不搭边。这种“偏离”会破坏输出的可控性,往往需要人工二次检查。
提示偏离
- :LLM有时候很难始终扮演好分配的角色。一旦提示稍微偏离预期的语气或内容,它可能会反过来对任务本身“评论”几句,而不是严格遵守指令——这种情形尤其在需要一致性的任务(比如翻译)里让人头疼。
角色一致性
为了应对这些挑战,自然需要人工监督来保证准确性和相关性。但问题在于,人工干预只适合中小规模的应用。如果系统每天要服务几十万用户,纯靠人工监督显然不现实。
于是,检索增强生成(RAG)就成了一个很自然的解决方案——通过给LLM提供外部数据源,既能缓解幻觉,又能填补知识空白,减少人工介入的依赖。
03. 检索增强生成(RAG)减少LLM幻觉
RAG可以说是解决LLM幻觉的标杆方案,尤其是当我们需要查询模型训练数据之外的特定知识时。举个简单的例子:如果向LLM询问企业内部的专有数据,它多半会给出不准确的回答。而RAG通过先检索相关上下文,再把它喂给LLM,就能让模型回答得更靠谱。
一套标准的RAG设置会结合LLM(比如ChatGPT)、向量数据库(比如Milvus或其托管版本Zilliz Cloud)以及Embedding模型。如果还想玩得更高级,可以集成LlamaIndex、LangChain、DSPy、reranker等工具,这些工具分别在检索、重排或者特定任务上做了优化,最终输出的准确度和相关性也会更高。
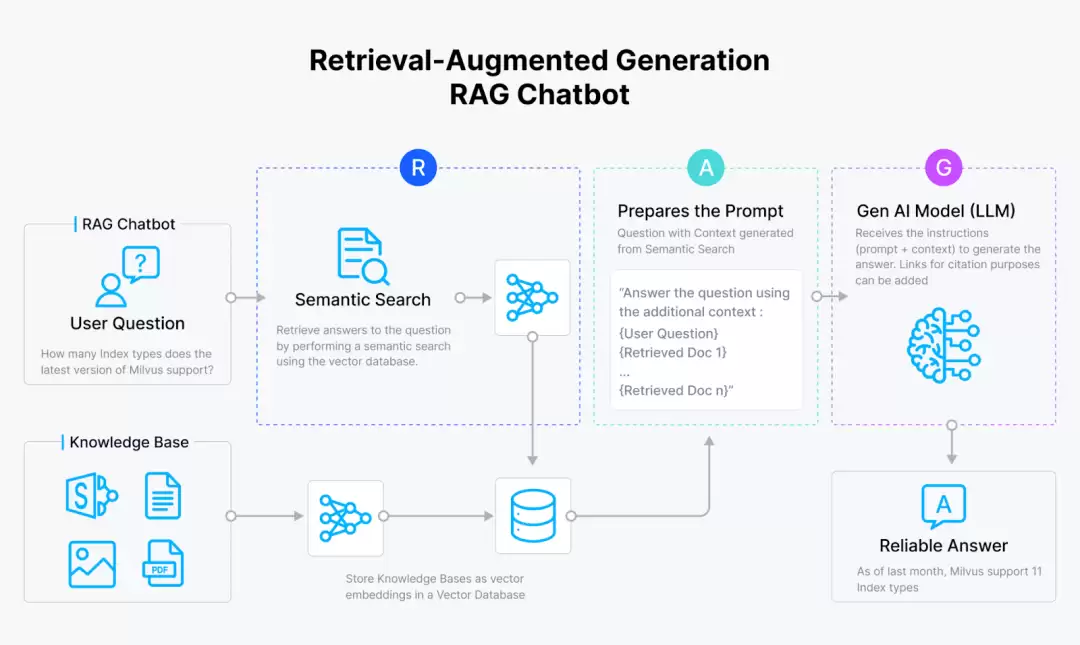
下面是一个典型的RAG工作流程:
- :用户的查询不会直接发给LLM,而是先通过Embedding模型,把查询和外部知识源分别编码成向量嵌入。
向量化
- :这些向量嵌入被存储到像Milvus或Zilliz Cloud这样的向量数据库里,这些数据库擅长管理大规模向量化数据,能实现快速检索。
向量存储
- :向量数据库执行相似性搜索,找出与用户查询在语义和上下文上最匹配的前k个结果。
向量相似性搜索
- :向量搜索出来的最优匹配结果,和原始查询一起输入给LLM。这样LLM就拥有了相关且较新的信息,有助于减少幻觉,提升答案的准确性。
将上下文传递给LLM
- :LLM结合自身的预训练知识以及检索到的上下文,生成更准确、更明智的回答。
生成最终响应
这套机制让LLM能有效处理那些复杂或比较特定的问题,即使它本身缺乏关于该主题的直接训练数据。
04. RAG与微调模型
RAG和微调这两种方式,从不同角度改进了LLM的表现。RAG能实时从外部源获取最新、最相关的信息来丰富输出,非常适合信息频繁变动或者涉及面比较广的业务场景。这种方法不需要对模型做大量重新训练,就能保持相关性,同时成本也更低。
相比之下,微调是通过调整特定数据集的权重,来永久性地更新模型的知识。它很适合那些需要在稳定领域具备深厚专业知识(比如法律、医学)的应用,但资源消耗大,而且不太适应信息快速变化的情况。
说到底,RAG适合需要实时访问外部数据的、可扩展且适应性强的工作;微调则更适合需要嵌入深厚专业知识的专门应用。对很多实际案例来说,RAG的灵活性和性价比往往比传统微调更有吸引力。
不过,这两者并不是二选一的关系。完全可以相辅相成:比如先微调LLM,提高它对特定领域语言的理解,确保输出符合业务需求;同时再搭配RAG,提供从外部来源获取的最新且上下文恰当的信息,进一步提高响应的质量和相关性。这种组合策略能产生更强大、更有效的解决方案,同时满足通用和专业需求。
05. 总结
LLM正在给旅游业带来显著的变化,像GetYourGuide这样的公司,已经可以用它来提供更高效的客户体验。通过语言翻译、内容生成等场景,GYG增强了平台的用户互动,让服务变得更易触达。
ChatGPT和深度学习神经网络虽然对翻译之类的任务非常有效,但挑战也不小,尤其是幻觉问题。不过,通过RAG这种把向量数据库(比如Milvus)中的外部知识连接到LLM的方案,我们可以获得更准确的输出,有效缓解幻觉。这或许就是下一步行业落地的关键所在。
