
AI修炼记2-MCP
文章目录
- 一. 环境配置
- 二. MCP 简单介绍
-
- 1. MCP是什么?
- 2. 为什么要使用MCP?
- 3. MCP架构
- 4. MCP Ja va SDK 的传输方式
- 三. 第三方MCP服务器的引入与使用
- 1. cursor 调用MCP 流程
- 2. 使用 spring AI 调用流程
- (1) 添加依赖
- (2) 配置yml
- (3) 配置mcp-servers.json文件
- (4) 通过Http调用大模型
- (5) 调用效果图
- 四. 自定义MCP服务器端
- 1. 自定义stdio传输方式的mcp
- (1) 引入依赖与打包插件
- (2) 配置yml
- (3) 定义工具
- (4) 暴露工具, 交给Spring进行自动创建与注入
- (5) 进行打包
- (6) Spring AI 调用
- 2. 自定义sse传输方式的mcp
- (1) 引入依赖
- (2) 配置yml
- (3) 启动服务, 验证 mcp-sse 服务器是否能成功连接
- (4) Spring AI 调用
- 1. 自定义stdio传输方式的mcp
一. 环境配置
正式开始之前,先把环境搭好——这步虽然基础,但少踩一个坑后面就顺一大截。确保你的机器上已经装了 Ja va 17+、Node.js(用于 npx 调用)、Python 和 uvx(部分 MCP 服务器需要),IDE 推荐用 IntelliJ IDEA 或 VS Code,Cursor 用户可以直接跳到第三节。
二. MCP 简单介绍
1. MCP是什么?
MCP(模型上下文协议)是个开源标准,专门用来把 AI 应用跟外部系统连起来。你可以把它想象成 AI 应用的 USB-C 接口——USB-C 统一了电子设备的连接方式,MCP 则统一了 AI 调用外部工具、资源和提示词的方式。
说人话:就是把 AI 需要的 ToolCalling(工具)、资源、提示词按 MCP 协议封装好,对外暴露统一的接口,大模型那边也按这个协议随时调。不夸张地说,这就像是给 AI 配了个万能遥控器,一个协议管所有。
2. 为什么要使用MCP?
- :构建 AI 应用或智能体时,MCP 能大幅减少开发时间和复杂度。不用给每个 AI 单独写一遍插件,只写一个 MCP 服务器,所有 MCP 客户端都能直接用。一套功夫,到处都好使。
开发者
- :MCP 提供了对数据源、工具和应用生态的标准化访问,能力边界一下子扩宽了,最终用户体验自然更好。
AI 应用程序或智能体
- :MCP 催生出的 AI 应用更强大、更聪明,用起来省时省力。说白了,谁用谁知道。
用户
3. MCP架构
MCP 采用经典的客户端-服务端架构。MCP 宿主(比如 Claude Code、Claude Desktop 这类 AI 应用)会跟一个或多个 MCP 服务端建立连接。具体做法是:宿主为每个服务端创建一个 MCP 客户端,每个客户端跟自己的服务端保持一条专用的“通道”。
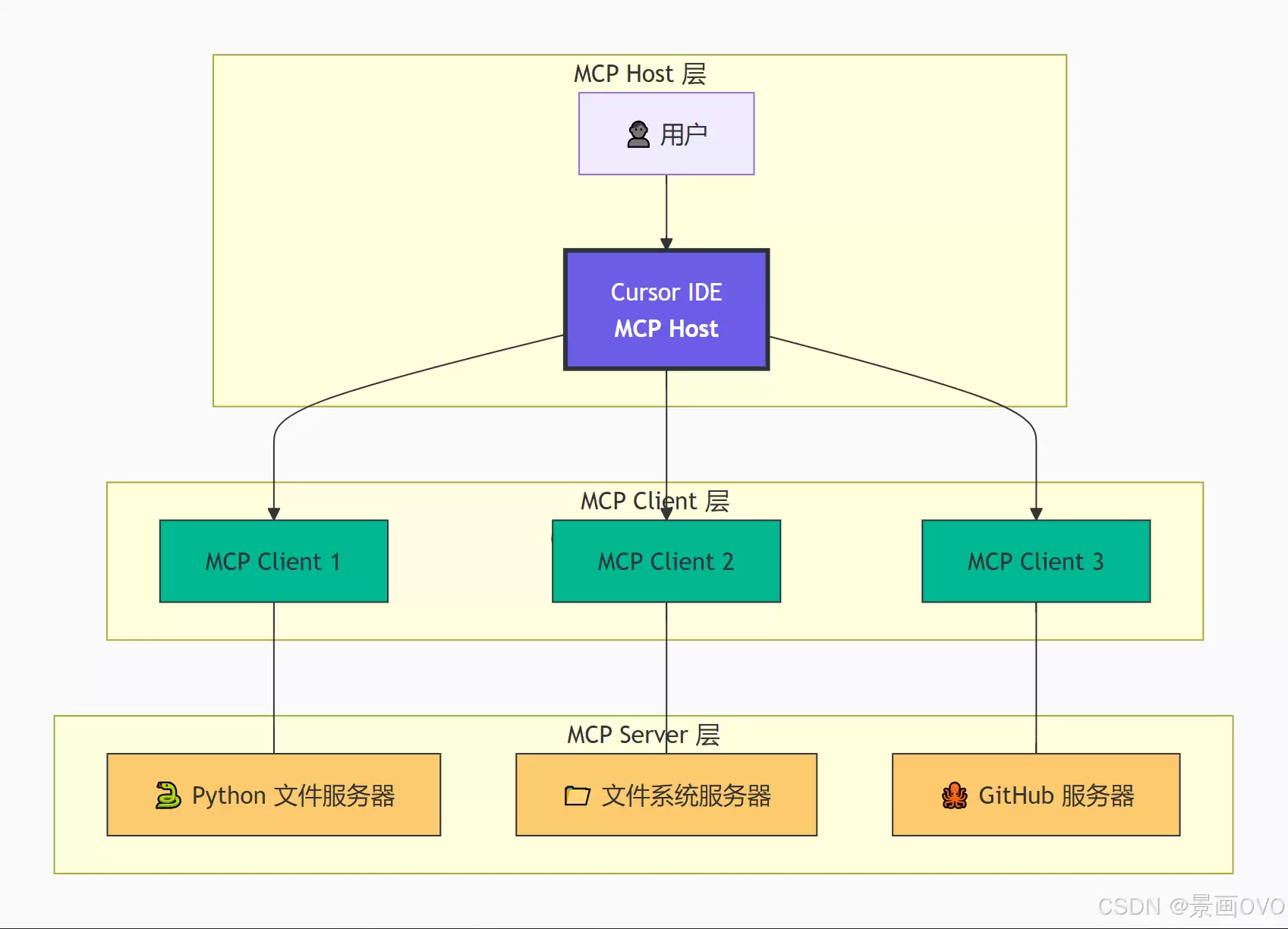
4. MCP Ja va SDK 的传输方式
Ja va SDK 里,客户端和服务器之间主要走这三种传输方式:
- :通过标准输入/输出在两个进程间通信,直接、高效,像两个人面对面传纸条。
Stdio
- :基于 Ja va HttpClient 发 HTTP 请求,同时接收服务端推送的事件流(SSE),适合需要实时回传的场景。
SSE
- :基于 WebFlux 的非阻塞响应式编程模型来处理 SSE,高并发场景下更丝滑。
WebFlux SSE
三. 第三方MCP服务器的引入与使用
前提条件:环境已经配好。第三方 MCP 大多依赖 npx 或 uvx 命令行工具来调用,所以 Node.js 和 Python 的安装不能跳过。
这里推荐几个好用的 MCP 社区,方便大家找现成的服务:
- —— 目前个人觉得最好用,社区活跃度也高。
MCP Flow
MCP.SO
MCP-server
1. cursor 调用MCP 流程
在 Cursor 中配置 MCP 服务器,只需在项目根目录下创建或编辑 .cursor/mcp.json(或直接在设置里配),参考下面示例:
{"mcpServers": {"Playwright": {"command": "npx -y @playwright/mcp@latest","env": {},"args": []},"fetch": {"command": "uvx","args": ["mcp-server-fetch"]}}}2. 使用 spring AI 调用流程
(1) 添加依赖
模型这边用的是 DashScopeModel(阿里百炼平台集成的),通过 Web 服务来调用模型。依赖清单如下:
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework
spring-webflux
com.alibaba.cloud.ai
spring-ai-alibaba-starter-dashscope
org.springframework.ai
spring-ai-starter-mcp-client
com.alibaba.cloud.ai
spring-ai-alibaba-bom
1.0.0.2
pom
import
(2) 配置yml
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
mcp:
client:
stdio:
servers-configuration: classpath:/mcp/mcp-servers.json
# 将所有mcp服务配置到本地的一个JSON文件中,更方便简洁
logging:
pattern:
console: '%d{HH:mm:ss.SSS} %c %M %L [%thread] %m%n'
file: '%d{HH:mm:ss.SSS} %c %M %L [%thread] %m%n'
level:
io.modelcontextprotocol.client: DEBUG
spec: DEBUG(3) 配置mcp-servers.json文件
把这个文件放在 resources/mcp/ 目录下:
{"mcpServers": {"playwright": {"command": "npx.cmd","args": ["@playwright/mcp@latest"]},"fetch": {"command": "uvx","args": ["mcp-server-fetch"]}}}(4) 通过Http调用大模型
写一个简单的 REST 控制器,把 MCP 工具注入到 ChatClient 里:
package com.ran.mcp.controller;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/chat")
public class ChatController {
private ChatClient chatClient;
// ToolCallbackProvider 把所有工具获取到
public ChatController(DashScopeChatModel chatModel,
ToolCallbackProvider toolCallbackProvider) {
this.chatClient = ChatClient.builder(chatModel)
.defaultToolCallbacks(toolCallbackProvider)
.build();
}
@RequestMapping("/generate")
public String generate(String msg) {
return chatClient.prompt()
.user(msg)
.call()
.content();
}
}(5) 调用效果图
跑起来之后,访问 http://localhost:8080/chat/generate?msg=帮我搜索一下最新的AI新闻,大模型会自动调用配置好的 MCP 工具(比如 fetch)来获取实时数据并返回结果。效果图这里省略,实际运行时可以看到流畅的对话流。
四. 自定义MCP服务器端
1. 自定义stdio传输方式的mcp
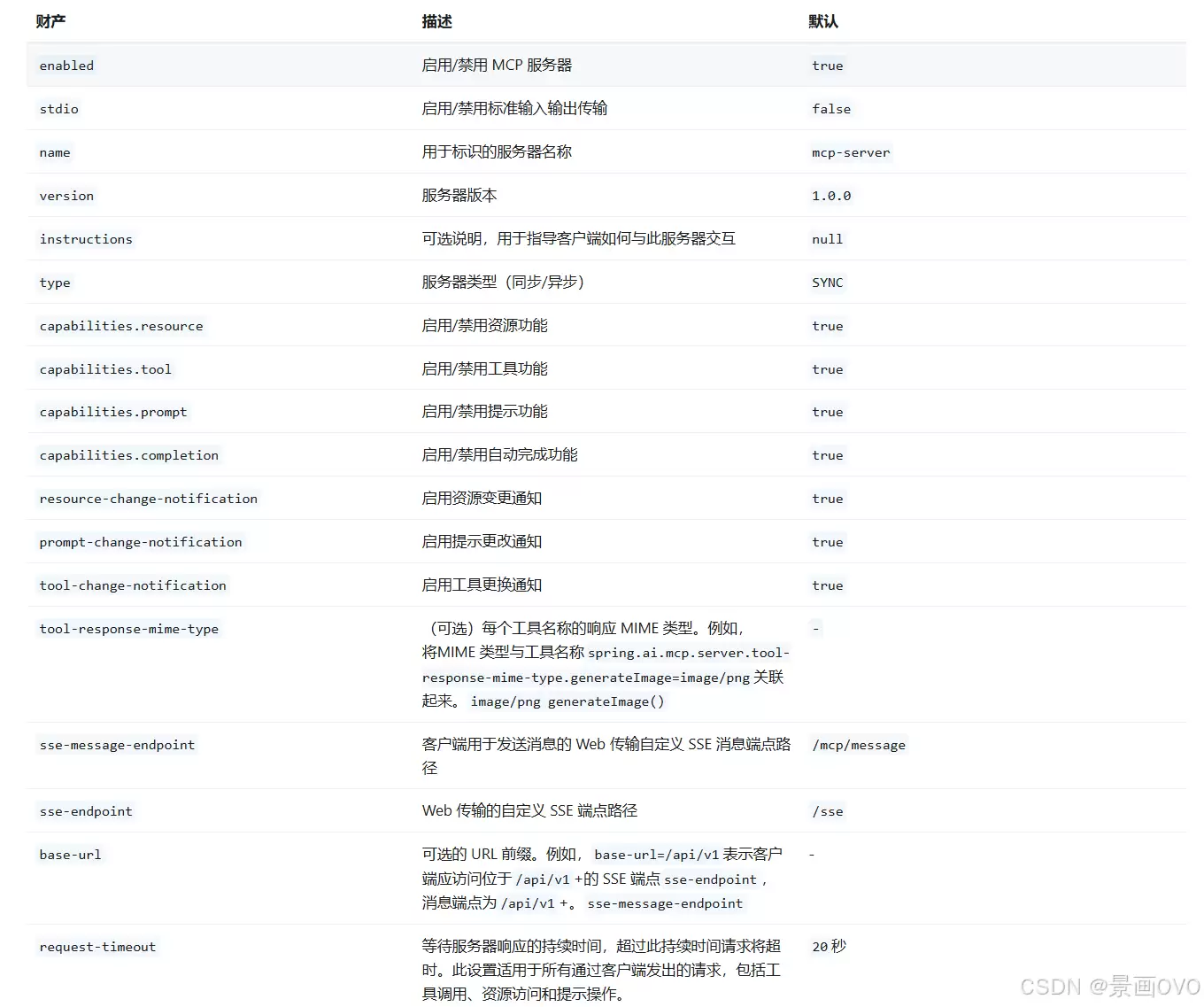
stdio 和 sse 方式的 MCP 服务器定义非常相似,差别主要在依赖和配置上。下面这张图标出了各个关键参数的含义:
(1) 引入依赖与打包插件
org.springframework.ai
spring-ai-starter-mcp-server
org.projectlombok
lombok
org.springframework.boot
spring-boot-ma ven-plugin
(2) 配置yml
对于 stdio 服务器,不需要 Web 容器,所以关掉嵌入式 Tomcat:
spring:
ai:
mcp:
server:
name: user-info
version: 0.0.1
main:
web-application-type: none
banner:
mode: off(3) 定义工具
写一个 Service,用 @Tool 注解暴露方法:
package com.ran.mcp.server;
import com.ran.mcp.entity.UserInfo;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Service;
import ja va.util.HashMap;
import ja va.util.Map;
@Service
public class UserService {
static Map userInfoMap = new HashMap<>();
static {
userInfoMap.put("zhangsan", new UserInfo("zhangsan", 12, "男"));
userInfoMap.put("wangwu", new UserInfo("wangwu", 18, "女"));
userInfoMap.put("lisi", new UserInfo("lisi", 17, "男"));
}
@Tool(description = "根据用户姓名, 返回用户详细信息")
public String getUserInfo(@ToolParam(description = "用户的姓名") String name) {
if (userInfoMap.containsKey(name)) {
return userInfoMap.get(name).toString();
}
return "用户不存在";
}
} (4) 暴露工具, 交给Spring进行自动创建与注入
@Configuration
public class ToolConfig {
@Bean
public ToolCallbackProvider getUserInfo(UserService userService) {
return MethodToolCallbackProvider.builder()
.toolObjects(userService)
.build();
}
}(5) 进行打包
执行 mvn clean package,得到 mcp-stdio-server-demo-1.0-SNAPSHOT.jar。之后通过 ja va -jar 在本地启动。
(6) Spring AI 调用
在客户端(Spring AI 应用)的 mcp-servers.json 里添加 stdio 配置,指向本地 jar 包:
"user-info": {
"command": "ja va",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dlogging.pattern.console=",
"-jar",
"D:/study/code/2025-ja va/Spring-AI-2/mcp-stdio-server-demo/target/mcp-stdio-server-demo-1.0-SNAPSHOT.jar"
]
}2. 自定义sse传输方式的mcp
(1) 引入依赖
切换为 SSE 传输时,需要引入 WebMVC 或 WebFlux 依赖:
org.springframework.ai
spring-ai-starter-mcp-server-webmvc
org.projectlombok
lombok
(2) 配置yml
server:
port: 8088
spring:
ai:
mcp:
server:
name: user-info
version: 0.0.1(3) 启动服务, 验证 mcp-sse 服务器是否能成功连接
启动后,访问 http://127.0.0.1:8088/sse 看看是否返回事件流。如果返回正常,说明 SSE 服务已经就绪。
(4) Spring AI 调用
在客户端的 application.yml 中配置 SSE 连接:
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
mcp:
client:
sse:
connections:
user-info:
url: "http://127.0.0.1:8088/sse"