
HCIE-AI:数据工程实验手册
1. 概述
这个实验的核心任务很简单:把一份开源的对话数据集(belle_chat_ramdon_10k.json)转换成 MindSpore 能高效读取的 MindRecord 格式。MindRecord 在训练大模型时能大幅提升数据加载效率,所以想用好 MindSpore,这步绕不开。
2. 实验目的
MindRecord 是 MindSpore 自带的“特供”数据格式,专门为高性能训练优化。通过这个实验,你会亲手走通从原始 JSON 到 MindRecord 的转换流程,知道背后的原理和必要的工具链。
3. 实验环境
3.1 登录并启动环境
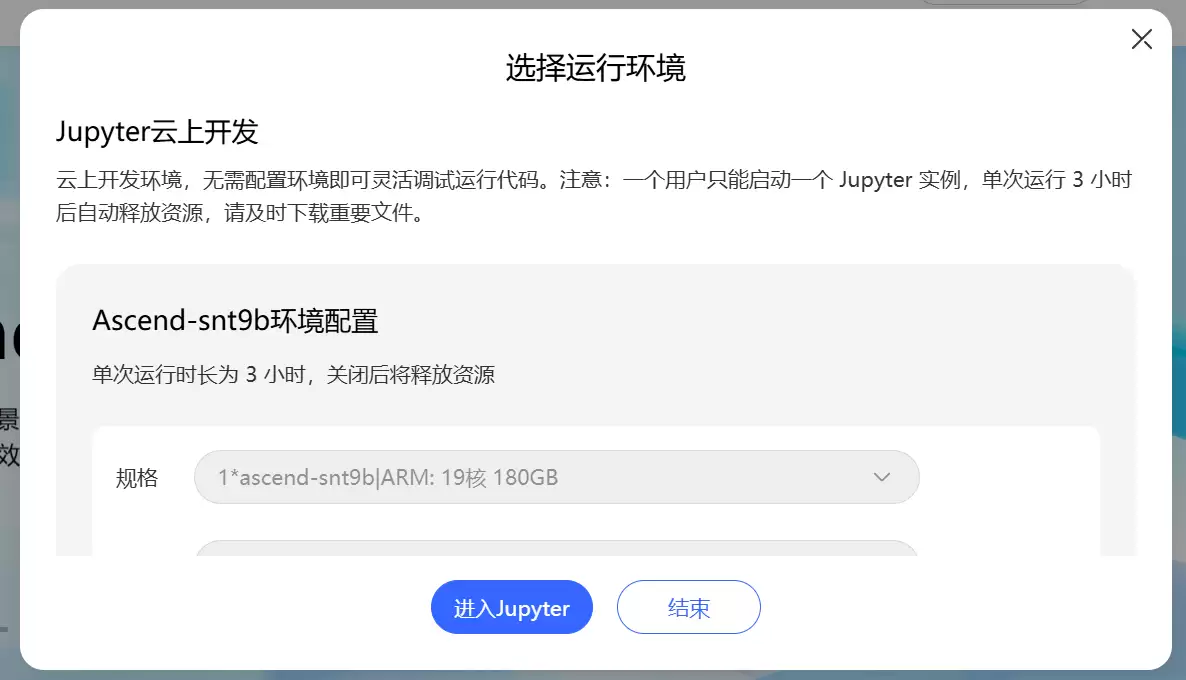
首先,打开 https://www.mindspore.cn/ 进入实训环境。

启动运行环境后,直接进入 Jupyter。注意,实验环境里已经预装了 CANN 组件,不需要你再手动装。
3.2 检验环境是否就绪
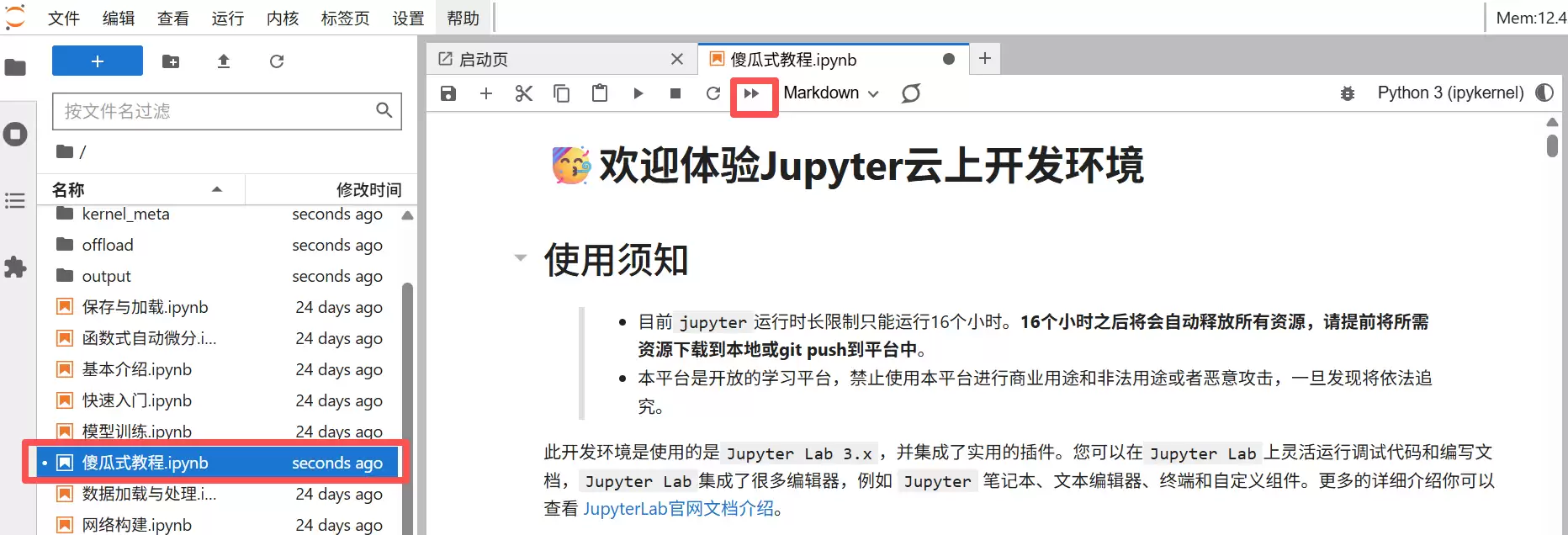
打开“傻瓜式教程.ipynb”文件,依次安装 MindSpore 和 MindFormers。跑一遍所有单元格,确保环境没毛病再继续。
4. 代码和数据准备
4.1 创建项目文件夹
先建一个干净的工作目录,后面所有的文件都放这里。
4.2 获取并解压代码包
运行下面这行命令,下载代码压缩包并解压:
wget https://certification-data.obs.cn-north-4.myhuaweicloud.com/CHS/HCIE-AI%20Solution%20Architect/mindformers.zip && unzip mindformers.zip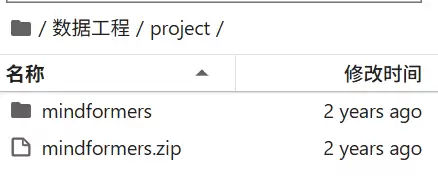
4.3 确认代码位置
解压后,相关脚本的路径如下图所示,建议先看一眼目录结构。

4.4 下载原始数据集
转换的原材料来自 Baichuan2 项目提供的一份开源对话数据:
wget https://raw.githubusercontent.com/baichuan-inc/Baichuan2/main/fine-tune/data/belle_chat_ramdon_10k.json
4.5 下载分词器
这里用的是 Baichuan2-7B 的 tokenizer.model,它决定了如何处理文本的切分:
wget https://hf-mirror.com/baichuan-inc/baichuan2-7B-Base/resolve/main/tokenizer.model?download=true -O "tokenizer.model"
5. 代码解析
6. 运行代码
所有材料准备妥当后,执行核心转换脚本。命令行参数说明:--input_glob 指定原始 JSON 文件,--model_file 指定分词器模型,--output_file 指定输出的 MindRecord 文件名及路径,--seq_length 表示序列最大长度,这里设为 4096。
python belle_preprocess.py --input_glob belle_chat_ramdon_10k.json --model_file tokenizer.model --output_file belle_chat_ramdon_10k_4096.mindrecord --seq_length 4096执行成功后,终端会打印类似下图的日志信息,同时生成对应的 .mindrecord 文件。

7. 总结
这个实验本质上就是为微调大模型准备数据——把开源对话数据转成 MindRecord 格式,方便后续训练时高效读取。它是整个训练流程的基础环节,实验考试中会占 10% 的分数。掌握好这一步,后续的微调就能跑得更顺。
