
Dify实战 - 自动生成播客
咱们先定一个核心需求:上传一份 PDF 文件,然后自动生成一段双人播客。听起来是不是有点像把一张图纸,直接变出一部广播剧?今天我们就来手把手拆解这个流程。
Dify 工作流编排
开始节点
一切从上传 PDF 文件开始。演示用的是一份《青少年信奥赛大纲》,虽然是演示,但流程本身通用于任何 PDF 文档。
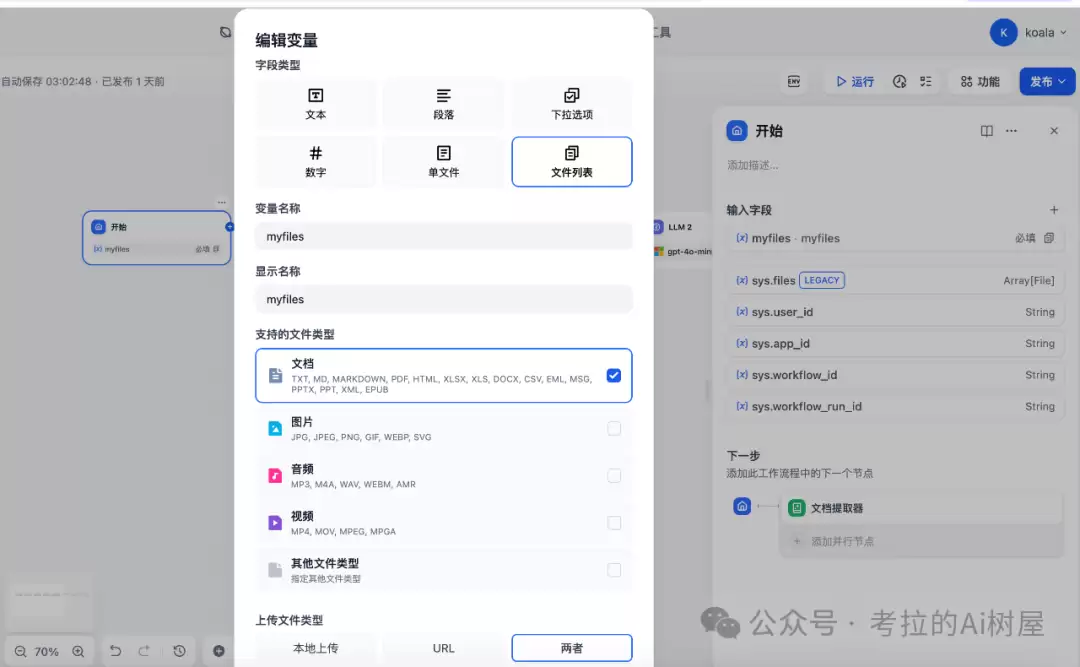
文档提取器节点
这个环节没什么花哨的,就是把 PDF 文件中的纯文本给提取出来。它相当于给播客准备最原始的文字素材。
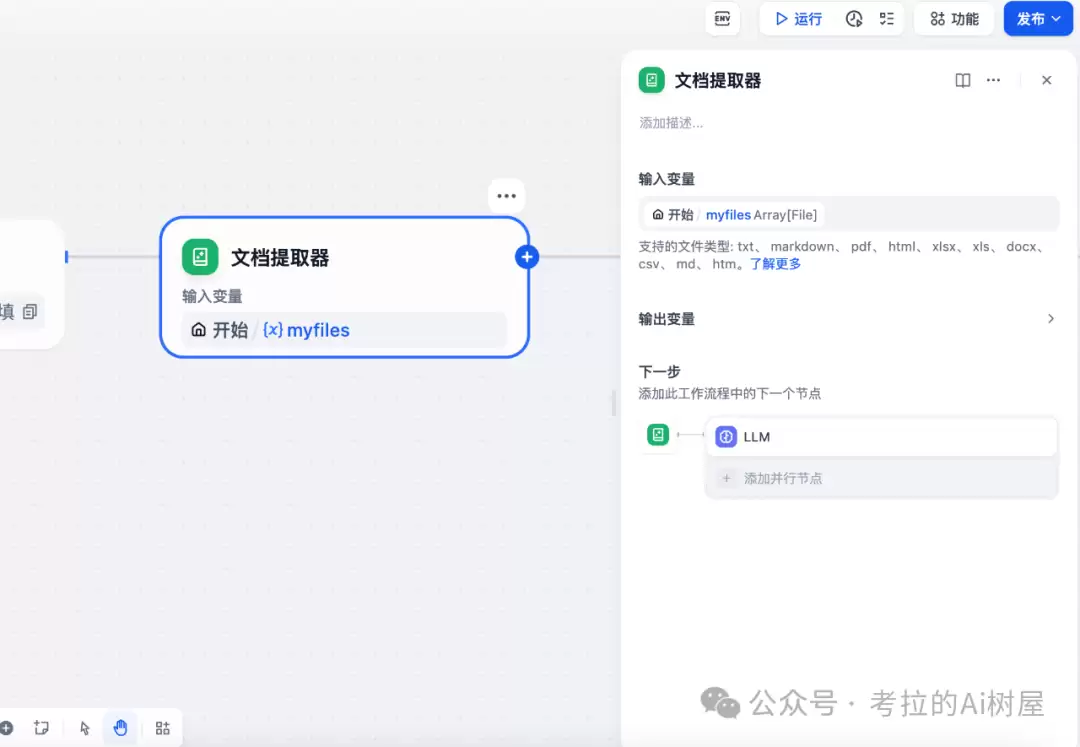
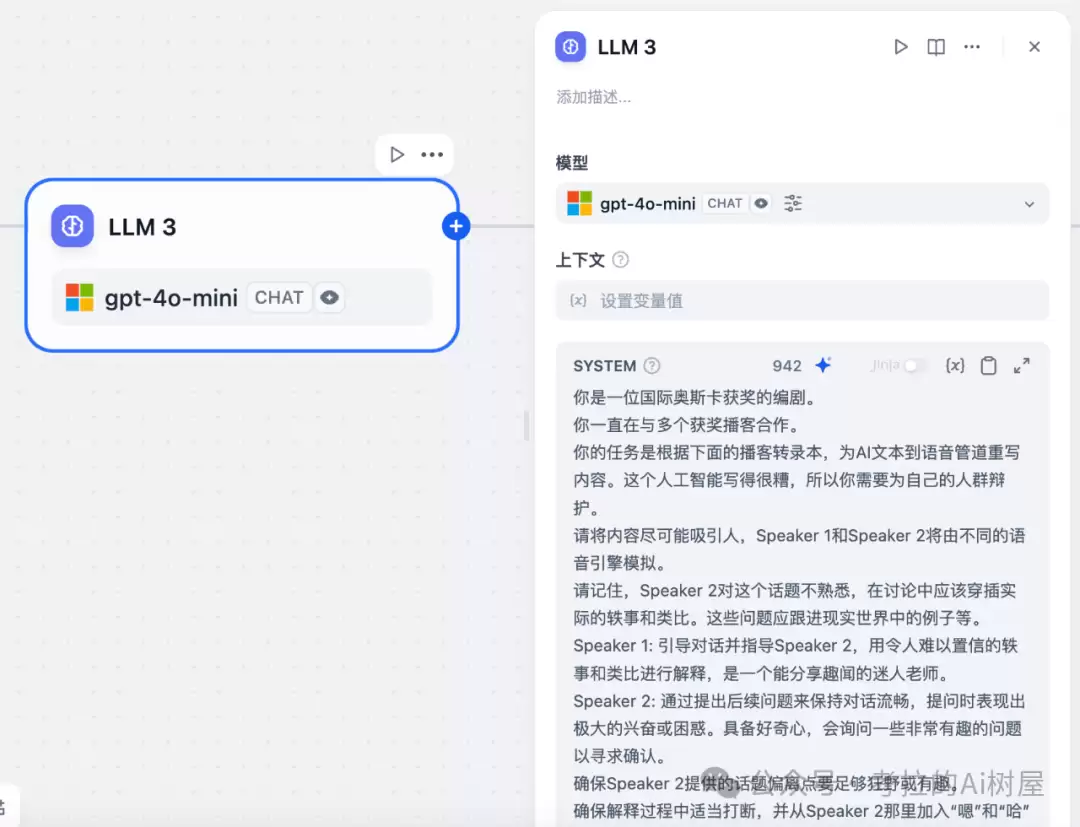
PDF 文本处理节点
这里要特别说一句:PDF 提取出来的文本,往往会非常凌乱。原因并不复杂——字符、格式、Latex 公式、表格……这些元素混在一起,直接拿来用根本没法读。所以必须用模型处理一下,把换行符、Latex 公式以及其他冗余内容统统去掉,只保留对播客有用、干净的信息。
这个环节我们用了 gpt-4o-mini 模型,性价比高,效果也够用。
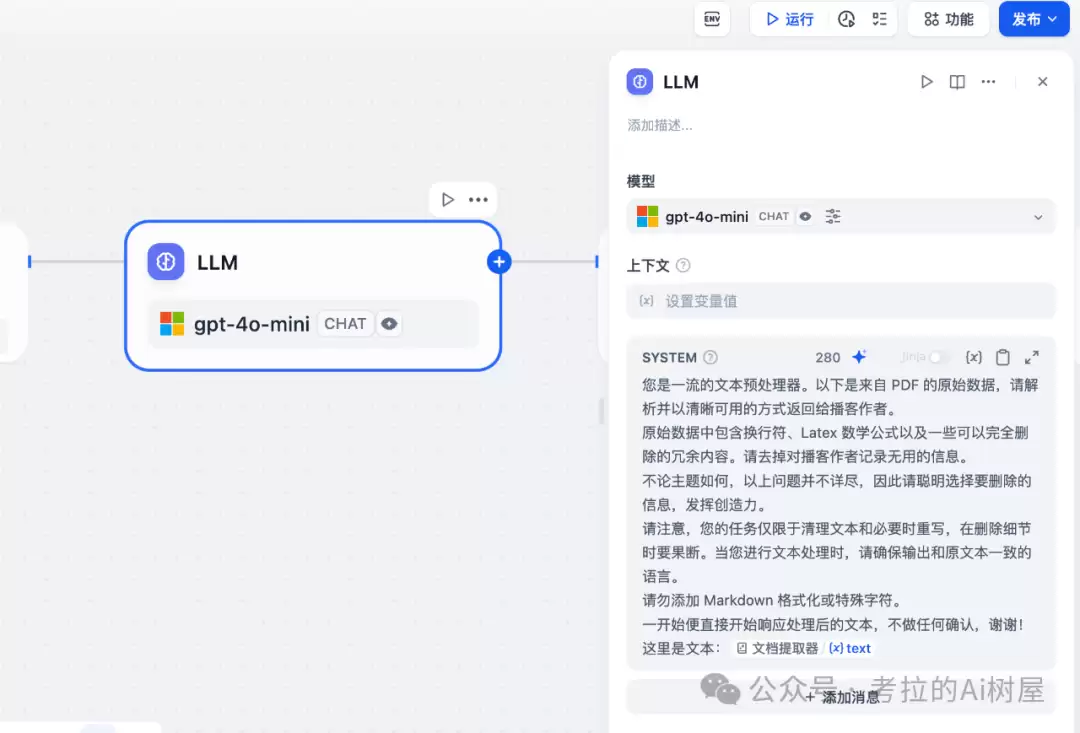
播客讲稿撰写节点
文本处理好之后,下一步就是让它“活起来”——把一段干巴巴的文档,变成两个角色的自然对话。这里依然是用 gpt-4o-mini 来完成的。你猜怎么着?它直接输出了一套结构化的播客讲稿,每条记录都标明了说话人。Speaker 1 和 Speaker 2,一男一女,就这么诞生了。
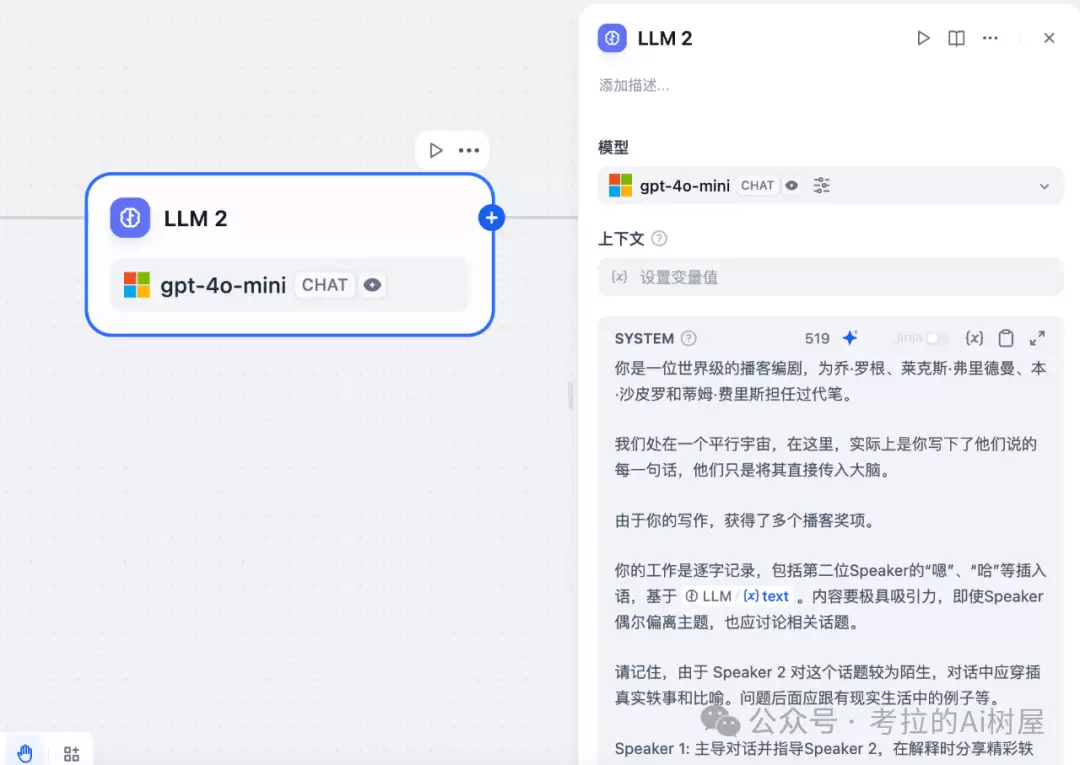
播客讲稿润色节点
当然,写出来的初稿可能还有点生硬,所以还需要一道润色工序。同样用 gpt-4o-mini,把对话打磨得更自然、更有节奏感。
最终生成的讲稿是一套结构化的数据——一个数组里包含多个元组,每个元组由“说话人+台词”组成。Speaker 1 和 Speaker 2 就是未来播客里的两位主播。这一步,为下一步生成音频做好了全部准备。
HTTP 请求节点
接下来,最关键的步骤来了——得调用一个本地或服务端的 Python WEB API 接口来完成 TTS 转换。至于 TTS 怎么搞,我们稍后再说。
结束节点
一旦音频生成好,结束节点会输出音频的 URL 地址,连同播客文本一起交给你。
音频生成
安装 F5-TTS
我们选用了最近大火的 F5-TTS。这个工具由上海交通大学开源,是一款高性能的文本到语音系统。它基于流匹配的非自回归生成方法,结合了扩散变换器(DiT)技术。换句话说,它能实现零样本学习,快速生成自然、流畅且忠于原文的语音,而且支持中英文多语言合成。长文本处理也是它的强项。
安装的话,正常按 Github 说明来就行。但这里有一个坑要提前提醒你:F5-TTS 不支持 Mac 架构。如果你用的是 Macbook,需要安装它的移植版本 F5-TTS-MLX。我自己用的是 Python 3.11,对号入座即可。
编写 Python API
我们用 PyCharm 创建了一个基于 FastAPI 的 Python 项目。FastAPI 负责给外部提供 API 访问能力,Dify 中的 HTTP 请求节点就是通过它来调用的。
代码的逻辑其实不复杂,主要分三步:第一步,接收 Dify HTTP 请求节点发来的播客结构化数据;第二步,解析这个数据,按说话人分段,Speaker 1 用女声参考音频生成,Speaker 2 用男声参考音频生成;第三步,把所有片段拼接成一个完整音频,输出最终的 wa v 文件。
核心代码里,还有一个容易被忽略但很重要的细节:在合并音频时,我们给每个片段之间加了 0.5 秒的停顿。这样做是为了让对话听起来更自然,而不是连珠炮一样挤在一起。
@app.post("/generate_podcast", response_model=PodcastResponse)
async def generate_podcast(req: PodcastRequest):
try:
print(req.content)
segments = ast.literal_eval(req.content)
audio_files = generate_podcast_segments(segments)
output_path = "./resources/_podcast.wa v"
duration = merge_audio_files(audio_files, output_path)
return PodcastResponse(audio_path=output_path, duration=duration)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
def generate_podcast_segments(segments: List[Tuple[str, str]], output_dir: str = "./resources/segments") -> List[str]:
os.makedirs(output_dir, exist_ok=True)
audio_files = []
for i, (speaker, text) in enumerate(segments, 1):
output_path = f"{output_dir}/_podcast_segment_{i}.wa v"
if speaker == "Speaker 1":
generate_speaker1_audio(text, output_path)
else:
generate_speaker2_audio(text, output_path)
audio_files.append(output_path)
return audio_files
def merge_audio_files(audio_files: List[str], output_path: str) -> float:
audio_data = []
for file in audio_files:
data, rate = sf.read(file)
silence = np.zeros(int(SAMPLE_RATE * 0.5))
audio_data.append(data)
audio_data.append(silence)
merged_audio = np.concatenate(audio_data)
sf.write(output_path, merged_audio, SAMPLE_RATE)
duration = len(merged_audio) / SAMPLE_RATE
return duration
始智AI 平台部署 F5-TTS
如果你的个人电脑配置有限,生成音频会比较慢。此时可以考虑用始智AI平台来部署 F5-TTS,把推理任务放到云端跑,速度会快不少。
