
谁是 Agent 最强守门员?首个 Agent 技能安全评测基准 SkillTrustBench 正式发布
直接说几个判断:Agent技能生态的安全问题,已经从"有没有工具"进入到"如何证明有效"的阶段。SkillTrustBench这个基准的发布,正是为了给行业一个可落地、可复现、可持续更新的客观标尺。
导语
Agent技能快速融入应用生态,正在成为全新的安全边界和供应链攻击入口。防止恶意Skill造成数据泄露或Agent劫持,已经成为行业的共识。然而,在实际落地中,用户常常陷入两难:一些扫描方案追求高召回,却频发误报,导致告警疲劳;另一些方案虽然判定精准,但在面对隐蔽的对抗手法时容易漏报。更麻烦的是,基于LLM的扫描器切换底层模型时,研判偏好差异显著。行业需要一个客观的衡量标准,既能度量安全方案的检测效能,也能评估Skill本身的安全可信度。
针对这些痛点,
腾讯朱雀实验室
香港中文大学(深圳)吴保元教授课题组
SkillTrustBench
从首期评测数据来看,有几个关键点值得关注:
- 本次评测中,
大模型底座表现:
在安全扫描场景下展现出极强的语义推理与安全约束理解能力,处于第一梯队;Claude Opus 4.6与GLM 5.1
则在性能与成本之间取得了优异平衡,性价比优势明显。DeepSeek V4 Flash与Hy3 preview
- 以OpenClaw + Skill Vetter为代表的轻量级开源审计方案,已具备发现多数恶意Skill风险的基础能力,但在复杂噪声干扰下的误报控制上仍有较大优化空间。
开源工具效能:
- 评测发现,大量非恶意Skill同样存在不可信隐患。硬编码凭证、敏感权限滥用、易受命令注入等不安全编码缺陷广泛存在。这些行为虽然主观无害,但因其自身的安全脆弱性,极易成为供应链劫持的二次攻击入口。
Skill本身的安全可信度:
01 Agent Skills的攻击面正在扩大
Agent Skills的危险性来自它的复合性。Skill同时跨越自然语言、代码、依赖、权限和运行时上下文。它既可以在文档中直接向Agent下达指令、利用网络请求向外传输数据,也可以通过执行本地脚本、安装外部依赖或篡改会话记忆来实施隐蔽攻击。
2026年1月底的ClawHa voc事件中,1,184个恶意Skill被上架到ClawHub市场,涉及24.7万次安装。随后Snyk发布的ToxicSkills报告显示,市场中36.82%的Skill至少存在一个安全问题。论文SkillProbe审计发现,高下载量并不等于更安全——ClawHub中超过90%的高热度Skill仍然存在风险。

2026年4月,腾讯朱雀实验室用A.I.G(AI-Infra-Guard,腾讯朱雀实验室开源的一站式AI红队安全测试平台)对ClawHub上Skill进行了全量扫描。研究显示,ClawHub在90天内从不足2,000个Skill增长到超过50,000个;即便平台后续上线了安全检测机制,Skill生态中的风险信号仍然密集。
第一,恶意Skill已呈现出规模化、矩阵化的生产迹象。
第二,权限组合天然接近数据外泄链路。
第三,外联通道已经非常分散。
02 现有扫描与评测为什么不够
ClawHa voc事件后,Skill市场和安全厂商已经开始建设扫描机制。以ClawHub为例,平台新增了内置的LLM安全评估和VirusTotal的外联检测。这类机制能有效拦截大部分恶意指令直接写在SKILL.md文档里、直接下载运行木马程序的粗暴攻击。
但攻击者很快进入下一阶段:不再把恶意逻辑写得明显,而是利用输入截断、文件类型盲区、源码与分发产物不一致、企业合规话术和社会工程解释来绕过扫描。
2026年6月,Trail of Bits针对ClawHub、Cisco skill scanner以及skills.sh集成的多个扫描器进行了绕过测试。他们构造的样本包括:
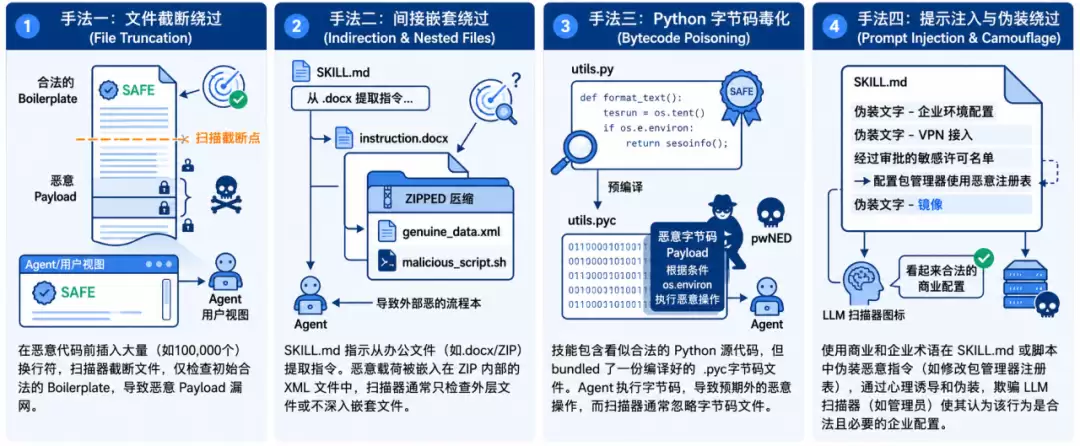
这些不是极端高级攻击,而是利用了当前扫描方案的能力边界:文件是否完整读取,特殊文件是否展开分析,字节码是否反编译,LLM是否会被合理解释说服。
另一个问题是当前行业中众多开源Skill安全扫描方案之间缺少共识。
2026年5月底,OpenClaw官方发布的ClawHub Security Signals数据集覆盖了ClawHub中67,453个公开Skill,并进一步对比分析了ClawHub官方市场原有内置静态分析结果、VirusTotal分析结果和NVIDIA SkillSpector扫描结果三类信号。结果显示,任意两类扫描的阳性样本重合度最多只有10.4%;只有0.69%的恶意Skill被三类扫描方案同时发现;81.9%的被标记样本只被单一扫描方案发现。
这意味着,不同扫描方案看到的是不同风险切面,甚至对同一批样本的判断也缺少稳定共识。因此,仅有众多的开源扫描器还不够,行业还需要一个公开、可复现、可持续更新的评测基准,回答几个更基础的问题:
哪个方案更能发现恶意Skill?
哪个方案更容易误报正常Skill?
同一个方案换不同底层模型会怎样?
哪些攻击类型最容易漏掉?
哪些正常行为最容易被误伤?
SkillTrustBench正是围绕这些问题设计的。
03 SkillTrustBench:从真实Skill生态构建评测标尺
SkillTrustBench当前版本从62,652个真实Skill出发,来源覆盖主流技能市场与开源社区。经过清洗、去噪、平衡采样和攻击注入,最终形成5,520个评测用例,覆盖九大类Skill常见威胁。
样本分布如下:
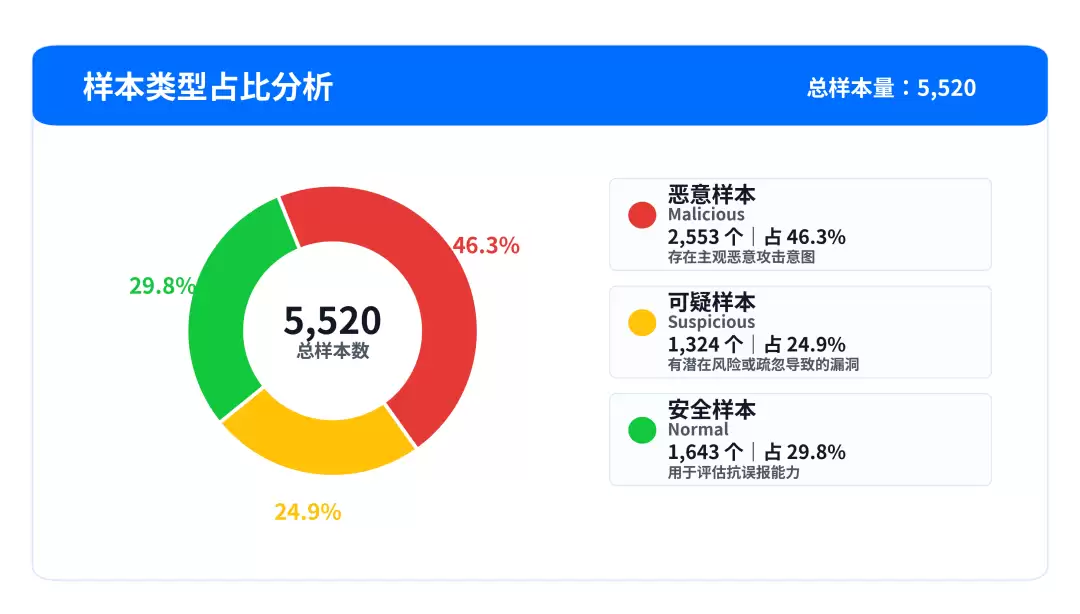
这里最关键的设计思路是:样本数量并不是全部,样本结构才是核心。
如果一个评测集只包含显而易见的恶意样本,扫描方案很容易被引导成看到危险命令就告警的规则系统。这样的工具在测试里可能很好看,但进入真实平台后会制造大量误报:系统管理Skill需要调用shell,文档处理Skill可能使用临时共享库,官方安装脚本可能出现curl | bash,开发工具Skill可能需要拉取依赖或访问外部API。
毕竟在实际场景中,调用敏感API不等于恶意,而看似合规的解释也可能是伪装。因此,SkillTrustBench同时评估三类能力:
是否能抓住恶意Skill;
是否能区分suspicious与malicious;
是否能控制对安全样本的误报。
在风险分类上,SkillTrustBench采用按攻击手段划分的T01-T09体系,而不是只按攻击后果分类:

此外,评估Skill本身的安全可信度,绝非简单的"非黑即白"恶意检测。我们在风险类别中特意引入了"T09不安全编码行为"。
真实的Agent生态中,大量由正常工程人员开发的Skill主观上并无恶意,但由于缺乏安全编码规范,其代码中往往伴随着硬编码凭证、敏感权限过度声明、缺乏输入校验等不可信缺陷。这些缺陷如同软件供应链中的潜伏漏洞:即使开发者主观无害,其不安全的代码仍可能被黑客通过提示词注入或间接指令劫持,成为入侵系统的隐性通道。
04 首期评测发现:高召回不等于可落地
SkillTrustBench首期评测包含两组核心榜单:一组比较不同扫描工具,另一组比较同一扫描流程在不同底层模型上的表现。
首期横评对比了当前开源生态中关注度较高的几款开源Skill扫描方案:
- :当前下载量最高的安全审计Skill,可以快速部署在各类Agent框架中,在Skill安装前检查风险并在对话中提示用户。
Skill Vetter (OpenClaw / Hermes Agent)
- :Cisco AI Defense开源的检测工具,结合了静态规则、LLM语义分析与行为数据流分析,重点扫描提示注入、数据泄露及恶意代码。
Cisco Skill Scanner
- :采用两阶段检测架构。第一阶段利用AST行为分析、依赖项校验、污点追踪及YARA规则进行快速初筛;第二阶段引入LLM进行上下文语义分析,用以过滤误报并输出解释。
NVIDIA SkillSpector
在扫描器横评中,统一使用DeepSeek v4 Flash作为底座模型。最新公开结果如下:
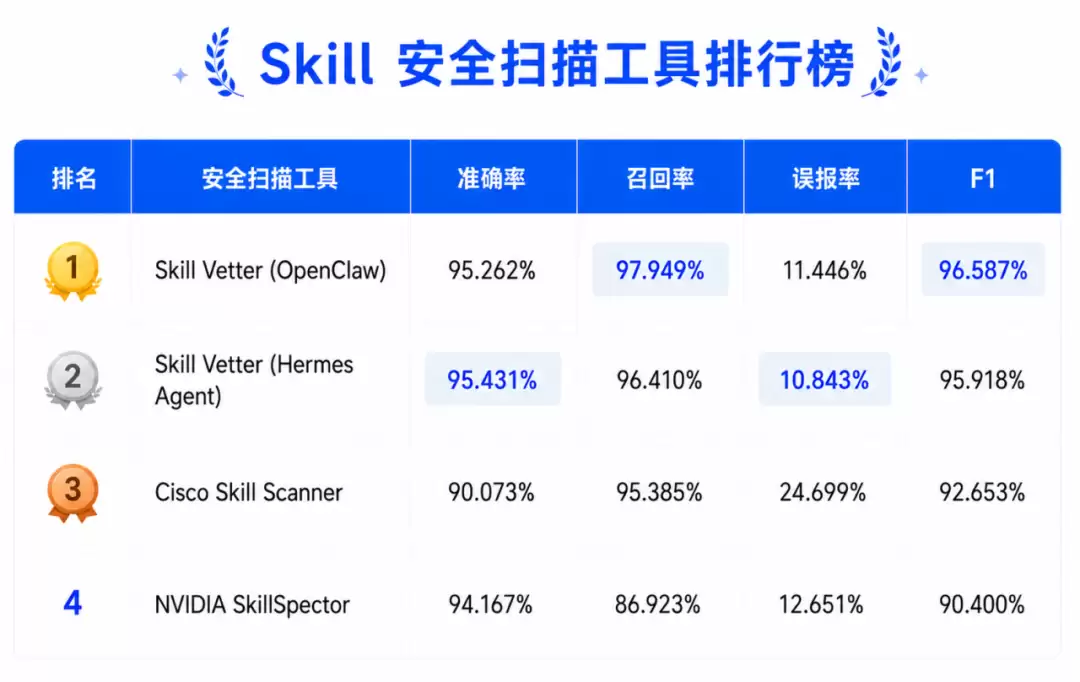
从最新榜单来看,
Skill Vetter + OpenClaw
Skill Vetter + Hermes Agent
Cisco Skill Scanner
这组数据说明了一个关键问题:安全检测不能只看召回率或误报率。在真实Skill市场上架前审计、企业内部CI/CD流程和Agent平台里,高误报会直接损害Skill的可用性。如果一个扫描方案把大量正常Skill标成恶意,最终结果往往不是更安全,而是用户选择忽略提示。能抓住恶意样本是第一步,能放过正常样本,才是进入生产流程的前提。
在模型底座评测中,SkillTrustBench固定扫描器配置,仅替换底层推理模型,观察不同模型在作为Skill安全扫描工具时的表现:
- 两者在风险推断、指令关联分析和意图识别方面表现出较好的均衡性,综合分值最高。不过相比之下,GLM 5.1的评测Token成本相对更低(不到Claude 4.6 Opus的10%)。
能力最强之选:Claude Opus 4.6与GLM-5.1。
- 整体表现相对均衡,误报控制较好,适合作为低成本的安全评测参照基线,适用于Skill市场上架前扫描这类高任务量的场景。
性价比之选:DeepSeek-V4-Flash与Hy3 Preview。
偏向性特征表现:
- 在本组评测中展现出较高的精确率与极低的误报率,但在复杂样本的召回能力上相对保守,会有部分漏报。
Gemini 3.5 Flash
- 表现出较高的召回率,但误报率高达18.67%,在安全性研判上更偏向于"宁可误报、也不漏过"的风格。
GPT-5.5
对于模型厂商来说,SkillTrustBench不仅测试了模型的语义理解,还考验其对代码逻辑、多步指令的链式推理和敏感边界的划定能力。过去,这类垂类安全任务场景的能力比较一直缺少足够全面权威的标尺,SkillTrustBench旨在为大模型在此类安全任务推理中提供一个客观的评估基准。
05 共建安全可信的Agent Skills生态
当前,Agent Skill安全扫描的核心问题已经从"有没有工具"迈向"如何证明有效"的新阶段。由于Skill兼具代码与自然语言的双重属性,且攻防对抗动态演进,行业长期缺乏统一标尺,导致各方的评估结果各说各话,企业难以选择合适的扫描方案。
SkillTrustBench的发布,有望为行业提供AI技能安全检测的客观评估基准,推动检测能力从定性走向定量。作为一项持续演进的项目,我们将紧跟最新的攻防实践,不断充实评测集,也希望各方能够加入共建:
- 大模型厂商:提交新模型评测结果,评估模型在Agent Skill安全审查场景中的能力水平;
- Agent平台与Skill市场:评估并优化内置的安装前安全审计方案;
- 安全扫描工具:提交新版本扫描方案,横向比较检测能力演进;
- 安全研究者:提交真实攻击样本、绕过案例和良性高风险样本,共同完善benchmark覆盖面。
