
PDF Extract API:OCR文档提取与解析工具,Python+自然语言实现
来源:互联网
时间:2026-06-13 13:52:35
在处理文档解析这件事上,市面上其实已经有不少工具了,但能把精度、效率和安全性都照顾到的,还真不多。今天要聊的这款
PDF Extract API
核心功能
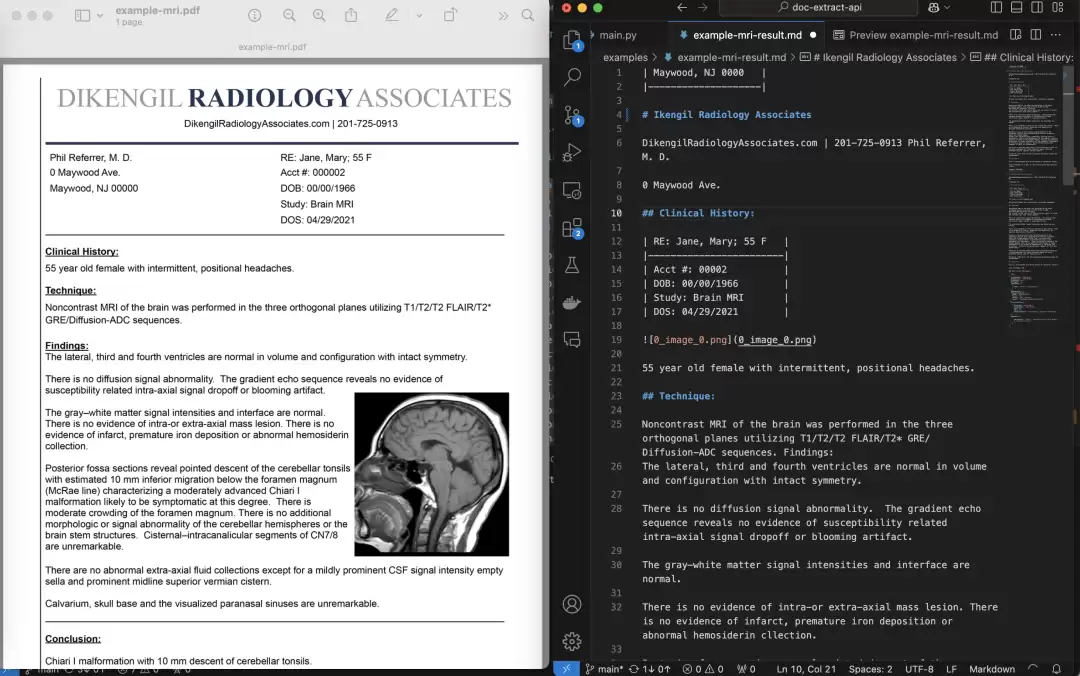
1、高精度文档提取
说到提取,最怕的就是识别不准,尤其是面对那些排版复杂、内容杂乱的资料。PDF Extract API采用的是现代OCR(光学字符识别)技术,能精准把PDF或图像里的文本信息“读”出来。更值得说的是,哪怕文档里夹杂着复杂的表格、数字甚至数学公式,它也能给咱梳理得清清楚楚,信息在转化的过程中几乎不丢、不错。
2、个人识别信息(PII)匿名化
隐私保护嘛,现在谁不重视?这款API自带一个隐藏技能——自动移除文档中的个人识别信息(PII)。也就是说,当你需要处理一些敏感数据时,比如合同、病例、身份证照等,它可以自动把涉及隐私的部分抹掉,整个过程无需人工介入。这样一来,不仅可以安心分享文件,也更容易满足各类隐私合规要求。
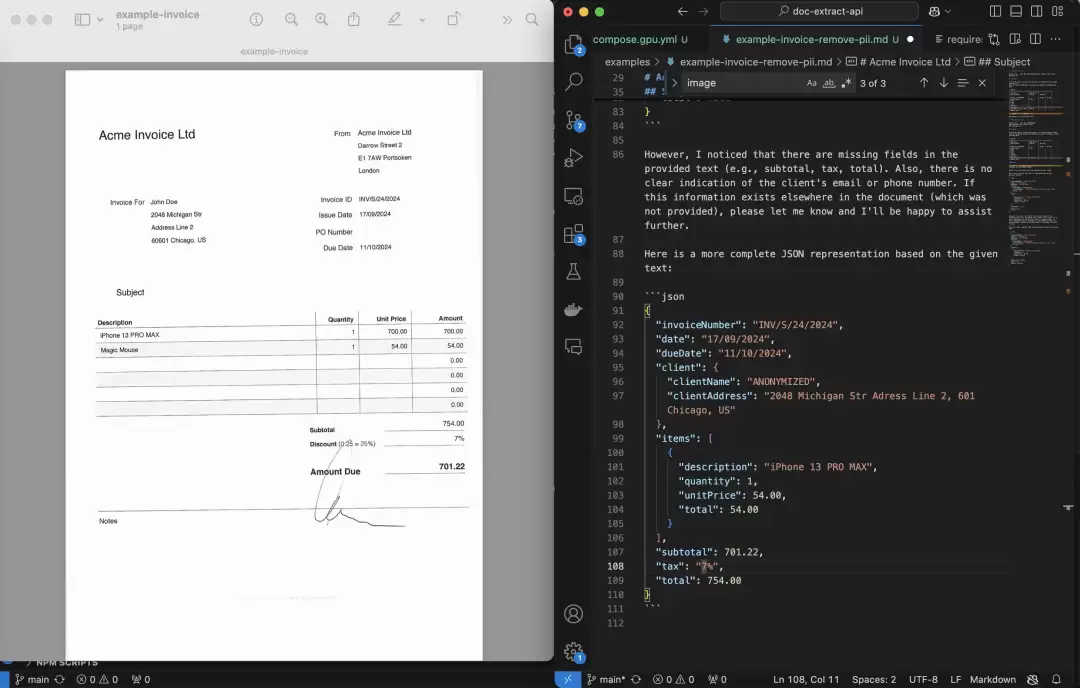
3、结构化输出
提取出来的内容最终以什么形式呈现,也很关键。PDF Extract API支持直接将内容转为JSON或Markdown格式。前者适合做后续的数据分析和系统集成,后者则更适合生成网页或快速排版的文档。简单说,两头都沾得上,既能给机器读,也能给人看。
4、高效的后台处理
技术底子上,这个API是用
