
3.1万Star!PageIndex:不用向量数据库,RAG准确率做到98.7%
PageIndex 开源系统通过树形索引与推理检索,彻底告别向量数据库,将 RAG 准确率提升至98.7%。核心内容:1. 传统向量RAG“相似不等于相关”的固有缺陷2. PageIndex基于树形索引与推理检索的核心架构3. 与传统RAG相比在准确率上的突破性提升
你有没有做过 RAG,结果发现 AI 的回答明显在"猜"?
你的文档明明写得很清楚,但 AI 检索回来的总是不相关的片段——语义上相似,但逻辑上答非所问。你开始调 embedding 模型,换向量数据库,调 chunk size,调 top-k,折腾一周,准确率还是卡在 60-70%。
这个问题的根本原因不是模型不够好,也不是 chunk 切得不对。是向量检索的本质缺陷:
相似不等于相关
PageIndex 的做法是:把向量数据库整个扔掉。
它是什么
PageIndex 是 VectifyAI 开源的无向量、基于推理的 RAG 系统,Python 编写,目前
31,777 Stars,2,736 Forks
核心思路来自 AlphaGo:用推理代替相似度匹配。传统 RAG 把文档切块然后搜相似向量,PageIndex 先把文档变成树形索引(类似目录),然后让 LLM 在这棵树上推理寻路,找到真正相关的段落。
架构:树形索引 + 推理检索
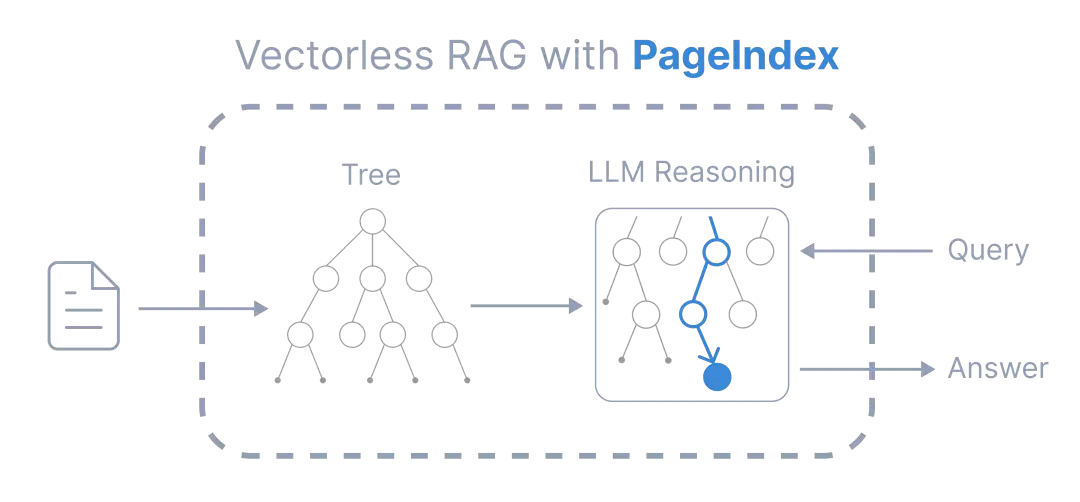
两步流程:
第一步:建树(Table-of-Contents Index)
把 PDF 文档解析成层级树结构——不是切块,是按文档的自然结构建章节树,每个节点有标题和摘要。金融报告、法律合同、技术手册,都能生成这种结构化索引。
{
"title": "Financial Stability",
"node_id": "0006",
"summary": "The Federal Reserve monitors...",
"nodes": [
{ "title": "Monitoring Financial Vulnerabilities", "start_index": 22 },
{ "title": "Domestic and International Cooperation", "start_index": 28 }
]
}第二步:推理检索(Tree Search)
不是找"语义相似的向量",而是让 LLM 读索引,像人类专家一样顺着目录思考:"这个问题需要查第三章,第三章的2.1小节才是真正相关的",逐层缩小范围,最终定位到准确段落。
和传统 RAG 的核心差距
| 维度 | 向量 RAG | PageIndex |
|---|---|---|
| 检索方式 | 语义相似度搜索 | LLM 推理树搜索 |
| 需要向量数据库 | ✅ 必须 | ❌ 完全不需要 |
| 文档切块 | ✅ 必须 | ❌ 不切块 |
| 上下文感知 | ❌ 静态向量 | ✅ 对话历史参与检索 |
| 可解释性 | ❌ 黑盒相似度 | ✅ 推理路径可追溯 |
| FinanceBench 准确率 | ~70-80% | 98.7% |
专业长文档(金融报告、法律条款、学术教材)是向量 RAG 最容易翻车的场景,也是 PageIndex 最擅长的地方。
快速上手
pip3 install -r requirements.txtfrom pageindex import PageIndex
# 初始化并索引文档
pi = PageIndex(api_key="your-key")
pi.index("annual_report.pdf")
# 推理检索
result = pi.retrieve("Q4 2023 的营收增长主要来自哪些业务?")
print(result.pages) # 精确页码 + 段落引用还有更强的 Agentic 模式:接入 OpenAI Agents SDK,自动多跳推理,适合需要跨多份文档联合分析的场景。
三种部署方式
- :开源代码跑本地,标准 PDF 解析
自托管
- :更强的 OCR 和树构建能力,按调用计费,有 MCP 接口
云端 API
- :私有化部署,预约 Demo[1]
企业版
Chat 平台也上线了,直接上传 PDF 用自然语言问答:chat.pageindex.ai[2]
做 RAG 应用的同学,值得认真看一下这个项目。向量数据库不是 RAG 的唯一解法,推理检索可能更适合你的场景。
项目地址:https://github.com/VectifyAI/PageIndex[3]
引用链接
[1]预约 Demo: https://calendly.com/pageindex/meet
[2]chat.pageindex.ai: https://chat.pageindex.ai
