
又一个神级 Codex Skill 诞生了:一个 API Key,打通全网自媒体数据!
做内容数据相关开发的同学,大概率都经历过一个共同的痛苦:想拿抖音热门、小红书爆款、公众号增长数据,要么自己写爬虫天天维护,要么买传统数据工具的会员然后手工导出 CSV。前者成本高,后者没法自动化集成到自己的分析系统或 AI 流程里。
自己写爬虫?反爬升级一次,代码就得修一次,selenium 模拟登录那套东西三个月能过时两回。买飞瓜、蝉妈妈的会员,数据要导出来再写脚本解析字段,始终不是工程化的方案。这个过程,懂的人都懂。
最近试了 RedFox 红狐数据(redfox.hk),确实眼前一亮。它把自媒体数据做成了标准 REST API 和开源 Agent Skill,定位很清晰:
给开发者用的数据基础设施,而不是另一个需要人工点点的数据看板。
用它替换掉自建的爬虫模块,大概两周时间,数据采集维护成本直接降了至少 90%。
结论先放在这儿:如果项目需要抖音、小红书、公众号等平台的热门内容或榜单数据,RedFox 能省掉至少 90% 的数据采集维护成本。
RedFox 到底是什么
市面上自媒体数据工具(新榜、飞瓜、千瓜等)的普遍模式,还是提供 Web 后台,人工登录、搜索、筛选、导出。操作跟开发流程是割裂的。想自动化?要么写 UI 自动化脚本,脆弱得不行,要么官方根本没提供 API。
RedFox 的切法完全不同:
它不做前端看板,而是把数据封装成标准 HTTP API。
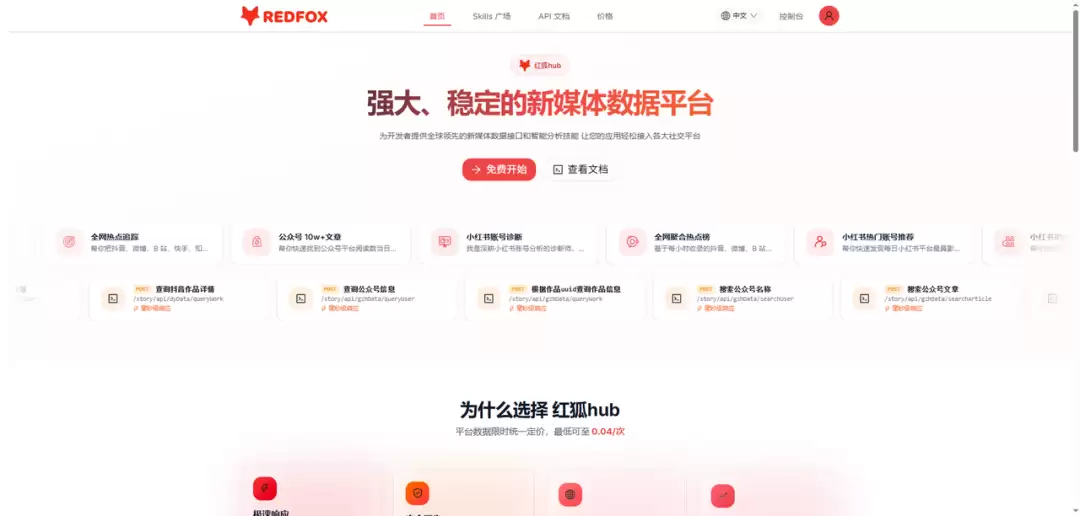
另外,RedFox 还提供了一个开源的 Agent Skill 集合(GitHub: redfox-data/redfox-community),目前有 45 个 Skill,可以让 Claude Code、Codex、Cursor 等 AI 编程助手直接调用这些 API。当然,不用 AI 编程助手,纯 REST API 也足够好用。
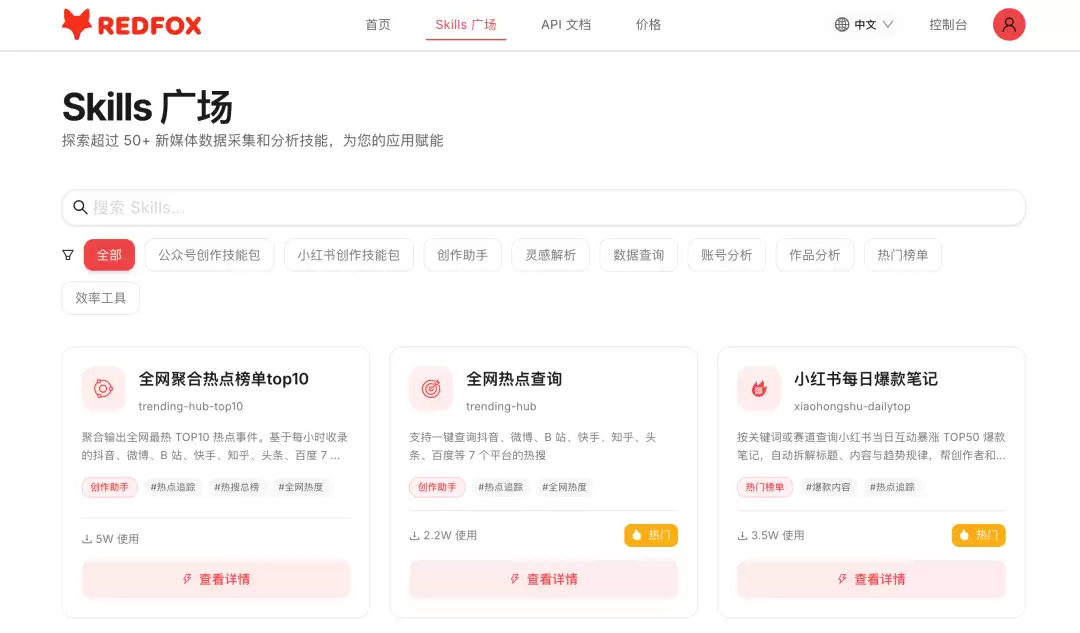
功能详情
1. 一个 API Key,打通 11 个平台
不需要为每个平台维护不同的认证和抓取逻辑。注册后在控制台创建 API Key,环境变量里直接配:
export REDFOX_API_KEY="sk_xxxx"
请求示例,以抖音每日热门为例:
curl -X GET "https://api.redfox.hk/v1/douyin/daily-hot?date=2026-06-07" -H "Authorization: Bearer $REDFOX_API_KEY"
返回标准 JSON:
{ "code": 0, "data": [{ "title": "AI 编程爆火背后的真相", "play_count": 1280000, "like_count": 89000, "author_name": "科技捕手", "publish_time": "2026-06-07T12:00:00Z" }] }
所有平台的返回结构都做了字段归一(play_count、like_count、comment_count、share_count 等),统一处理。以前自己写爬虫,抖音返回的字段叫 digg_count,小红书叫 likes,公众号叫 like_num,光字段映射就得写一个适配层。RedFox 这一层直接省掉了。
2. 开源 Skill + SDK,不只是 HTTP
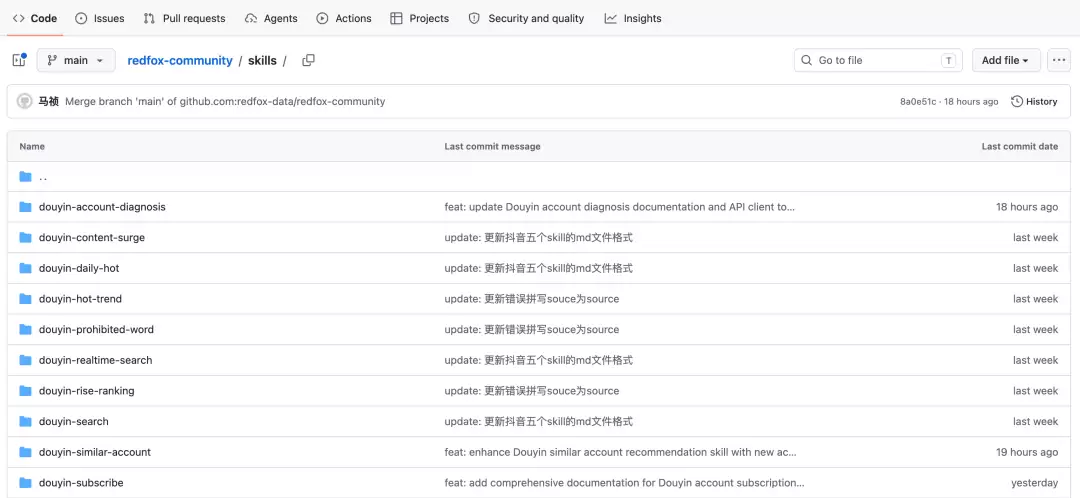
RedFox 在 GitHub 上开源了完整的 Skill 集合,基于 TypeScript 编写,可以直接装到 AI Agent 环境:
npx skills init
npx skills add redfox-data/redfox-community
同时也提供了 Python SDK 和 Node.js SDK。如果不想依赖 Agent 框架,直接 HTTP 调用也行。API 文档支持分页、时间范围、排序、多平台聚合查询。
装上 Skill 之后,在 Codex 或 Claude Code 里直接说话:"最近三天抖音上 AI 编程的热门视频有哪些",Agent 自己调 API、解析数据、组织结果。不用记接口路径,不用翻文档。
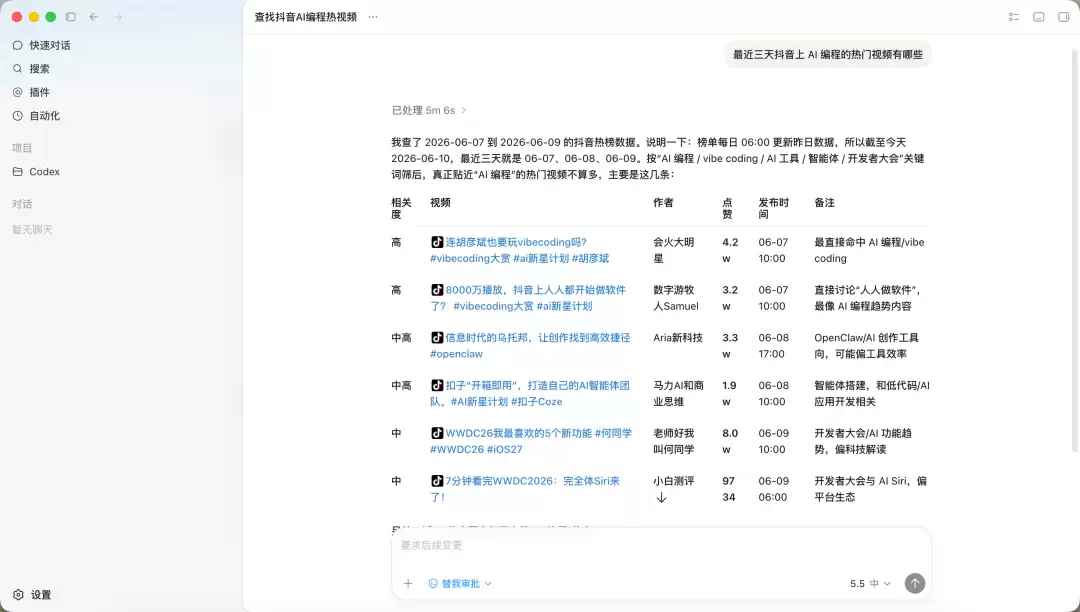
3. 几个典型开发场景
场景一:每日热点数据自动入库。
import os, requests
headers = {"Authorization": "Bearer " + os.environ["REDFOX_API_KEY"]}
resp = requests.get("https://api.redfox.hk/v1/douyin/daily-hot", headers=headers)
hot_list = resp.json()["data"]
# INSERT INTO your_table ...
场景二:低粉爆款监测。
场景三:内容合规检测。

场景四:AI 驱动的多平台改写。
4. image2-gpt 文生图 + Seedance 2.0 视频生成
RedFox 还接入了两个 AI 生成能力,目前在
免费使用阶段
image2-gpt 做文生图。在 Skill 里可以直接说"帮我生成一张介绍RedFox,带有科技感的适合公众号头图尺寸的图片",不用切到 Midjourney 或 SD,对需要给文章配图的场景已经够用。
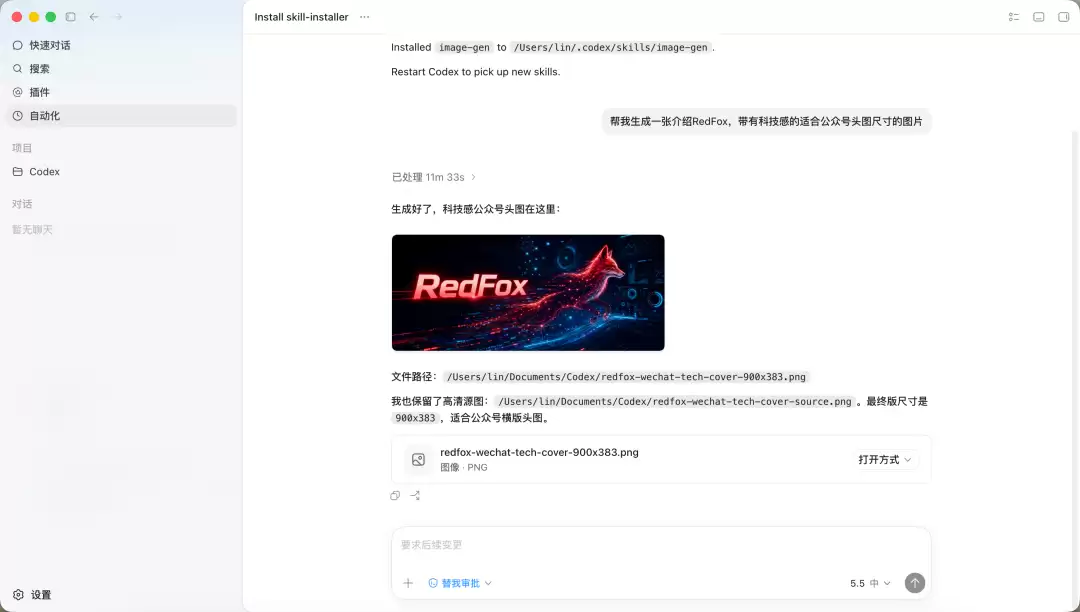
Seedance 2.0 是视频生成模块,用的字节的模型。目前可以在 RedFox 的 Skill 里免费调用。虽然还在早期阶段,但这个方向是对的:
数据采集 + 内容生成在同一个平台里闭环,不用在工具之间来回切换。
5. 合规与稳定性
很多开发者会担心数据来源的合规性。RedFox 的官方说明是:
所有数据通过平台公开接口、合法合作方授权、以及严格遵守 robots.txt 的公开爬虫获得。不提供破解、模拟登录、绕过反爬等灰色手段。对于抖音、小红书等对数据敏感的头部平台,RedFox 已取得相关数据服务资质并接受平台定期审核。
API 可用性 ≥ 99.9%(月度统计)。
计费
纯按量,没有月租。新用户注册有免费额度,先跑起来再说。日调用量越大单价自动往下走,这个定价逻辑对真正在大量用 API 的开发者是友好的。Skill 本身开源免费部署,调数据 API 时才按请求量计费。
怎么注册
注册流程三步,五分钟搞定。
第一步,访问 redfox.hk(复制到浏览器打开),用邮箱完成账号注册。
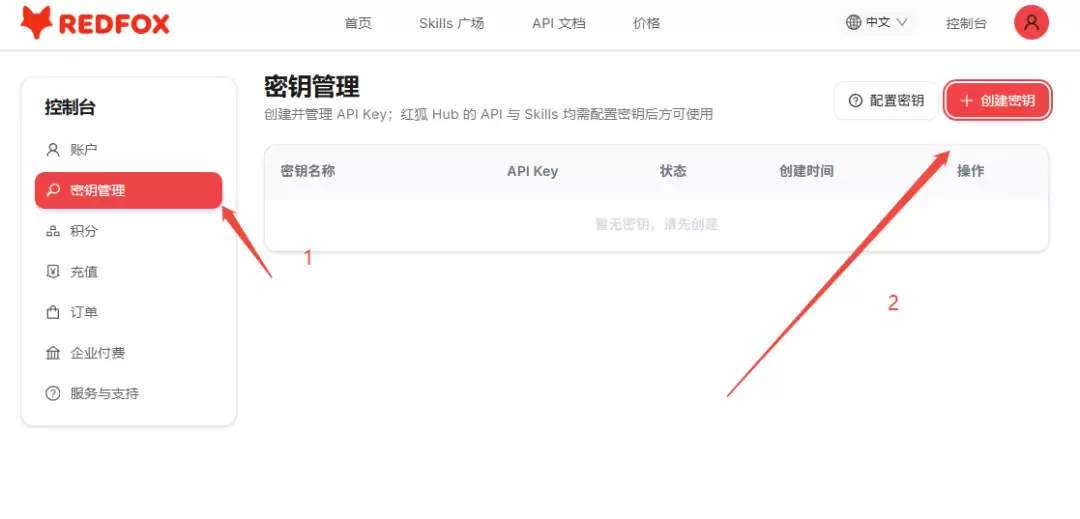
第二步,进入「个人中心」→「密钥管理」→ 创建 API Key。这串 Key 就是你的专属数据通行证,后面装 Skill 的时候会用到。
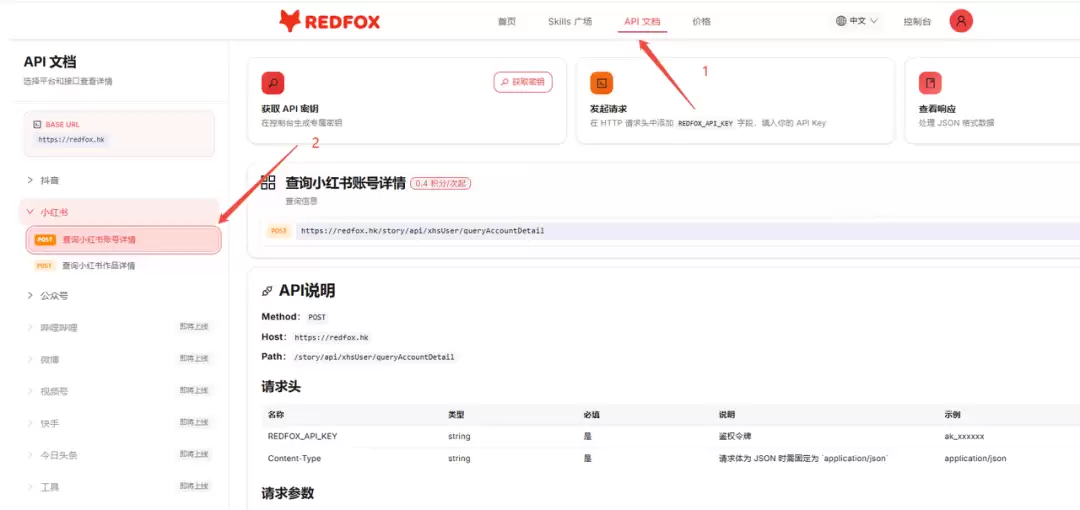
第三步,进入「API 文档」,选择你要接入的平台(小红书、公众号、抖音等),按文档说明调用数据接口。
注册送免费体验额度,可以零成本试用热点筛选、爆款拆解、数据复盘这些核心 API。
同款 Skill 技能包也上架了 Coze,Coze 用户可以直接去体验——但想真正解锁 API 数据打通 AI 工作流的能力,还是得来 RedFox 官网注册领额度。
两句话说清楚
RedFox 解决了一个很具体的工程问题:把 11 个平台的公开数据封装成标准 API,让开发者不用再跟爬虫和反爬死磕。加上 45 个开源的 Agent Skill,数据直接接进了 AI 工作流。
如果正在维护一套自媒体数据采集的爬虫代码,或者买了数据工具会员却没法把数据导进自己的系统,搞一个试试。注册拿免费额度,装个 Skill,在 Codex 里敲第一行 curl。大概率就知道它在说什么了。
