
Agent skill 迭代式编写实战
将专家经验转化为AI可执行的"操作手册"——这个思路听起来有点抽象,但落地之后的效果很实在。核心要点集中在三个方面:Agent Skill到底长什么样、什么场景该用它;三层渐进式披露架构和确定性脚本化设计怎么搞;以及内部自查与外部评估这套双重验证机制怎么搭。

这篇文章梳理了年初以来在Agent Skill编写上的一些实践心得,配图由QoderWork生成。内容主要包括两部分:一是对Agent Skill概念、特性以及适用场景的理解;二是在迭代式编写过程中积累的具体经验。

关于Skill:概念、特性与应用场景
什么是Agent Skill
Agent Skill本质上是一套模块化的能力包,可以理解为沉淀了领域知识的资产bundle。它里面包含了自然语言指令、元数据,以及一些可选的资源文件,比如脚本、模板等等。当AI Agent需要的时候,可以自动加载并使用这些内容。打个比方,如果说MCP给Agent提供了"手"来操作工具,那Skill就是一本"操作手册",告诉Agent这些工具具体该怎么用。
从时间线来看,2025年10月中旬Anthropic正式发布了Claude Skills,两个月后Agent Skills作为开放标准推出,随后Cursor、OpenCode、Qoder这些主流工具也都陆续跟进了支持。
通俗点说:Skill就是给Agent准备的一套业务SOP大礼包。里面包含了执行流程、背景知识、工具使用说明、模板素材,还有常见问题的处理方式,非常实用。
Agent Skill的形态
Skill是基于文件系统驱动的,Agent工具通过Skill标准中的tool以及终端/文件操作能力来完成发现和加载。
一个标准的Skill目录结构大致是这样的:
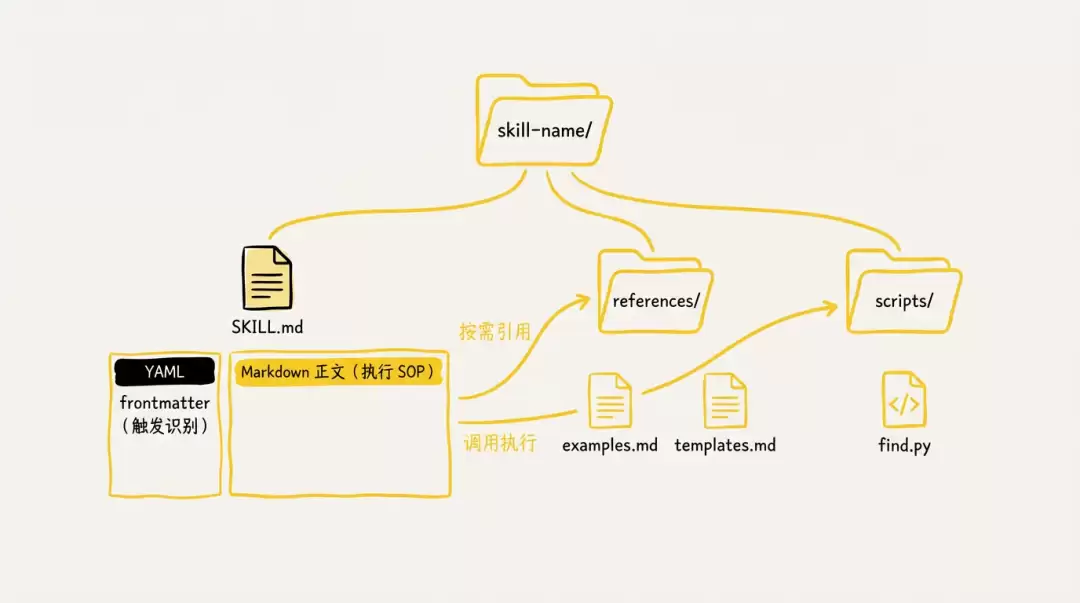
其中核心文件是SKILL.md,它由两部分构成:
- YAML frontmatter:这里存放的是Skill的元数据,Agent会先读这个来判断要不要触发。
description字段最关键,通常需要写清楚适用场景和关键触发词。 - Markdown正文:写给Agent看的执行SOP。建议采用"总-分"结构,先把核心规则摆出来,再展开具体的约束细节。
references/目录放的是补充文档,比如模板文件、详细的规范说明、示例代码等等。在SKILL.md里通过路径按需引用就行,不要把大量内容一股脑全塞进主文件。
scripts/目录放的是确定性操作的执行脚本,可以是Python或者Bash。一个重要的原则是:能写成脚本的就不要指望Agent自己推理——脚本的稳定性和可复现性远高于让Agent去猜。
扩展一点:如果Python脚本有第三方库依赖,可以用uv run配合PEP 723来处理,相当方便。
Agent Skill的核心特性

适合使用Agent Skill的场景
以下几个场景特别适合引入Agent Skill:
- 半自动化重复流程:同一业务流程频繁执行,但其中部分环节依赖主观判断,无法做到完全自动化。
- 领域知识导向:业务流程严重依赖专家知识,单靠LLM的泛化能力很难覆盖全面。
- 上下文受限:Agent的职责多样且上下文窗口有限,处理其他任务时不希望无关的领域知识占用宝贵的上下文空间。
当然也有不太适合的场景:
- 简单任务:直接用基础提示词,靠LLM的泛化能力就能搞定。
- 流程完全确定性:这时候写代码自动化更靠谱。
- Agent职责高度单一:直接把Skill内容放进system prompt就行,脚本用MCP/Tools代替,没必要再包装成Skill。

Agent Skill编写经验
建议先装好下面这两个元Skill再动手,会省很多事:
- skill-creator:用于生成Skill
- skill-judge:用于评估Skill
设计时遵循三层渐进式加载架构
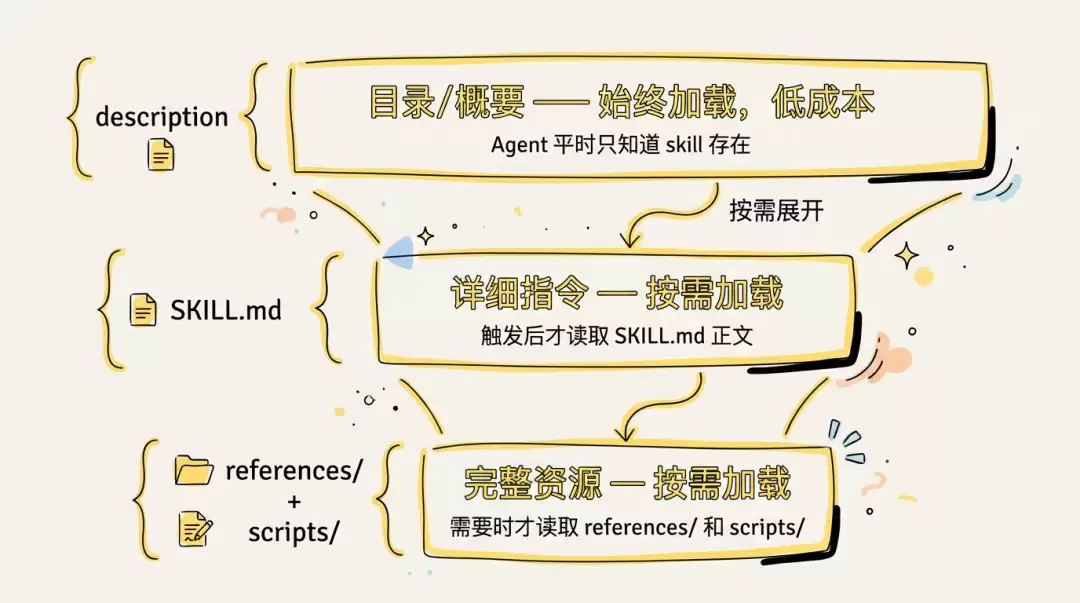
渐进式披露是Agent Skill最核心的设计思想。简单说就是把技能信息拆成三层:
- 第一层:目录或概要。这是成本最低的一层,Agent平时只需要知道手册的目录结构就行。
- 第二层:详细指令。按需加载,Agent需要的时候才会打开具体章节看细节。
- 第三层:完整资源。包含详细步骤和工具脚本,是最完整的一层。
所以设计Skill的时候就要想清楚:哪些内容必须放在skill.md里,哪些可以下沉到reference里。
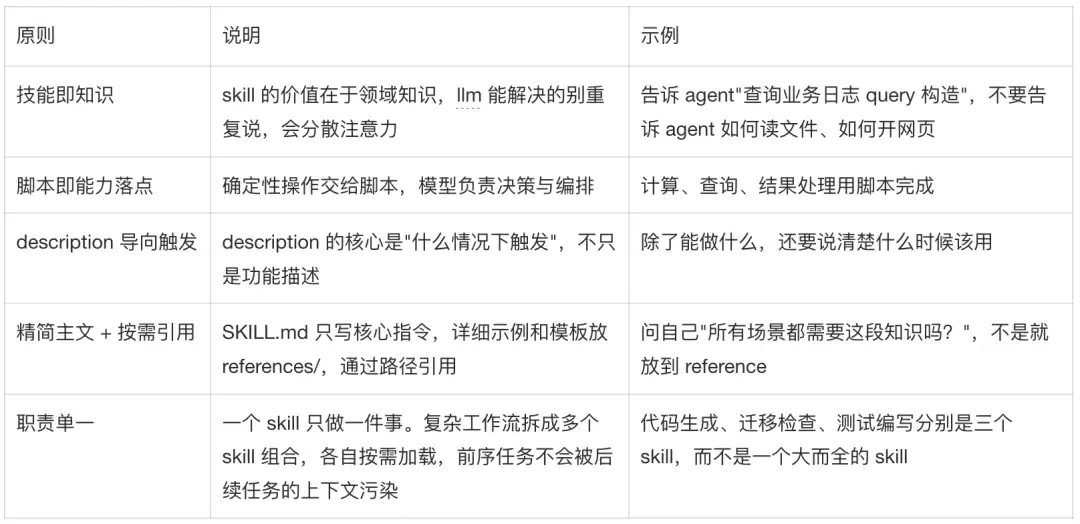
迭代式开发
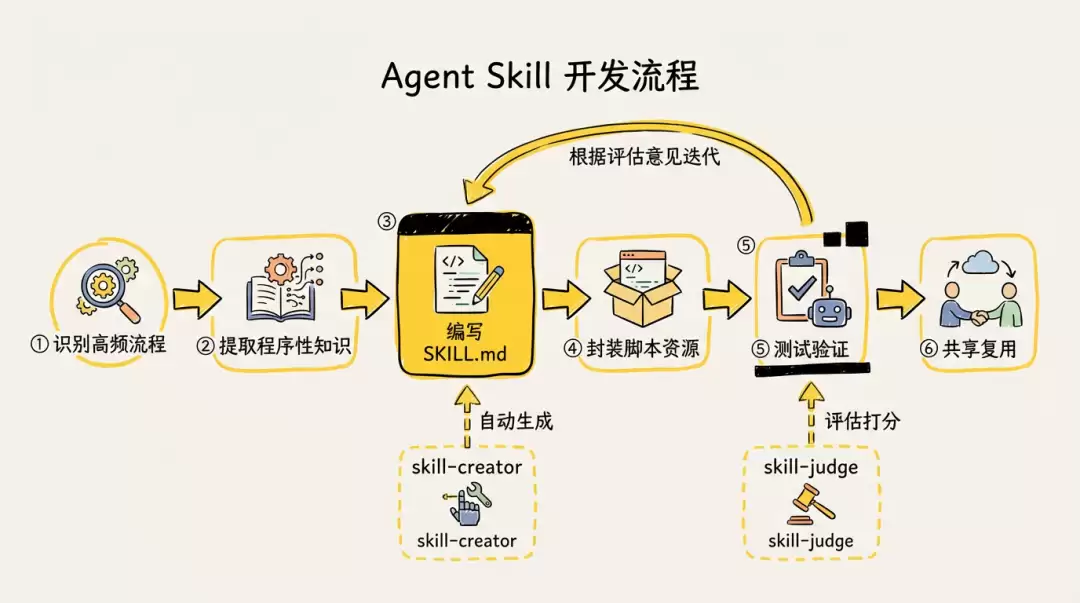
开发过程中有一些具体的实践可以优化Skill的效果:
用决策树替代模糊判断
决策树是一种正向约束,它能让Agent在做判断时行为更加可控。下面是一个异步消息问题排查的Skill片段示例:
### 结果处理规则
**补全未发出消息:** 若有序事件的前序有日志、后序无日志,在报告表格中补充后序事件行,tag以外字段留空,备注标记为"消息未发出"。
**消费失败处理:** 判断某 tag 是否失败,标准为 `resultFlag = N` 且该 tag 后续无 `resultFlag = Y` 的记录。
- 若后续**有** `Y`(重试成功)→ 取**第一条**失败行,调用错误详情查询
- 若后续**无** `Y`(持续失败)→ 取**每一条**失败行,调用错误详情查询
**错误详情查询(消费失败):**skill-judge把决策树列为高质量Skill的明确标志,在知识增量和实用性两个维度都是加分项。原因很简单:Skill的核心价值就是封装专家才有的判断知识。决策树把"应该怎么判断"写得清清楚楚,而不是用模糊语言把判断压力甩给Agent。Agent不需要推理,顺着树走就行。比起模糊描述,可执行性高了一个层次。所以写Skill时遇到分支判断,优先用树形结构,而不是让Agent自行决策。
负向约束要配替代方案
告诉Agent不能做什么的时候,最好同步给出合法的替代方案,这样约束力会强很多。下面是一个单元测试编写Skill的片段,给出了Mock时的Bad Case和相应的解决方案:
### Mocking Restrictions
**Do NOT mock:**
- `public static` fields (e.g., `@AppSwitch`-annotated configurations) - assign values directly in `@BeforeEach` and restore originals post-test
- POJO classes or OneLog objects - initialize simple POJOs programmatically; load complex POJOs from JSON files
- Stateless static methods (e.g., utility methods for conversion/assembly) - call real implementations directly不要只说"不能做什么",要给"那应该怎么做"。这也是一种Few-shot。没有替代方案的话,Agent会自己找一个——结果往往不是你想要的那个。
Skill执行后自查机制
决策树解决的是执行前的分支判断——走哪条路。自查机制解决的是另一半:执行完了,产出物是否合格。下面是一个单元测试生成Skill的执行后自查列表示例:
## Post-Generation Review
After generating tests, review against this specification to ensure:
- Correct test file location and naming
- Proper mock configuration without prohibited patterns
- Complete verification of return values, state mutations, and invocations
- AssertJ assertion patterns are used consistently
- No reflection-based testing or private member verification
- Similar tests are grouped into parameterized tests where appropriate
- Parameterized tests use appropriate source types and handle null values correctlyAgent的自然倾向是完成任务就结束,不会主动回头检验。很多规范性错误恰恰在"完成"之后才能发现。把自查写进Skill,就是强制插入一个反射节点,把"我觉得做完了"变成"我验证过做完了"。
自查可以从两个角度来:
- 规范符合性:对照约束检查,确认没做错。
- 覆盖完整性:对照领域知识检查,确认没遗漏。
决策树是收敛的(从多条路中选一条),自查清单是发散的(从一个结果出发,在多个维度验证)。有明确输出规范的Skill(比如代码生成、迁移、测试等),成熟后建议补上自查机制。
Skill的外部验证:Eval机制
自查是Skill执行时的内部静态验证,由Agent对照清单自检。而skill-creator还提供了外部动态验证:用真实输入跑Skill,对比有Skill和没有Skill的输出差距,而不是靠感觉判断好坏。
Eval的四个环节:
- 测试用例:设计2-3个真实用户会说的提示词,同一提示词分别跑"有Skill"和"无Skill(或旧版本)",保留两份输出用于对比。提示词要有足够的复杂度和具体背景——Skill的触发本身依赖Agent对description的语义识别,过于简单的prompt可能根本不会触发Skill,也就测不出任何东西。
- 断言:有客观标准的Skill设计可验证检查项(比如"输出文件是否包含字段X"),主观类Skill则基于人工反馈。
- 迭代循环:评估 → 修改 → 重跑 → 再评估,每轮聚焦有明确问题的用例,直到没有明显差距。这里有个注意事项:每轮只看少数用例,容易把Skill改成只对这几个case有效。改的时候要从具体反馈里抽出通用规律,而不是针对测试用例做针对性修补。
- description触发率优化:Skill内容稳定后单独优化description,用should-trigger / should-not-trigger样本测试召回精度,重点关注"近似场景误触发"和"该触发却未触发"两类边界。
内部自查是运行时护栏,外部Eval是开发期的标准线,定位不同,但都有用。
多人协作Skill管理
skills.sh提供了配套的Skill管理工具。如果要多人协作共享Skill,可以在代码平台上建一个仓库,根目录放skills目录,下面存放各个Skill。需要使用时运行相关命令交互式安装即可。
扩展视角:Skill是简化版的专用Agent
如果你熟悉ReAct或LangGraph这类框架,可以看看下面这张映射表来快速建立认知:
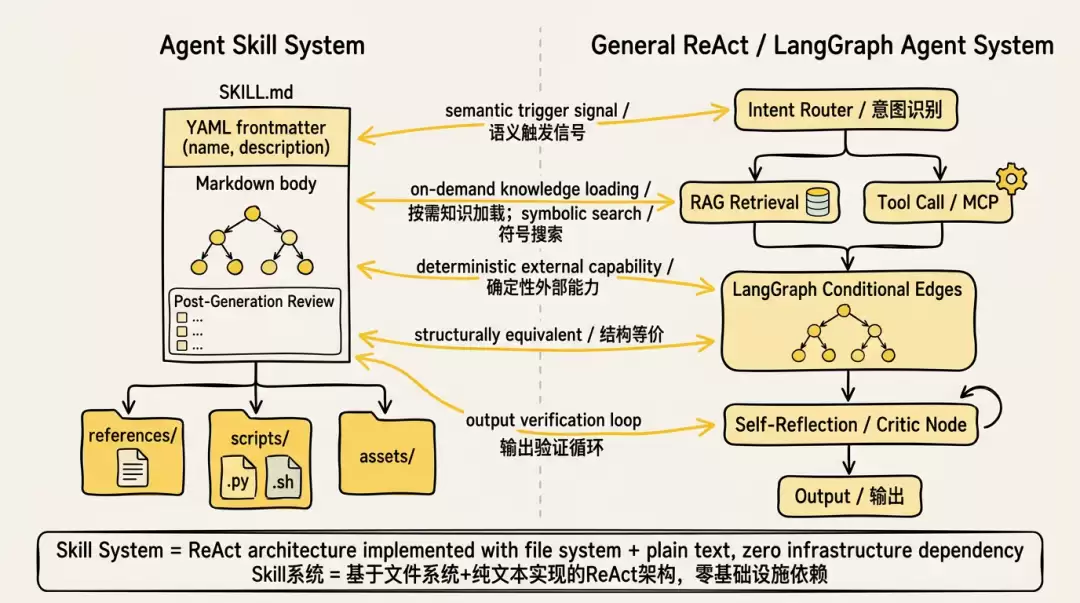

LangGraph的条件边由调度器执行,Skill里的决策树由模型阅读并模拟——前者是代码控制流,后者是自然语言编码的推理路径。这个差异决定了二者的适用边界。
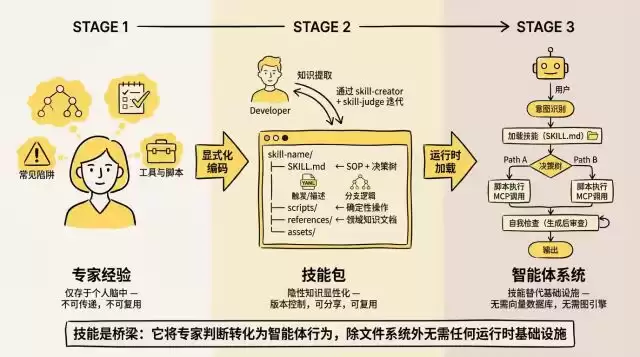
Skill体系的本质就是用文件系统结构加上文本决策树,来替代运行时服务(向量库、图引擎、路由服务),以零基础设施依赖换取极简部署。确定性当然不如专用Agent,但对大多数专业流程场景来说,已经够用了。
用Web概念来类比的话,基于LangChain等框架开发相当于IaaS/SaaS——自建Workflow、管理上下文、实现Tools、接入MCP。而Skill更像FaaS,Agent工具作为基座已经提供了Skill的发现与加载能力,以及基于Bash的文本操作、脚本执行能力,Skill专注于业务流程抽象就够了。当然,如果某个场景需要更高的准确性或SLA,也可以选择把Skill"翻译"为专用Agent:用MCP/Tools替代脚本,用流程编排替代决策树,用Observation节点替代自查。
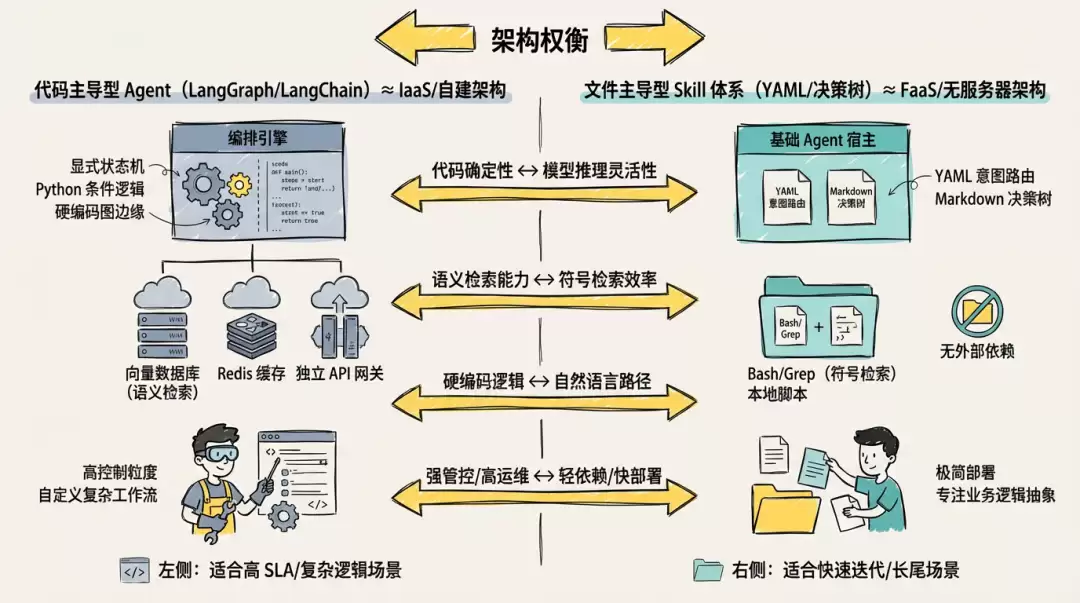
注意,FaaS不适合长连接、高频低延迟或复杂有状态事务。同样的逻辑,对流程确定性要求100%、或逻辑复杂到Context爆炸的场景,Skill也撑不住,还是要回到LangGraph去定制专用Agent。

总结
这篇文章系统梳理了Agent Skill从概念理解到迭代编写的完整实践路径。核心要点可以归纳为三点:
- 一是明确定位。Skill本质是轻量级的领域知识封装,适用于半自动化、专家经验导向的场景,而不是替代专用Agent框架。
- 二是遵循设计原则。采用三层渐进式加载架构,用决策树替代模糊判断,负向约束配合替代方案,并建立内部自查与外部Eval的双重验证机制。
- 三是迭代式开发。借助skill-creator和skill-judge等工具,通过"生成→评估→修订"的快速循环来提升Skill质量。
对于那些希望把业务经验沉淀为可复用AI能力的团队,Skill提供了一条零基础设施依赖、低部署成本的可行路径。但也要记住它的适用边界——当流程确定性要求100%或者逻辑复杂度导致上下文爆炸的时候,还是得选择LangGraph这类专用Agent框架来定向优化。最后想说的是,Skill的价值不在于技术本身,而在于能否将隐性的专家经验转化为显性、可执行、可验证的知识资产。

