
Kimi最强编程模型来了:Token消耗直降30%,过度思考有救了,附一手实测
6月12日,月之暗面正式发布并开源了Kimi K2.7 Code编程模型。这个参数量高达1.1万亿的模型,配备了256K上下文窗口,重点优化了长上下文编程中的指令遵循能力,以及长程编程任务的性能表现。一个很直观的变化是,它在长程任务中的“过度思考”倾向得到了大幅改善——平均token消耗减少了30%。
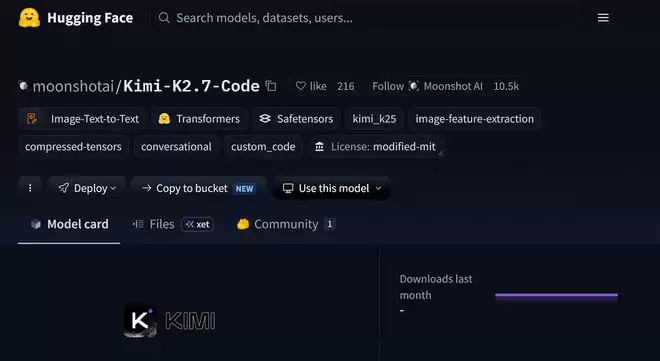
基准测试结果很有意思:K2.7 Code在多项编程和Agent测试中,相比K2.6实现了全面跃升,提升幅度从10%到31.5%不等。当然,跟GPT-5.5(xhigh)、Opus 4.8(xhigh)这些顶尖模型相比,还需要继续努力。
目前,这款模型已经在Kimi API开放平台(platform.kimi.com)上线。每百万token的标准输入输出价格跟K2.6保持一致,分别是6.5元和27元;不过命中缓存的输入价格微调了0.2元,变为1.3元。同时,Kimi Code Plan的默认模型也已经同步升级到K2.7 Code。需要注意一点:要发挥这个模型的最佳性能,必须打开思考模式。Kimi API和Kimi Code默认就是开启思考的,要是手动关闭,API端会直接报错,而Kimi Code则会回退到K2.6模型。
下周一,月之暗面还计划在Kimi API开放平台推出Kimi K2.7 Code高速版,并逐步向“抢鲜体验计划”成员和Kimi会员开放。这款高速版的输出速度大约是普通版的5-6倍——价格是2倍,常规编程场景下输出速度约180 Token/s,短上下文场景更可达260 Token/s。不过,它在Kimi Code Plan中的用量消耗也是普通版的3倍。
K2.7 Code上线后,智东西第一时间做了一次初步体验。测试以编程类案例为主,环境是VS Code搭配Kimi Code插件。
第一个实测案例,是一个轻量级任务:在单个html文件的维度下,复刻一个mac OS风格的桌面操作系统demo。这个任务主要考察的是K2.7 Code的前端能力。测试中能明显感受到,这代Kimi模型确实更“果断”了。项目不复杂,它没在思考上耗太多时间,很快就进入了开发工作。加上每次生成耗时也比较短,迭代起来相当顺畅。
最终的效果如下。逐步迭代后,这个demo的完成度相当不错,有完整的开机动画和基本功能,像便签、浏览器都能正常使用。
美中不足的是,多次让K2.7 Code修改它生成的SVG开机动画图,最终效果还是跟苹果的logo关联不大。算是小遗憾。

下一个任务,是让K2.7 Code开发一个“智能体小镇”复刻版。这个实验项目出自斯坦福大学和谷歌的合作,通过大语言模型驱动虚拟小镇中的智能体,模拟人类日常行为、社交互动及社会现象。开发之前,先让K2.7 Code写了一份简易的PRD文档。文档结构很清晰,既有对产品的一句话形象概述,也包含了市场背景、功能架构、非功能需求和技术方案等细节,能对后续开发起到很好的指导作用。
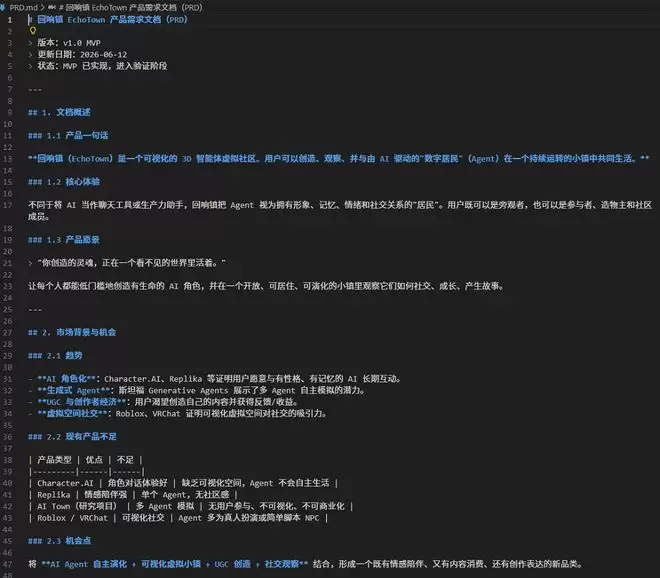
然后,让K2.7 Code在PRD文档指导下开发一个最小可行版本(MVP)。one-shot生成的结果还存在一些bug,画面无法正常渲染。继续让它改进,同时要求优化美术设计,并改造为可本地部署的方案。
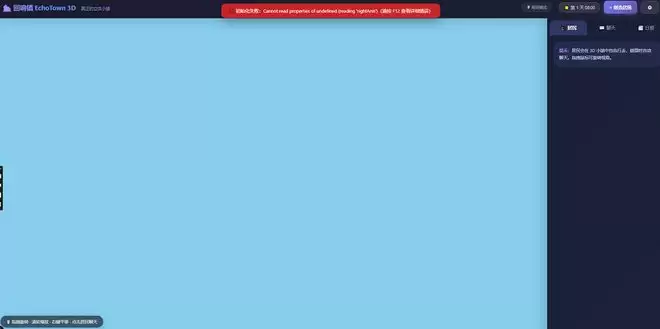
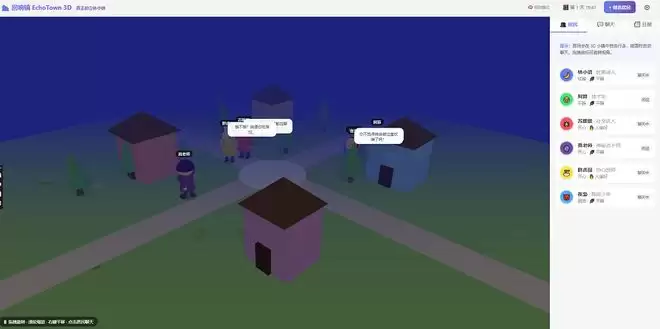
连续开发30多分钟后,K2.7 Code终于交付了一个完整可用的项目。虽然视觉上比较简陋,但基本功能都实现了,接入大模型后能正常和智能体对话。如果后续继续迭代,效果应该还会更好。
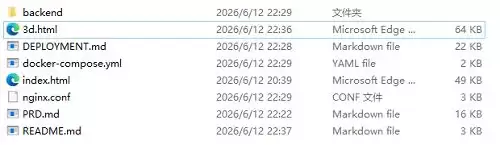
到项目文件夹检查后,可以看到K2.7 Code打造的项目文件架构清晰,分工合理。
结语:编程场景,速度同样决定体验
初步体验下来,K2.7 Code给人的感觉就是更“果断”了。过去那种在简单任务上反复自我质疑、长篇大论思考再动手的问题,少了很多。在生成速度方面,K2.7 Code的优化也贴合当下行业趋势。近期国内不少大模型厂商都在推高速模型,Kimi这次同步预告的5到6倍速高速版,算是顺应潮流。这种提速不是偶然的——在编程这种高频交互的场景里,速度本身就是一种关键的用户体验。