
RAG 优化 20 法:从"搜得到"到"答得好"
如果你用过RAG,肯定会经历这样一个过程:思路对、代码跑通了,但效果却让人头大。这就像一个图书馆管理员把书都搬过来了,但读者一问"我想知道怎么优化数据库"——管理员递过一本书《MySQL从入门到放弃》,实际上书里讲的是安装过程。
很多人在搭建RAG时,属于典型的"能做,但不好用"。文档切碎、Embedding调用、存储到向量库、再扔给大模型,一整套流程半天就能搞定。但一旦真正开始跑业务,问题就来了:搜出来的内容要么不相关,要么相关度太低;用户问个简单问题,它回答得像写小说;稍微抽象一点的问题,它就开始生成幻觉。
这其实不是你的错。RAG的入门门槛确实低,但"能跑"和"能用"之间,隔着一条完整的优化管线。
RAG的核心,不在于“让模型变聪明”,而是在于
确保正确的信息,在对的时机,落到对的位置上
下面,我们就把RAG的优化路径,从头到尾梳理一遍。一共20个实用技巧,按一个请求从数据入库到生成答案的完整生命周期拆解。
全流程一览:一个RAG管线的骨架
一个完整的RAG管线大致是这样的:
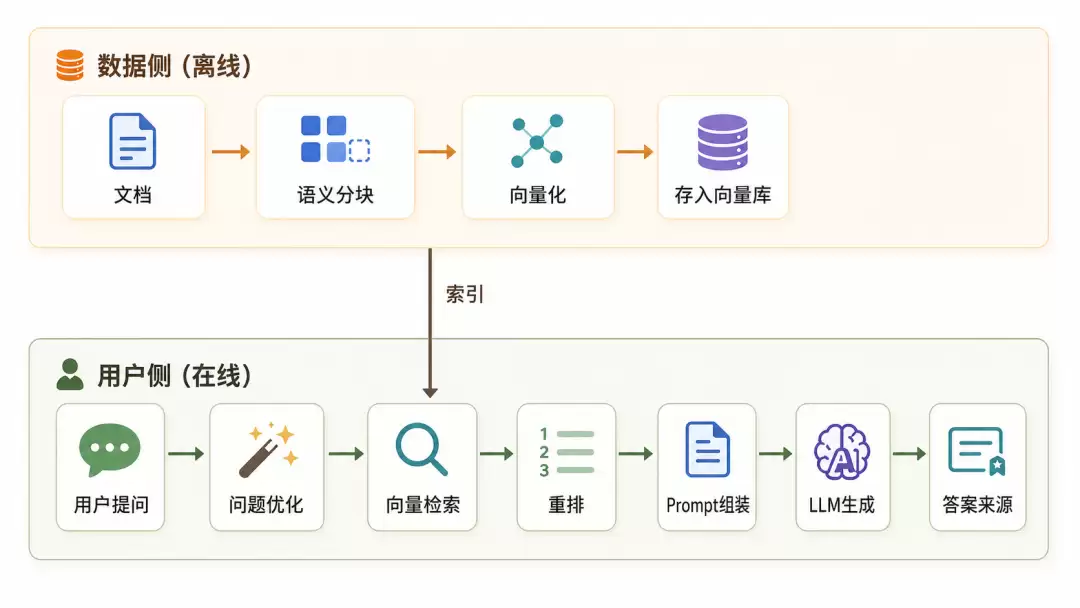
聊优化,不是堆算法。关键是每个环节之间如何协同。当一个阶段优化到位,下一个阶段的压力就会小很多。下面我们按五个阶段,逐个拆解。
一、数据入库:地基打不好,后面全是白忙
这个阶段的目标很简洁:
让正确的文档,在需要的时候能被找到
1. 语义分块:别用字符数切了,切出完整语义
很多入门教程会教你"每500字切一块"。这就像把一本书每10页拆下来订成一册,结果一个完整的论证被拦腰截断。
语义分块

一个完整的句子和一句被腰斩的话,检索的效果差别巨大。
2. 小块检索,大块喂给LLM:一个折中方案
把文档切成
小块
检索精度和上下文的完整性,两全其美。
3. 元数据过滤:先粗筛,再细搜
存文档时,顺手存上时间、作者、类型等元数据。检索时先做条件过滤(比如"只要2024年以后的"、"只要Python相关的"),再做语义匹配。一个简单的条件过滤,就能把搜索范围从百万级缩到千级。
算力省了,匹配精度也提升了。
4. 摘要索引:宏观问题先找大方向
长文档被切碎后,用户问"这本书讲了什么"时,任何一个片段都无法回答。
解决方案:入库前用LLM给每个长文档生成一个全局摘要,单独做向量。宏观问题先命中摘要,然后通过摘要与详细章节的关联,顺藤摸瓜找到细节。
先给方向,再给细节。
5. 图增强RAG(Graph RAG):不只搜内容,还搜关系
在入库时,把文档中的实体和关系抽取出来,存入知识图谱。比如“函数A调用了函数B”、“类C继承自类D”。
检索时
同时查向量库和图数据库
6. 文档反向提问:提前帮文档"写考题"
入库前,让LLM看着每一段文本,生成5个问题:“如果有人要查这段内容,可能会怎么问?”把这些问题和原文绑在一起存入向量库。
等于提前把各种可能的问法都做好了索引。
二、检索前:用户的提问,未必是最优查询词
用户提出的问题往往是口语化的、简略的,甚至带有歧义。直接用这类问题去碰书面语的文档,语义对不上是大概率事件。
7. 查询重写:帮用户把话"翻译"成检索语言
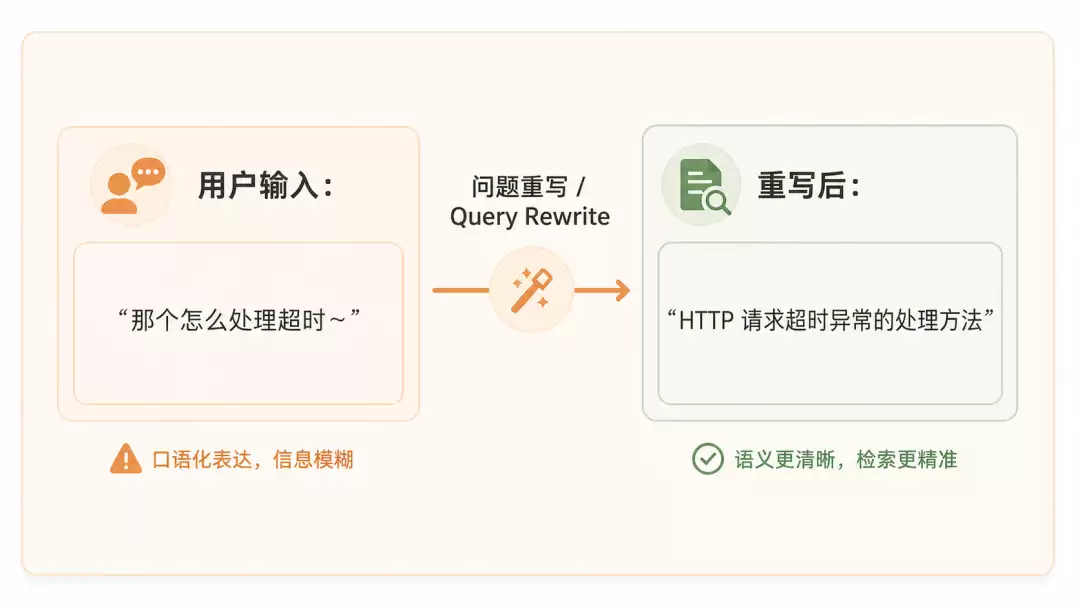
多一步LLM调用,但换来后续更少试错。
性价比极高。
8. 多路查询:一个问题,五种角度
把用户的问题扩展成3-5个不同角度的提问,分别检索,最后合并去重。
一种问法没命中的,另一种问法可能就命中了。
用广度换精度。
9. HyDE:先闭卷写个假答案,再用假答案找真文档
这是最有意思的方法,没有之一。
不做“问题→答案”的检索。而是让LLM先凭空写一个
假答案
“答案和答案”在向量空间里的距离,通常比“问题和答案”更近。
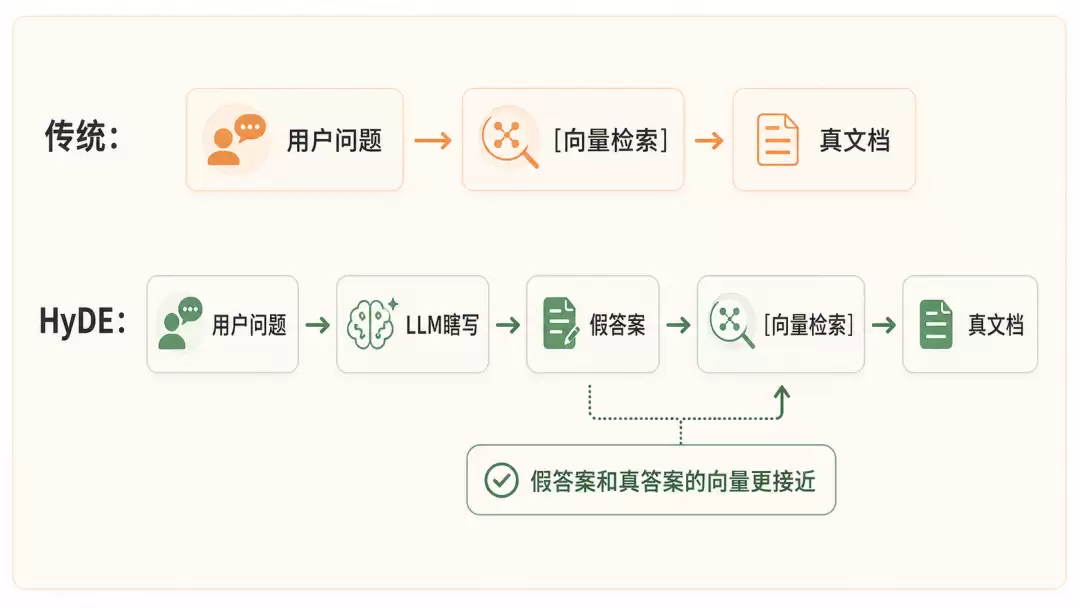
用"假的"去找"真的",这个思路本身就很有启发性。
10. 查询路由:不是所有问题都该走向量检索
设计一个路由器,根据意图分发:
- "今年第二季度的销售额是多少?" →
SQL数据库
- "这段代码为什么报错?" →
向量库
- "你好,今天天气怎么样?" →
直接给LLM
把不适合的问题强行塞给RAG,反而会产生更多问题。
先分类,再处理。
三、检索阶段:语义和关键词各有盲区
这是大多数实际工作中接触最多的阶段。核心矛盾很清楚:
语义搜索和关键词搜索的短板刚好互补。
11. 稠密检索:懂语义,却不懂术语
基于Embedding的语义搜索。你搜"轿车",它能找到"小汽车""私家车"。但遇到专业术语、缩写、代码函数名,它就懵了。
12. 稀疏检索:懂术语,却不懂语义
基于BM25的关键词匹配。你搜"OOM Killer",它不会漏掉"内存不足导致进程被杀"。但它搜不到,是因为你表达方式不同,不是它不认识这个词。
13. 混合检索 + RRF:两条腿走路
把稠密和稀疏的结果用
RRF(倒数排名融合)
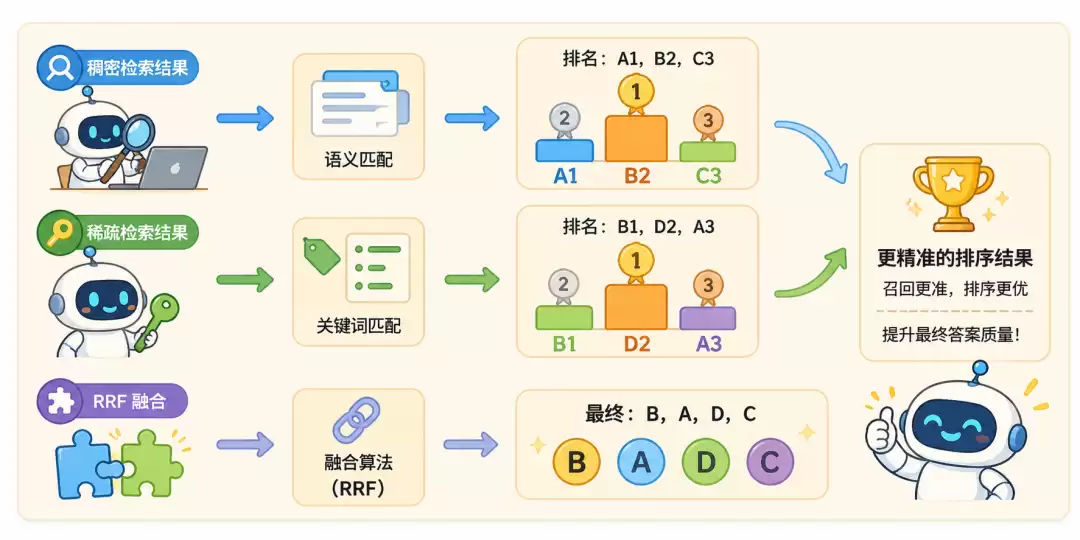
语义和关键词,两者都不可偏废。
14. 微调嵌入模型:让你领域的词汇被听懂
通用Embedding模型对你私有领域的理解不太尽如人意?那么就用自己领域的数据对它做一次微调。比如用内部代码文档去微调BGE,它就能理解项目中那些特有的函数名和术语。
四、检索后:最容易被忽视,但提升空间最大
很多人认为检索完了就结束了,直接把top_k结果丢给LLM。但检索出来的内容往往
有噪声、有重复、有废话
15. 重排(Reranking):关键时刻的双保险
在整个管线里,这是
性价比最高的一项优化
向量检索为了快,用的是“双塔模型”:查询算一个向量,文档算一个向量,然后比夹角。速度快,但精度有限。
重排模型用的是Cross-Encoder,将查询和文档
拼在一起逐字比对

召回对不意味着排序对。重排就是那个帮你把真正有用的内容排到第一位的"二次把关"。
16. 上下文压缩:帮LLM划重点
检索出来的文档段落可能很长,里面混着大量不相关的内容。用LLMLingua这类工具,剔除废话,保留核心信息。
既省Token,也能降低LLM"分心"的概率。
17. MMR:避免搜到的结果千篇一律
检索出5段文本,结果4段说的都是同一回事,上下文窗口就这样白白浪费了。
MMR(最大边际相关性)能保证结果
既相关又多样
五、生成阶段:有了好材料,还得学会"好好说话"
材料对了,最后一步就是让LLM不乱说。
18. Prompt工程:给LLM戴上紧箍咒
在System Prompt里加一句话,效果立竿见影:
"请严格基于提供的Context回答。如果Context中没有相关信息,请直接说'根据现有资料无法回答',不要编造。"
一句话就能挡住大量幻觉。
19. 自我反思:答完之后回头看一眼
让LLM生成答案后,再走一步:检查一下自己说的内容是否确实来自给定的上下文。如果没有,打回重写。
在关键业务场景下,这个额外的验证步骤很有价值。
20. 引用溯源:企业级RAG的标配
让模型在回答里标注来源,像论文一样标注引用。
这不仅仅是为了让用户能验证。
更重要的是,当模型知道自己的每句话都需要"对得上账"时,它会回答得更谨慎。
按场景选方案,别贪多
没有人会一次性把20种技巧全用上。根据场景选3-5种组合,效果通常就够好了:
通用知识问答:
语义分块 → 混合检索 → 重排
企业私有文档:
元数据过滤 → Graph RAG → 引用溯源
代码库问答:
查询重写 → 稀疏检索 → 重排
长文档分析:
摘要索引 → MMR → 上下文压缩
写在最后
回到开头的观点:
RAG的本质不是让模型更聪明,而是"让正确的信息在对的时机出现在对的位置"。
这让我想到了一个类比:RAG就像一个优秀的图书馆管理员。他不是把全馆的书都堆在读者面前说"你自己翻",而是在读者开口之前就洞察其意图,从百万藏书中精准抽出最相关的三页内容,放在他面前,并标好出处。
另一个感受是:
很多看似"高级"的方案,解决的其实是同一个问题:语义鸿沟。
所以,优化RAG不需要追求"把所有方案都用上",而是
理解你的场景里语义鸿沟最大的一环在哪里,然后对症下药。
记住这五条就够了:
- :语义分块优于字符切分;小块检索 + 大块投喂是黄金组合。
入库打好地基
- :查询重写 + HyDE假答案搭桥,是缩小语义鸿沟的关键。
检索前帮用户"翻译"
- :稠密 + 稀疏混合检索,语义和关键词都得兼顾。
检索时两条腿走路
- :重排是性价比最高的优化,初筛Top 20 → 精排Top 5。
检索后别偷懒
- :Prompt里加一句"不知道就说不知道",比任何花哨方案都管用。
生成时设好护栏
不是所有场景都需要20种全上。理解你的语义鸿沟在哪一环最大,选3-5种对症的组合,就足以让一个"能跑"的RAG变成"能用"的RAG。
