
CPU 跑得比 Whisper GPU还快的开源语音识别,本地部署
FunASR这个开源语音识别工具包,最近给我的冲击不小。官方有句原话挺狠的:它在CPU上的速度,比Whisper在GPU上还快。更关键的是,它把VAD、识别、标点、说话人分离、情感分析这些能力,全打包进了一个调用入口里。折腾过本地语音方案的人应该深有体会——从Whisper到SenseVoice,再到Voicebox,这些工具各有千秋,但总会在某个环节让人头疼:要么缺功能,要么对中文方言支持不完美,要么没法把说话人分开。FunASR这次迭代,算是把这些痛点一并端上桌了。
先做个框架说明。FunASR来自阿里通义实验室的modelscope团队,定位相当明确:
工业级、开源、一站式
| 零件 | 职能 | 默认推荐模型 |
|---|---|---|
| ASR(识别) | 把音频转成文字 | SenseVoice-Small / Paraformer / Fun-ASR-Nano |
| VAD(端点检测) | 找出哪段是人声,哪段是静音 | fsmn-vad |
| Punc(标点) | 给识别结果加标点 | ct-punc |
| Spk(说话人分离) | 区分谁在说话 | cam++ |
| Emotion(情感) | 识别开心/悲伤/愤怒等情绪 | emotion2vec+large |
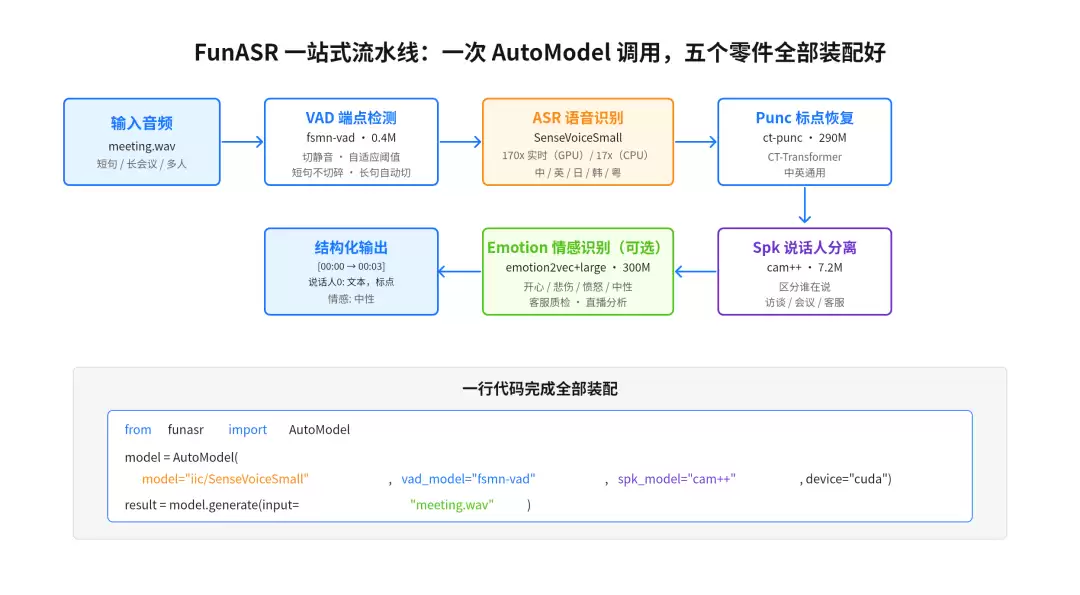
不同于Whisper那种“一个大模型包打天下”的玩法,FunASR把每个环节做成独立可替换、可升级的模块,组合起来后,在GPU上能跑出170倍的实时速度。下图能直观看到这条流水线的咬合逻辑:
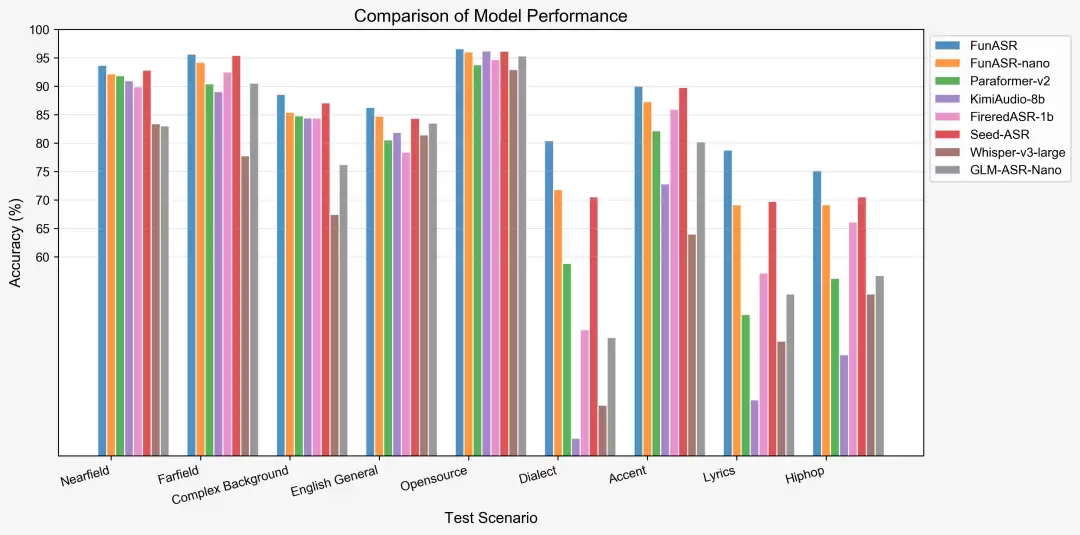
下面这张性能图则展示了Fun-ASR-Nano的表现——纵轴是错误率,越低越好;横轴是延迟,越靠左越好。左下角越靠近原点,意味着越能打:
总结下来,FunASR的核心能力集中在几个方向:
- :SenseVoice-Small在GPU上跑170倍实时(1小时音频,22秒内搞定),CPU上也能跑17倍实时——这对没有显卡的服务器来说,意义重大。
速度表现突出
- :Fun-ASR-Nano支持31种语言,Qwen3-ASR拓展到52种语言并可自动检测,GLM-ASR-Nano则专门优化了17种方言。
多语言与方言覆盖
- :VAD切分、识别、标点、说话人分离,一次调用全部完成,不用再手动拼合pipeline。
一站式处理
- :emotion2vec+large能输出开心、悲伤、愤怒等情绪标签,在客服质检和直播分析场景中很实用。
情感识别能力
- :paraformer-zh-streaming可跑WebSocket实时字幕,而paraformer-zh / SenseVoice适合离线长音频。
流式与离线双模式
- :一行命令
OpenAI兼容API
funasr-server --device cuda就能启动服务,接口形态与OpenAI Whisper API完全一致。 - :自带MCP服务可挂接Claude/Cursor,OpenAI兼容接口也能喂给LangChain、Dify、AutoGen这些框架。
Agent集成友好
安装
安装主线非常直接:
pip install funasr如果希望跑源码版本(便于修改或运行examples),也可以走clone路线:
git clone https://github.com/modelscope/FunASR.gitcd FunASRpip install -e ./环境需要满足Python ≥ 3.8、PyTorch ≥ 1.13以及torchaudio。如果想直接启动OpenAI兼容的服务,多装几个web依赖即可:
pip install funasr fastapi uvicorn python-multipartfunasr-server --model sensevoice --device cuda服务默认启动在localhost:8000。不想在本地配环境的话,官方也提供了Colab一键体验链接,在浏览器里就能跑公开样例或上传自己的录音。
使用
把官方README中最实用的几种组合集成到下面,基本能覆盖90%的落地场景。
中文会议录音转写(VAD + 识别 + 标点 + 说话人)
from funasr import AutoModelmodel = AutoModel( model="iic/SenseVoiceSmall", vad_model="fsmn-vad", spk_model="cam++", device="cuda",)result = model.generate(input="meeting.wa v")输出是带说话人标签和时间戳的结构化文本,会议纪要的后续处理可以直接拿这个当基础:
[00:00.4 → 00:03.8] 说话人0: 我们今天讨论一下 Q3 的计划[00:04.2 → 00:07.1] 说话人1: 好的,我有三个要点[00:07.5 → 00:12.3] 说话人0: 请讲,我们还有 30 分钟多语言/方言(Fun-ASR-Nano)
如果追求更高精度或需要支持中文方言,可以换成Fun-ASR-Nano:
from funasr import AutoModelmodel = AutoModel( model="FunAudioLLM/Fun-ASR-Nano-2512", vad_model="fsmn-vad", device="cuda",)result = model.generate(input="meeting.wa v")批量跑长音频时,套一层vLLM加速效果明显:
from funasr.auto.auto_model_vllm import AutoModelVLLMmodel = AutoModelVLLM( model="FunAudioLLM/Fun-ASR-Nano-2512", tensor_parallel_size=1,)results = model.generate(["audio1.wa v", "audio2.wa v"], language="auto")流式实时识别(边说边出字)
from funasr import AutoModelmodel = AutoModel(model="paraformer-zh-streaming", device="cuda")result = model.generate( input="chunk.wa v", cache={}, chunk_size=[0, 10, 5],)chunk_size=[0, 10, 5]是流式场景中常见的延迟配置,搭配WebSocket可以做直播字幕。
情感识别
from funasr import AutoModelmodel = AutoModel(model="emotion2vec_plus_large", device="cuda")result = model.generate(input="audio.wa v", granularity="utterance")直接输出情绪标签,做客服情绪监控非常方便。
部署成OpenAI兼容服务
funasr-server --model sensevoice --device cuda用curl验证一下:
curl http://localhost:8000/v1/audio/transcriptions -F file=sample.wa v -F model=sensevoice -F response_format=verbose_json接口形态与OpenAI Whisper API完全对得上,老业务从云端ASR平移过来基本零改造成本。
测评数据
FunASR官方给出的性能表相当硬核:
| 模型 | GPU 速度 | CPU 速度 | 对比 Whisper-large-v3 |
|---|---|---|---|
SenseVoice-Small | 170 倍 | 17 倍 | 快 13 倍 |
Paraformer-Large | 120 倍 | 15 倍 | 快 9 倍 |
| Whisper-large-v3-turbo | 46 倍实时 | ❌ | 快 3.4 倍 |
Fun-ASR-Nano | 17 倍实时 | 3.6 倍实时 | 快 1.3 倍 |
| Whisper-large-v3 | 13 倍实时 | ❌ | 基准 |
这组数据画成柱状图后,差距更直观:
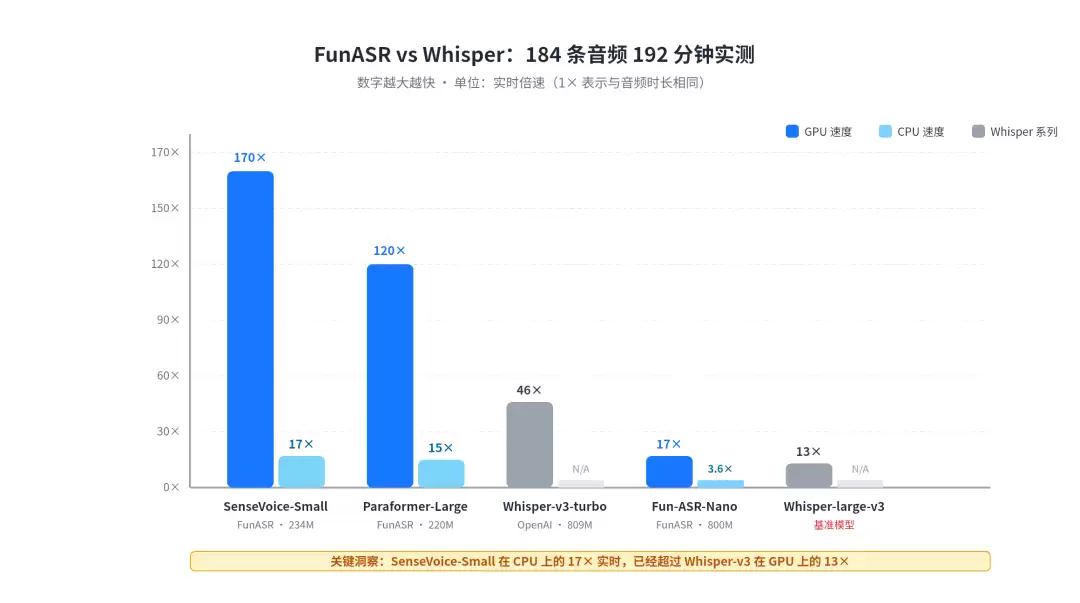
换个角度感受一下:1小时的会议录音,Whisper-large-v3需要4.6分钟处理,而SenseVoice-Small只需要21秒。这就是13倍的速度差距。
更值得注意的是,SenseVoice-Small在
CPU
GPU
横向对比一下常见方案:
| 维度 | FunASR | Whisper | 云端 API(讯飞/微软等) |
|---|---|---|---|
| 速度 | 170 倍实时 | 13 倍实时 | ~1 倍实时 |
| 说话人识别 | ✅ 内置 | ❌ 需要 pyannote | ✅ 额外付费 |
| 情感识别 | ✅ | ❌ | ❌ |
| 语言数 | 50+ | 57 | 因服务而异 |
| 流式识别 | ✅ WebSocket | ❌ | ✅ |
| 私有部署 | ✅ MIT | ✅ MIT | ❌ 仅云端 |
| 费用 | 免费 | 免费 | ¥0.04/分钟起 |
| CPU 可用 | ✅ 17 倍实时 | ❌ 太慢 | 不适用 |
优点非常明确:
- 一站式体验:VAD、识别、标点、说话人分离、情感全自带,省去了手动组装多个开源仓库的麻烦。
- 中文支持最强梯队:Paraformer系列基于阿里达摩院8年积累,方言、口音、噪声鲁棒性远超Whisper。
- CPU友好:没显卡也能用,部署门槛极低。
- 服务化彻底:funasr-server直接输出OpenAI兼容API,原本接Whisper的SDK可以无缝迁移。
- Agent集成友好:MCP服务、OpenAI API、Gradio Demo全部配齐。
当然,也有一些不太顺手的地方:
- 模型数量多,新手第一次接触容易迷路——建议直接看官方的模型选择指南。
- SenseVoice-Small虽然快,但参数量234M,与Whisper-large的1550M相比,体量小不少,复杂英文长音频的识别精度还是Whisper系列略有优势。
- Fun-ASR-Nano走vLLM加速效果最好,但vLLM自己的安装有一定门槛。
- 文档体系存在中英混排现象,部分API参数需要去examples目录里翻。
部署选型建议
针对不同场景,整理了一份简单的决策表:
| 场景 | 推荐模型 | 备注 |
|---|---|---|
| 中文会议录音转写 | Paraformer-zh + cam++ + ct-punc | 8年迭代的工业级模型 |
| 多语言/中文方言 | Fun-ASR-Nano(800M) | 31种语言包含方言 |
| 全球52语言 | Qwen3-ASR(1.7B) | 自动语言检测 |
| 直播实时字幕 | paraformer-zh-streaming | 流式WebSocket |
| 情感分析/客服质检 | emotion2vec+large | 单独运行 |
| 没显卡的服务器 | SenseVoice-Small(CPU) | CPU跑17倍实时 |
| 老Whisper业务平迁 | funasr-server + sensevoice | OpenAI兼容API |
总结
很多语音识别开源项目,要么是Whisper套壳,要么只跑英文,要么只能跑离线或GPU、只做识别。FunASR的路径是把整个语音pipeline工业化,同时在方言支持、流式处理、说话人分离、情感识别、Agent接入这些维度上全部补齐。
有几个判断供参考:
- 如果你是做国内语音应用、中文会议纪要、客服质检、直播字幕的——。
直接上手,没什么好犹豫的
- 如果之前用Whisper但被速度卡住——。
用funasr-server把它当成Whisper兼容API,性能会带来明显提升
- 如果你想做AI Agent听懂语音输入——。
MCP服务配合Claude/Cursor已经是现成的方案
- 如果只是英文场景、单GPU离线转写——Whisper也够用,看个人偏好。
