
拒绝API焦虑!手把手教你白嫖AIPing赠金,全场通用
日常开发中,大模型调用的成本与路由管理确实是个老生常谈的痛点。维护多个API Key、在不同模型供应商之间来回切换、还有那些蹭蹭上涨的Token开销——这些琐事往往把本应聚焦在业务上的精力给消耗殆尽。
近期,市场上有一款名为AIPing的一站式AI评测与API服务智能路由平台正在开展分享裂变活动。原本对这种活动并不太感冒,但仔细评估了其赠送金额的通用性以及平台本身的路由能力之后,不得不承认这确实是一个值得同行关注的高性价比方案。今天就把这份复盘分享出来,供大家参考。
一、裂变机制与核心价值:真正意义上的“全栈通用”
市面上多数平台的赠金活动,往往限制在冷门模型或极短的时效内。但AIPing这次的机制相对务实:
- 双向奖励:通过专属链接注册,邀请人与被邀请人各得10元赠金。
- 全场通用:这笔赠金没有模型限制,可用于平台接入的所有大模型。

这其中的关键点在于
“全场通用”
二、技术实操:在Claude Code中配置AIPing路由验证GLM5.1
为了验证GLM5.1的代码能力以及AIPing路由的稳定性,选择在Claude Code命令行环境下进行接入测试。AIPing兼容OpenAI的接口格式,这使得接入过程极为精简。
1. 获取API Key
在AIPing控制台完成注册后,直接在API密钥板块创建新的Key。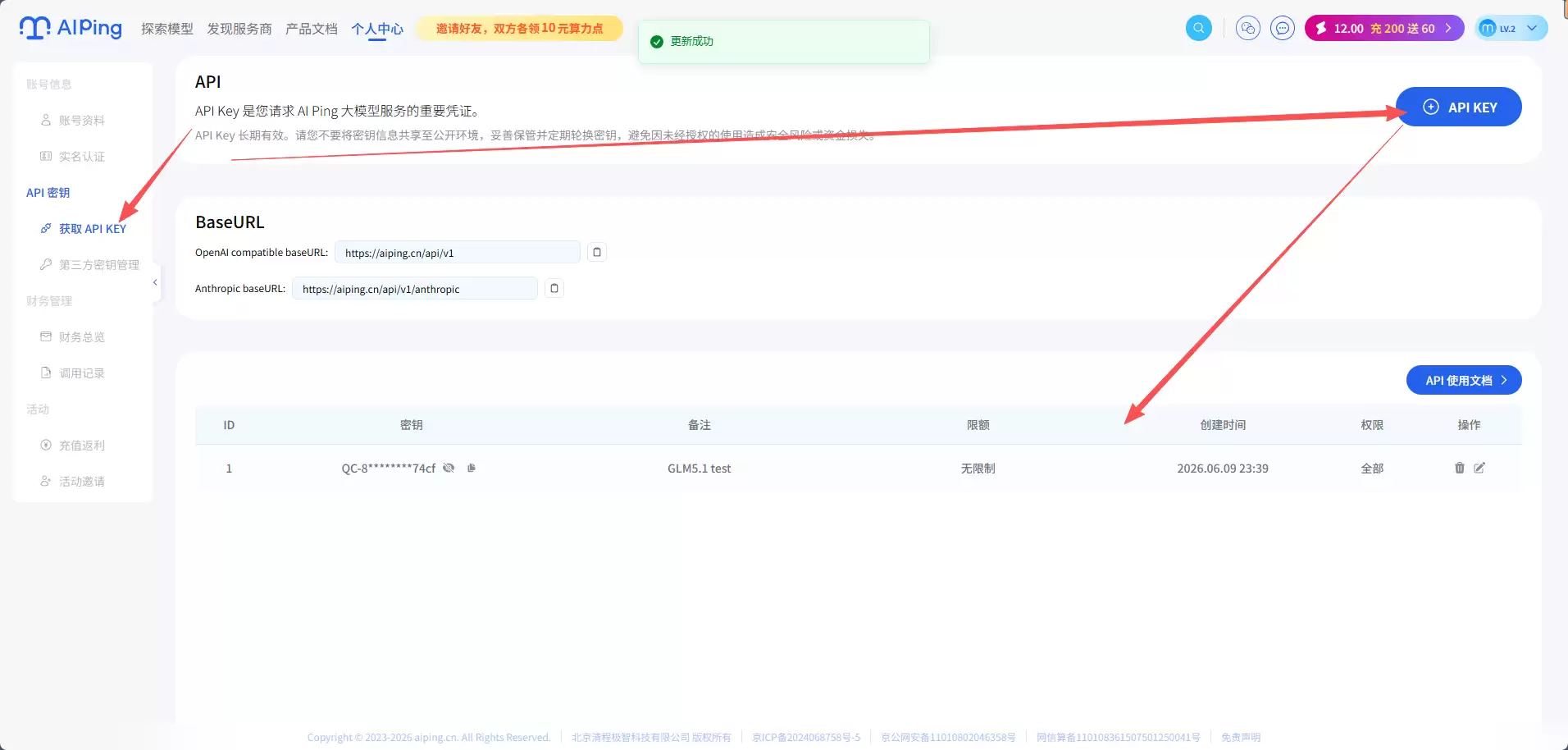
2. 终端环境配置
在Claude Code或基于OpenAI SDK的命令行工具中,只需修改Base URL和API Key即可完成路由切换,无需更改原有的代码结构。
修改settings.json配置文件中,包括前文获取的API Key、URL以及从AIPing模型列表获取的模型ID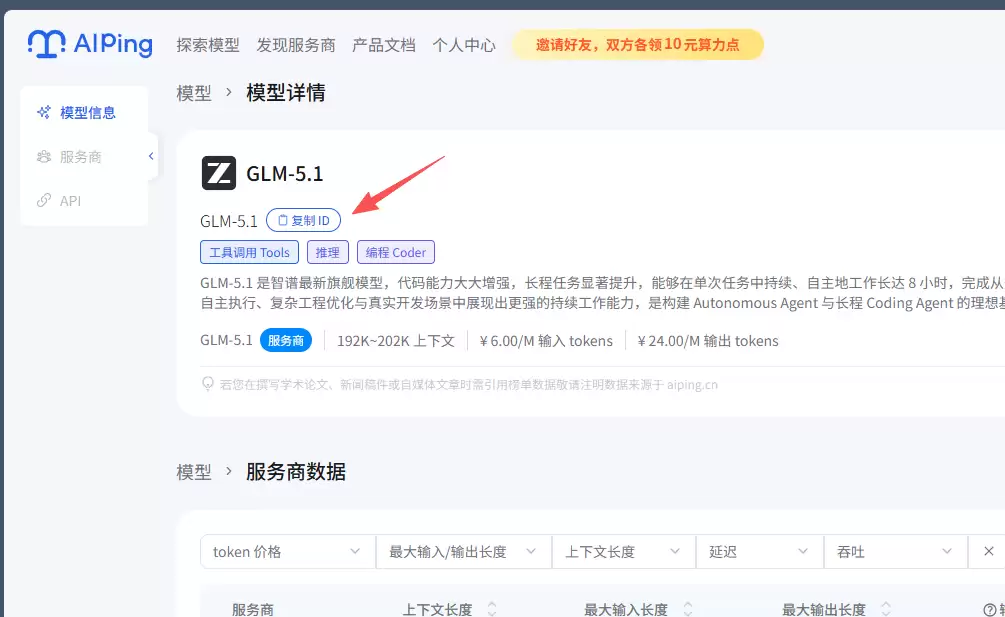
3. 代码能力验证
使用GLM-5.1模型,要求其编写一个基于Python的异步网页抓取脚本,并加入异常处理与重试机制。
import asyncioimport aiohttpimport loggingfrom dataclasses import dataclass, fieldlogging.basicConfig(level=logging.INFO,format="%(asctime)s [%(levelname)s] %(message)s",)log = logging.getLogger(__name__)@dataclassclass FetchResult:url: strstatus: int = 0html: str = ""error: str = ""@dataclassclass RetryPolicy:max_retries: int = 3backoff_factor: float = 1.0# seconds, multiplied by attempt indexasync def _fetch_one(session: aiohttp.ClientSession,url: str,retry: RetryPolicy,sem: asyncio.Semaphore,) -> FetchResult:async with sem:for attempt in range(retry.max_retries + 1):try:async with session.get(url, timeout=aiohttp.ClientTimeout(total=15)) as resp:html = await resp.text()log.info("OK %s (%d)", url, resp.status)return FetchResult(url=url, status=resp.status, html=html)except aiohttp.ClientError as e:error = f"ClientError: {e}"except asyncio.TimeoutError:error = "TimeoutError"except Exception as e:error = f"Unexpected: {e}"if attempt < retry.max_retries:wait = retry.backoff_factor * (attempt + 1)log.warning("Retry %d/%d for %s (%s), waiting %.1fs",attempt + 1, retry.max_retries, url, error, wait)await asyncio.sleep(wait)else:log.error("Failed after %d retries: %s (%s)",retry.max_retries, url, error)return FetchResult(url=url, error=error)async def fetch_all(urls: list[str],*,concurrency: int = 5,retry: RetryPolicy | None = None,) -> list[FetchResult]:retry = retry or RetryPolicy()sem = asyncio.Semaphore(concurrency)async with aiohttp.ClientSession() as session:tasks = [_fetch_one(session, url, retry, sem) for url in urls]return await asyncio.gather(*tasks)async def main():urls = ["https://httpbin.org/get","https://httpbin.org/delay/2","https://httpbin.org/status/404","https://httpbin.org/status/500","https://nonexistent.invalid",# will fail, triggers retry]results = await fetch_all(urls, concurrency=3, retry=RetryPolicy(max_retries=2, backoff_factor=1.0))print("n--- Results ---")for r in results:if r.error:print(f"[FAIL] {r.url} -> {r.error}")else:print(f"[OK] {r.url} -> status={r.status}, length={len(r.html)}")if __name__ == "__main__":asyncio.run(main())
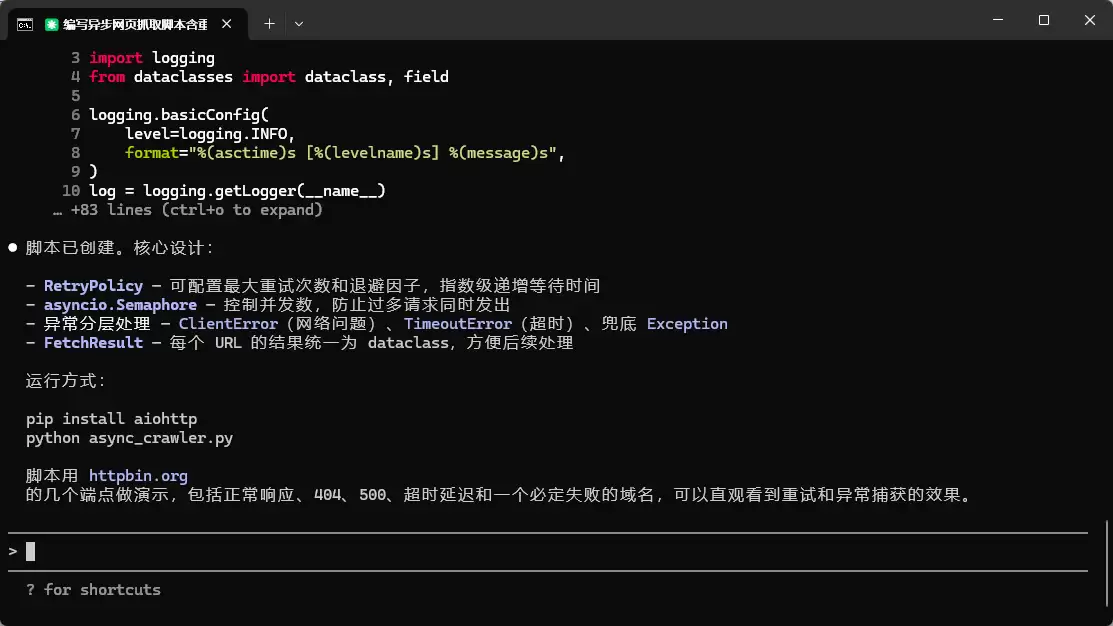
测试反馈:
- 代码质量:GLM5.1给出的代码结构清晰,准确使用了
aiohttp与tenacity库,异步逻辑与重试装饰器的结合符合最佳实践,几乎无需修改即可直接集成到项目中。 - 响应速度(重点):值得特别关注的一点。在终端里回车后,几乎是无缝衔接,GLM5.1的代码流就开始倾泻而出。首字延迟(TTFT)极低,生成过程中的Token吐出速度非常均匀且迅捷。这种丝滑的体感,在直接调用原生API遭遇网络拥堵时是很难得到的,极大提升了命令行下的交互效率。
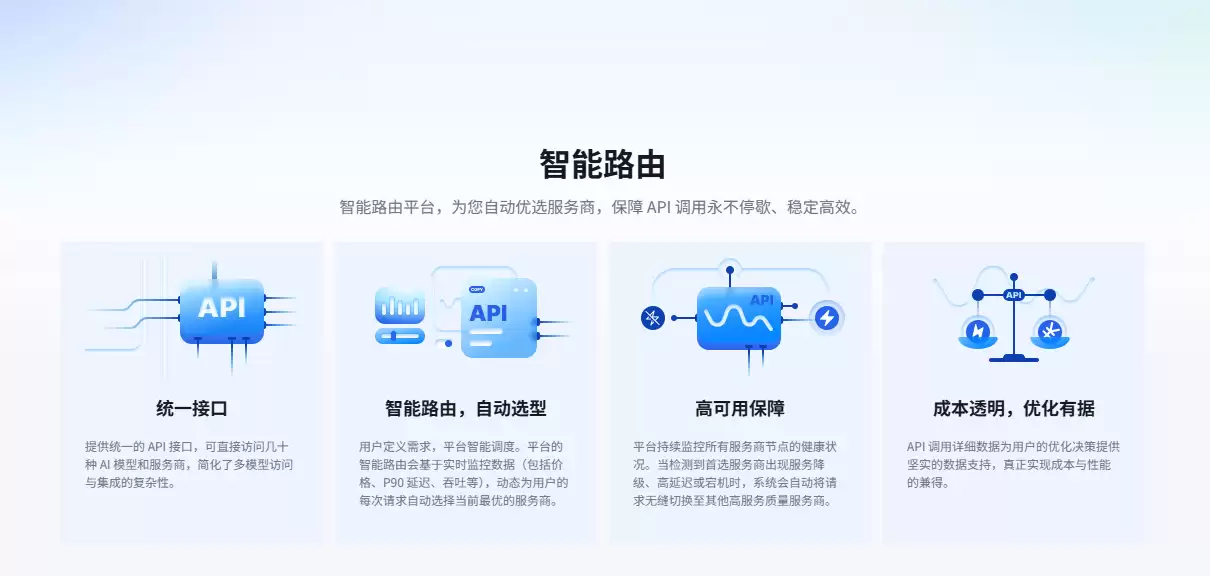
三、平台价值:智能路由如何解决延迟与稳定性痛点?
实测下来,AIPing接入GLM5.1的响应速度之所以快,并非玄学,而是其底层的智能路由机制在发挥作用。结合官网的架构介绍,其平台价值主要体现在以下几个技术维度:
- 动态路由与负载均衡:AIPing不是简单的API中转站。它在底层实时监测各服务商节点的延迟与可用性。当发起对GLM5.1的请求时,平台已经为你匹配了当前网络环境下延迟最低、带宽最充裕的链路,有效避开了单一直连节点的拥堵,这正是其标榜“更快”的底气。
- 高可用与故障转移:在长代码生成场景中,最怕API中途断开。AIPing的路由能够在感知到某节点异常时,快速切换至备用节点,保证生成任务的连续性,实现“更稳”。
- 聚合管理的成本优势:极简路由降低了维护多Key的心智负担,而聚合调用的计费模式往往比直连官方更具性价比。配合此次裂变赠金,非常适合中小项目做早期冷启动与压力测试。
总结
对于注重效率与成本控制的开发者而言,AIPing提供的智能路由方案本身就是一个值得引入的工具,而此次全栈通用的裂变赠金,则提供了一个零成本验证GLM5.1等顶尖模型代码能力的绝佳契机。
技术探索本就不应被高昂的API成本掣肘,好工具与好模型,值得被更高效地利用。
