
OpenAI昨夜悄悄做了一件事:AI Memory整个赛道,一夜被重写
6月4日,美东时间凌晨,OpenAI用一种极其低调的方式——没有发布会、没有keynote,甚至连官方推文都没预热——悄悄上线了一项更新。这事儿搁以前肯定要闹出大动静,但这次偏偏静悄悄的。然而,几小时内,硅谷的AI圈子里已经炸了锅。
有人欢呼说,"ChatGPT终于像个真助手了"。但在AI Memory这个赛道,所有人的心里都清楚:
2026年6月4日,是"通用AI记忆API"作为一个独立赛道死亡的日子。
为什么这么说?这篇文章,我们来拆开看。
写在前面
先别急着下结论。我们先把事实理清楚:OpenAI到底发布了什么?那个被99%的报道忽略掉的"真正的冲击波"是什么?为什么这一夜,"做C端记忆"的创业公司基本可以开始考虑转型了?但又为什么,
真正聪明的AI Memory公司反而被这一夜成全了
以及——最重要的——
Memory主权
一、先把发生的事讲清楚
OpenAI官方博客把这次更新定调为:"
a significantly more capable and compute-efficient memory architecture built on top of dreaming
拆开来看,核心是五个事实:
1️⃣ 这不是新功能,是第三代架构
OpenAI的memory能力迭代路径其实很清晰:
- ——用户主动说"记住这个",ChatGPT像个会记笔记的助理。
2024年4月:Sa ved Memories(保存型记忆)
- ——ChatGPT开始能引用对话上下文,第一次有了"后台同步"的能力。
2025年4月:Dreaming v1 上线
- ——从底层架构重写,瞄准的是"数亿用户 + 多年时间跨度"这个终极场景。
2026年6月:Dreaming V3正式发布
2️⃣ 推理算力被压低约5倍
这是这次更新真正的核武器。正是这5倍的算力压缩,让OpenAI第一次把dreaming扩展到了免费用户——之前迟迟不下放,根本原因就是成本问题。
3️⃣ Plus / Pro 用户的记忆存储容量直接翻倍
付费用户可以记得更多、更久,这是明面上的升级。
4️⃣ 新增"Memory Summary Page"——用户可见的记忆摘要页
这个被严重低估了。用户可以
审阅、编辑、更新
5️⃣ 时间感知(Time-awareness)
你7月要去新加坡,旅行结束后,ChatGPT会自动把记忆从"将要去新加坡"改写成"2026年7月去过新加坡",然后切回基于你本地位置的推荐逻辑。听上去简单,但这实际上是
temporal reasoning + entity state machine + event closure detection
二、99%的报道都漏了:5倍降本才是真正的冲击波
很多媒体把发布重点放在"免费用户也能用记忆"上。这个角度对C端用户没错,但作为创业者或投资人,必须看到那个真正要命的东西:
5倍算力压缩
为什么?
过去18个月,所有AI Memory创业公司的核心叙事,本质上都是同一个故事:
"OpenAI / Anthropic 的原生memory算力贵、不scalable、对企业不友好。我们用更聪明的算法,帮你压缩token、降低成本、提高效率。"
Mem0去年4月发布的新算法,宣称把单次检索token压缩到大约7K。这就是所有这类公司的护城河——他们比基础模型厂商更省钱。
但2026年6月4日凌晨之后,这个故事的根基塌了。OpenAI用一句话证明:
memory infra的unit economics问题,他们自己解决了,而且解决到能给数亿免费用户用的程度。
这意味着什么?任何一家以"我帮你省X% memory算力"为核心卖点的AI Memory公司,从今天起,估值倍数至少要打个对折。
这种打折不会等到投资人主动重估。它会在下一轮融资的pitch现场直接上演:
"您说能省80% token?OpenAI自己内部刚降了5倍算力,下放给免费用户了。您的差异化在哪里?"
这将是2026下半年,所有AI Memory公司FA会议上必然出现的最尴尬的问题。
三、Memory Summary Page:被低估的"产品分水岭"
Dreaming V3里有一个细节,重要到值得单独拎出来讲:
用户第一次能"看见"自己被AI记住了什么。
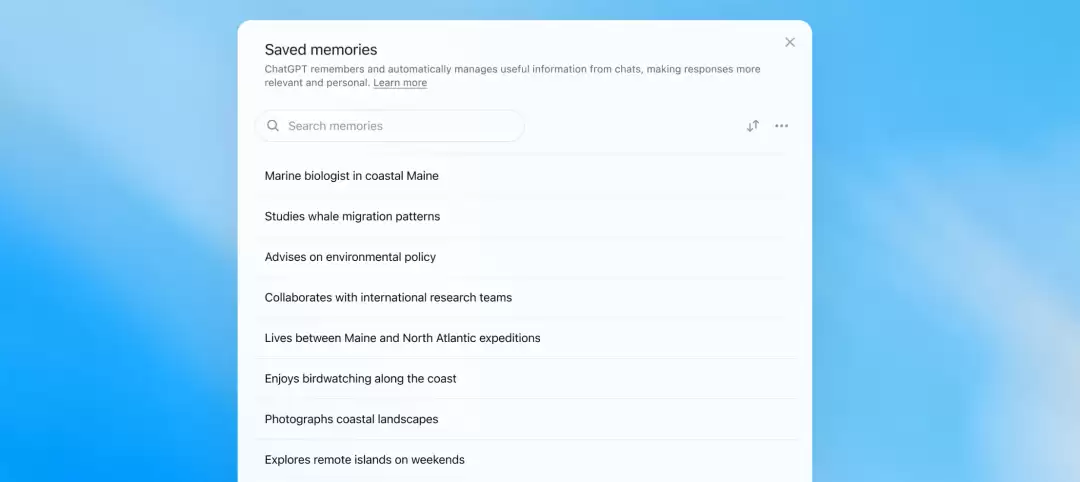
过去两年,所有AI产品的memory都是黑盒——AI说它记得你,但你不知道它记得什么、记错了什么、什么时候会用、什么时候不用。
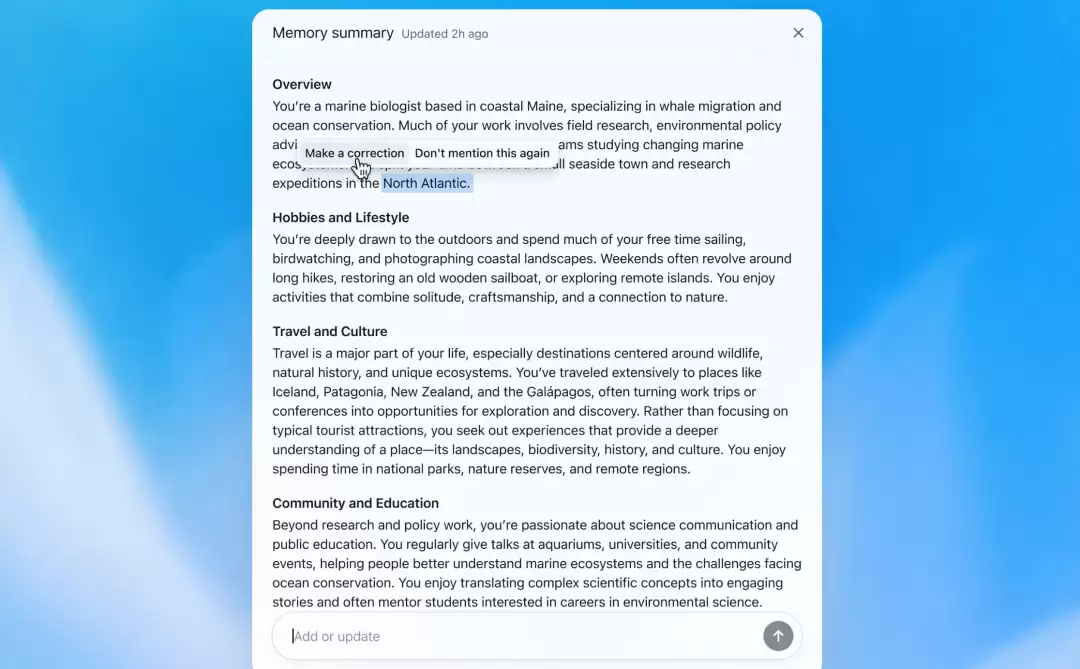
Memory Summary Page彻底改变了这件事。它是一个
用户可见、可编辑、可指令
这个设计的意义,相当于:
- 当年Gmail把"标签和过滤器"从后台变成可见UI
- 当年Notion把"数据库"从程序员玩具变成普通用户产品
- 当年TikTok把"算法推荐"从隐性逻辑变成"For You页"
它们都做了同一件事——把一种隐性的技术能力,变成用户能直接接触和管理的产品对象。
而memory,从今天起也是这样一个对象了。这件事最大的影响是什么?
用户开始把"AI的记忆"当成一种可以拥有、管理、携带的资产。
OpenAI替整个AI Memory赛道把用户教育做了。这对独立Memory公司,既是威胁,也是机会。
四、最被忽略的战略信号:OpenAI vs Anthropic,同一个名字下的两条路线
注意一个很反常的现象:
OpenAI和Anthropic都在2026年发布了叫"Dreaming"的功能。
但更值得注意的是——
两家用同一个名字,走的却是完全相反的路
| 维度 | OpenAI Dreaming V3 | Anthropic Dreaming |
|---|---|---|
| 发布时间 | 2026年6月4日(正式发布) | 2026年5月(研究预览) |
| 目标场景 | C端聊天,数亿用户 | B端Agent,长任务 |
| 部署形态 | 用户可见摘要页 | 后台异步任务 |
| 输入规模 | 跨会话历史 | 高达100份transcript批量摄入 |
| 输出 | 用户编辑型记忆 | Agent决策型记忆 |
| 商业意图 | C端订阅+免费用户lock-in | B端Managed Agents付费 |
OpenAI在抢消费者的认知资产,Anthropic在抢企业的Agent state。
对所有AI Memory赛道的创业者,这意味着什么?
"个人 + 企业"双面定位的memory产品,从此被OpenAI和Anthropic分别从两端挤压。
五、谁被这一夜杀死,谁被这一夜成全
把上面所有信号串起来看,AI Memory赛道在2026年6月4日之后,被清晰地分成了
死区
活区
❌ 死区:今天起再也融不到钱的方向
- ""的通用API——OpenAI自己做完了。
给C端AI聊天加长期记忆
- ""的轻量memory层——ChatGPT原生功能,免费。
记住用户偏好
- ""的纯技术差异化——OpenAI的time-awareness已经内置。
解决记忆staleness
- 任何""的C端故事——你的对手是数亿用户的免费产品。
我们比ChatGPT记得更好
- ""的纯效率叙事——OpenAI自己刚降5倍。
我帮你省X% memory算力
✅ 活区:被这一夜反向成全的方向
第一条路:跨平台 / 跨模型 / 跨厂商的可携带记忆
OpenAI的Dreaming锁在ChatGPT里,Anthropic的Dreaming锁在Claude里,Google有自己的Gemini Memory。三家越发力,"用户的memory被锁死在不同平台"这个痛点就越被放大。谁帮用户把记忆从ChatGPT导出到Claude、从Claude同步到Cursor、从Cursor带去AI玩具,谁就拿到了下一波的入场券。
第二条路:企业级多租户memory + 审计 + 合规 + 权限
OpenAI Dreaming V3明显是
consumer-grade设计
第三条路:垂直行业ontology memory
金融、医疗、法律、教育、政务,每个行业的本体(ontology)都是几十人团队做十几年的积累。OpenAI没有动机也没有耐心做这种"脏活"。这是独立Memory公司唯一能比基础模型厂商更深的地方。
第四条路:具身智能 + 物理世界memory
OpenAI Dreaming完全是数字对话场景。
机器人、AI玩具、自动驾驶、AR眼镜的"物理世界记忆"是空白市场
六、真正的下一个战场:Memory主权
讲到这里,值得抛出一个观点,它会是2026下半年所有AI行业讨论的核心命题:
AI Memory赛道的下一个战场,不是技术,是主权。
什么叫Memory主权?它包含三层含义:
第一层:用户对自己记忆的所有权
不应该被任何一家AI平台绑架
第二层:企业对组织记忆的控制权
不应该和我用的AI工具绑定
第三层:国家/地区对数据记忆的合规权
不应该由某一家美国AI公司单方面决定
Memory主权的本质判断很简单:当模型每3个月被替换、Agent框架每半年迭代、Token价格每季度重写,企业能持续累积、持续增值的唯一资产,就是认知记忆。这种资产,必须独立于任何一家AI平台而存在。
这是OpenAI Dreaming V3发布之后,所有做AI产品的人都必须重新想清楚的问题。回到开头那句话——
2026年6月4日,是"通用AI记忆API"作为独立赛道死亡的日子。
"Memory主权"作为新赛道诞生的日子。
OpenAI用Dreaming V3替整个行业把用户心智教育做完了。从今天起,每一个ChatGPT用户都会逐步建立起"记忆是我的资产"的意识。这种意识一旦形成,就再也回不去了。而独立的Memory公司,从今天起唯一能做的、也是最应该做的一件事,就是:
站在"用户记忆主权"这一边。
站在"用户记忆主权"这一边。
让用户的认知资产,不被任何一家平台绑架。
让用户的认知资产,不被任何一家平台绑架。
模型会变化,Agent会演进,但
