
ContextBucket:Agent 的"无限"记忆与工作区底座
大模型Agent,正在告别demo阶段。过去一年,它们越来越多地出现在生产线、运营后台、客服工单处理等真实业务场景里——不再是聊几句就关掉的玩具,而是常驻系统里运行的长效进程。随之而来的是一个看似基础、却长期被绕开的问题:Agent的上下文——记住的事实、操作过的文件、产出的中间结果——到底应该放在哪?
前期工程实践基本是“拼装”:记忆挂向量库或Mem0,文件落本地磁盘或对象存储,多租户隔离自己实现一套。demo阶段跑得通,一上规模立马暴露三类问题:记忆随会话消失、文件无法跨端共享、权限和审计缺失。维护这条上下文链路的工程量,正在反超Agent的业务逻辑本身。根因不在某个组件,而在于Agent的“脑子”和“手”被强行拆在两套独立的存储体系里。具体来看,有三类断层非常典型:
记忆断层
存在向量库或本地SQLite的记忆,换设备就丢,窗口压缩后召回失真。只靠向量检索,既不准也不省——召回噪声大,关键决策常被相似讨论淹没。
工作区断层
代码、配置、项目文档、运行产物全在本地磁盘。换台机器就全丢了,团队之间没法共享。自己搭FUSE加对象存储的拼装方案,运维成本又太高。
治理断层
多个Agent跑在同一台机器上,数据互相干扰。多用户、多团队没有原生隔离。迁移、审计、配额全靠人工处理,开发者最后不是在开发Agent,而是在维护一条上下文管道。
现实场景更为直观:换台电脑,本地的代码和配置就没了;几个同事各跑各的Agent,记忆和文件散落各处,复用无从谈起;同时跑多个Agent时,记忆互相串、文件互相覆盖更是家常便饭。三类断层叠加,使得Agent的记忆和工作区始终无法收敛到同一个底座——这正是ContextBucket要回答的问题。
产品能力:一个底座,两种能力
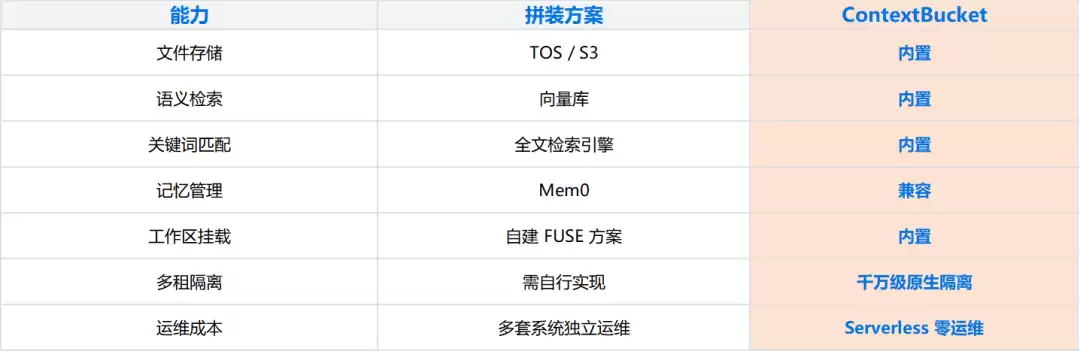
ContextBucket是火山引擎提供的托管服务,在同一套服务层里整合了文件存储、记忆管理、混合检索、多租隔离和Serverless弹性。Agent通过插件一键接入就能获得全部能力,不需要再分别对接向量库、对象存储和记忆中间件。每个Agent或用户对应一个ContextSet(逻辑隔离单元),记忆与工作区文件在同一个ContextSet下共享凭证和接入点。下方以OpenClaw为例,展示了ContextBucket替代的全部组件:
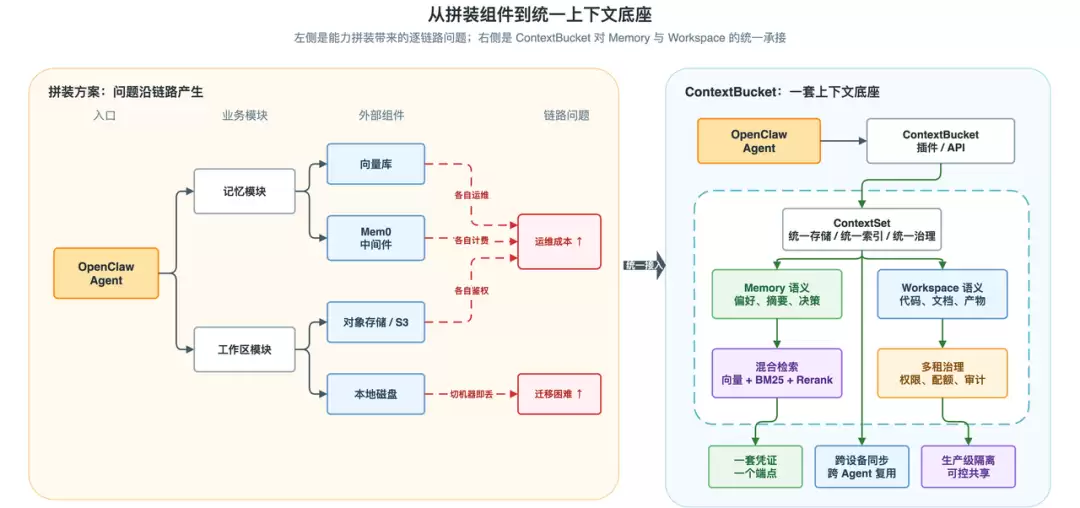
下图给出ContextBucket的整体架构,自上而下分为接入层、能力层和存储层:

记忆:记得准、找得到、带得走
记得准:智能提取,只记事实
OpenClaw的对话流里夹杂着大量过程噪声——反复讨论、方案对比、代码试错、被否决的提案。如果这些内容都被等量沉淀进记忆库,污染是必然的,检索精度也会随之下降。
ContextBucket在写入侧做一次过滤:只自动识别并提取对话中的关键事实——需求决策、技术结论、用户偏好,过程性的方案讨论和代码试错不再等量保存。“昨天”、“上周”这类相对时间表达会做特殊处理,避免后续召回时产生歧义。
举个例子:你让OpenClaw帮忙重构一个微服务,聊了整整两天——讨论了三种接口拆分方案,权衡后选了按领域拆分;评估了gRPC和REST,最终决定核心链路用gRPC;定了错误码规范;确认了灰度按流量比例滚动发布。如果没有智能提取,所有内容都会被存成记忆。下次你问“灰度策略怎么定的”,检索出来的可能是讨论过程中的某段代码片段。有了智能提取,存下来的只有最终结论。
找得到:多路检索,精准召回
存得准只是第一步,真正决定可用性的是召回精度。ContextBucket采用向量加BM25双路检索再加Rerank重排,把决策结论排到前列。新会话首次交互时会额外触发一轮宽泛召回,避免关键上下文因提问模糊而被遗漏。
比如你问OpenClaw“上次决定核心链路用gRPC的依据是什么”。纯向量检索可能返回讨论gRPC时的多段对话,其中夹杂着性能担忧、学习成本质疑、对比示例代码——但真正的决策只有一段。混合检索把关键词、语义和排序合在一起看,让Agent拿到的是结论,而不是一堆沾边的过程。
带得走:服务端存储,易迁移、大容量、低成本
记忆数据存储在ContextBucket服务端,而不是Agent所在的本地磁盘。换机器、换环境,只要用同一个user_id接入,历史记忆即刻可用。容量也不受本地窗口限制,按需检索、按需注入即可。在Locomo评测中,这一存储形态带来的端到端收益是:LLM输出Token下降80%,计费Token下降43.2%。
举个常见场景:你在公司电脑上用OpenClaw做了一周项目调研,积累了大量的技术决策和需求理解。周末想在家里的电脑上继续,过去要么手动复制记忆文件,要么从头再来。现在两台机器装上插件、共用同一个user_id,记忆自动同步,回到家直接续上。团队场景也一样:成员各跑各的Agent,但项目相关的技术决策、架构约定、编码规范共享同一份记忆,不必每次重复交代背景。
工作区:文件可持久化,工作流不断
文件远端持久化,不随本地环境丢失
只解决记忆还不够。OpenClaw的工作环境里同时存在代码、配置、项目文档、运行产物——这些原本散落在本地磁盘,换台机器就没了,团队协作也缺乏共享路径。
ContextBucket在同一个ContextSet内同时支持memory和workspace两种场景。创建时声明scenes: ['memory', 'workspace'],记忆数据与工作区文件就可以共享同一套凭证和端点,不再需要分别对接记忆服务和文件存储。
工作区分为两个目录,兼顾协作与性能:

你让OpenClaw写了一个数据处理脚本,跑完后结果保存在工作区。第二天电脑重启,文件还在。换台电脑重新挂载工作区,文件还在。同事要复用你的脚本,直接从共享目录拿,不需要你手动传。
工作流跨Agent无缝迁移
ContextBucket通过FUSE挂载将工作区目录映射为本地文件系统,代码生成、文件编辑、项目构建等操作沿用本地路径语义,Agent不需要感知底层差异。实际数据持久化在ContextBucket里,跨机器只需要重新挂载就能继续工作。
下图展示了“记忆+工作区”同源底座下的跨机器续写流程:
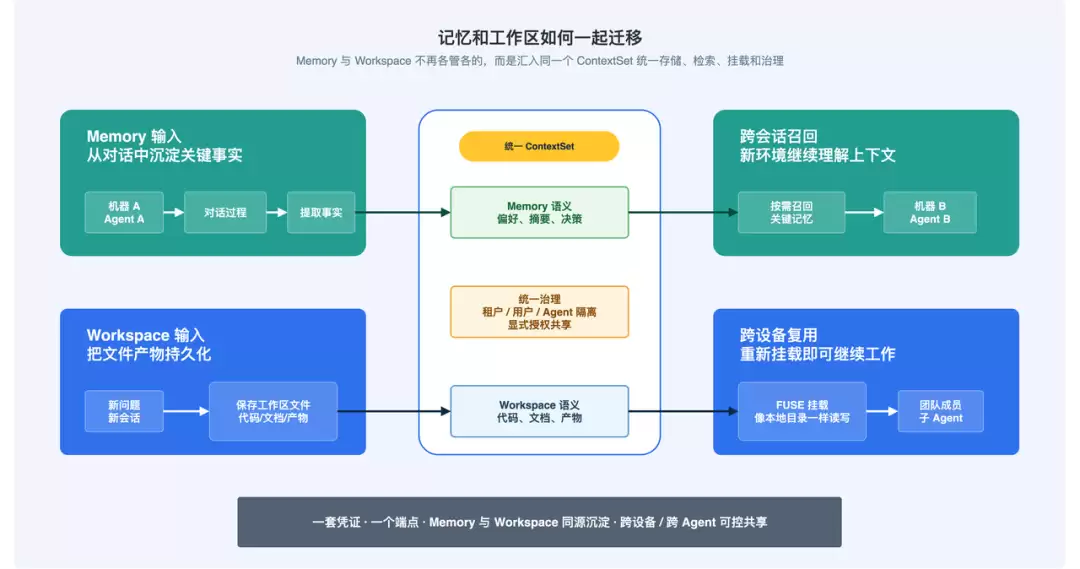
隔离在两个层次上同时生效:底座侧提供租户级隔离,Plugin侧叠加Agent级记忆隔离——主Agent、命名Agent、子Agent各自拥有独立的记忆命名空间,互不干扰。同时跑研究、编码、测试三个Agent:研究Agent的记忆不会污染编码Agent的上下文,编码Agent生成的文件也不会覆盖测试Agent的产物。需要跨Agent查询时,通过agentId参数显式访问即可。
工作区也能多路召回:语义+关键词+元数据
工作区不是冷存储——文件存在远端,Agent仍然需要在写代码、改配置、查文档时做到问得到、找得准。ContextBucket把记忆侧的检索能力下沉到底座,工作区文件直接复用同一条召回链路,只把第三路替换成更贴合文件场景的路径与元数据匹配。
三路并行召回:
- 向量检索:按语义找到功能相近的代码段、文档段
- BM25关键词:精准命中函数名、配置项、错误码
- 路径/元数据匹配:按目录、文件名、修改时间定位
Rerank加按需注入:
- 三路结果合并后由Rerank统一重排
- 按Token预算只注入最相关的若干片段,而不是把整个文件灌进上下文
- 大仓库、长文档也能稳定命中关键内容
例如工作区里有上百个yaml配置和几十万行代码。你问“灰度发布的流量比例配置在哪”,纯路径匹配可能漏掉换过名字的文件,纯向量检索又会被一堆看起来相关的注释干扰。多路召回加Rerank让命中的就是那一行配置,而不是十个相似文件。
对外接口与记忆侧保持一致:工作区文件和记忆事实可以在同一次检索请求里联合返回,Agent不需要区分“该问记忆还是该问文件”。
接入形态:一键安装,一行配置接入
接入ContextBucket只需要两步:一键安装与验证插件状态。向量库对接、FUSE挂载、多租隔离都在Plugin安装期完成,Agent不需要任何额外改造。
执行以下命令完成安装:
curl -fsSL https://context-bucket-cn-beijing.tos-cn-beijing.volces.com/context-bucket-bundle-latest.tar.gz | tar xz -C /tmp && bash /tmp/stage/install.sh --backend context --endpoint tos-control-cn-beijing.volces.com --access-key-id '' --access-key-secret '' --region cn-beijing --account-id '' --context-bucket-name 'context-bucket-poc' --context-set-name 'csn-poc' --secure false --force
把access-key-id、access-key-secret、account-id替换为火山引擎控制台获取的真实凭证;context-bucket-poc与csn-poc可以按实际项目命名。

安装完成后,执行以下命令验证插件是否正确注册:openclaw plugins list。列表中能看到ContextBucket相关插件且状态正常,即视为安装成功。如果列表为空或状态异常,回头看看install.sh末尾的输出,常见原因是AK/SK错误、网络不通、或bucket不在该account下面。

性能验证:Locomo长程对话评测
Locomo是学术界常用的长程多轮对话评测集,包含跨会话的事件、偏好、关系等记忆类问题,专门用于衡量Agent在长周期任务中的记忆能力。测试中,OpenClaw基线版本与接入ContextBucket Plugin的版本使用相同模型、相同问题集,区别仅在于记忆与工作区的存储方案。
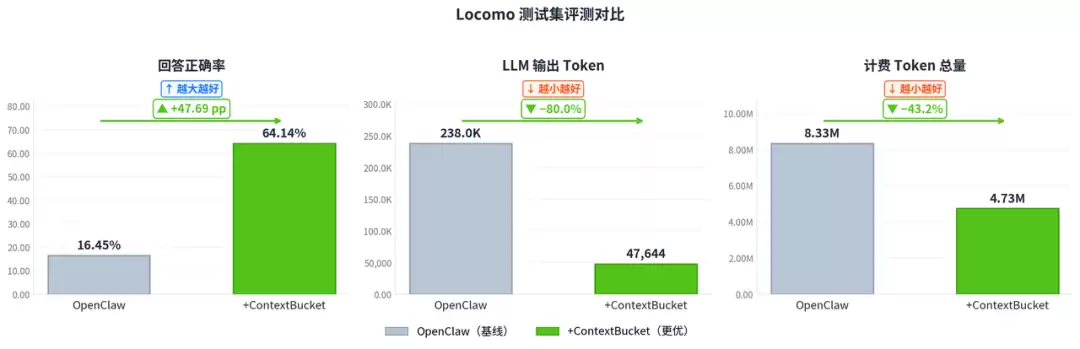
结论很直观:回答正确率从16.45%跳到64.14%,提升了近48个百分点。核心原因是记忆不再全量灌入上下文,而是经过提取、检索、筛选后按需注入。LLM输出Token减少了80%,计费Token总量减少了43.2%,成本也随之下降。
适用场景:哪些Agent真正需要它
并不是所有Agent都需要ContextBucket。它最适合那些已经从单机Demo走向长期服务、多端协作、多租户运营的系统——这类Agent的上下文不是一次性消耗品,而是必须被沉淀、复用和治理的核心资产。下面四种是最典型的形态:
研发Agent
代码、设计文档、依赖配置、CI结果、排障记录长期共存于工作区;架构决策、Code Review结论、踩坑经验沉淀为团队记忆。跨设备接续开发、跨成员复用经验是刚需。
办公/流程Agent
会议纪要、周报、项目背景、审批材料、历史决策需要跨会话延续。每次重新交代背景成本极高,稳定的长期上下文直接决定Agent能否真正接管流程。
终端助手/私人Agent
用户偏好、常用资料、历史任务和本地文件需要长期积累。手机、电脑、车机多端切换时,记忆和工作产物不能断层,否则“私人助理”就只是“一次性问答”。
企业Copilot平台
多个Agent、多个团队、多个租户共存时,权限隔离、配额治理、可审计性会比单Agent体验更早成为瓶颈。ContextBucket的千万级原生隔离正是为这一阶段设计的。
这四类场景的共同特征是:上下文规模大、生命周期长、跨端跨人协作、需要审计与隔离。一旦Agent进入其中任一场景,记忆与工作区便不再是可选项,而是绕不开的底层依赖。
总结与展望
ContextBucket以一个托管底座同时收敛了Agent的三类断层——记忆随会话消失、工作文件无法跨实例持久化、多Agent共用存储下的权限与审计混乱。在OpenClaw上的实测结果印证了这一收敛带来的端到端收益:
解决记忆断层
- 向量+BM25+Rerank多路检索
- 服务端持久化,跨机器带得走
- 正确率16.45% → 64.14%(↑47.69%)
解决工作区断层
- FUSE挂载,接近本地文件系统体验
- 语义+关键词+元数据多路召回
- 工作流跨Agent/跨实例无缝迁移
解决治理断层
- ContextSet千万级原生多租隔离
- 统一凭证与接入点,审计链路清晰
- Serverless零运维,5分钟跑通
底座层的核心问题已经解决,接下来ContextBucket的演进将沿两个方向展开:
更智能检索
引入图谱关联与时序感知,让Agent在跨会话、跨文件的大仓库中精准命中上下文;记忆侧与工作区侧检索能力对齐,一次提问同时捞回相关事实与相关文件。
更开放生态
扩展Plugin生态,支持更多Agent框架(LangChain、Hermes等)一键接入;开放ContextSet API,让第三方工具直接读写同一份上下文。
