
让 Agent 拥有超强记忆,TencentDB Agent Memory 开源了!
最近关于 AI Agent 的讨论越来越热,但细聊下来发现,不少用 Agent 做过项目的人都经历过同一种抓狂:花了大半天把项目背景交代得清清楚楚——技术栈是 TypeScript,测试文件放在 __tests__ 目录,代码注释要简短,还有一堆踩坑指南——结果新开一个会话,Agent 立马失忆,一切又得从头再来。
这种重复交代的循环,本质上就是在浪费人机协作积累的经验价值。那些踩过的坑、确认过的偏好、跑通过的流程,本可以沉淀下来,却随着会话结束凭空消失。随着 Agent 在真实项目中用得越来越深,AI 失忆已经成了实实在在的工时消耗。
这也不难理解,为什么过去两年里"Context Engineering"(上下文工程)会被反复讨论。答案其实很清晰:给模型提供什么样的信息、以什么结构组织这些信息,这件事的重要性正在逼近模型能力本身。而 AI 的记忆层,也正从一个可选插件,变成 Agent 架构里绕不过去的基础组件。
就在这个背景下,腾讯云数据库团队开源了一套面向 AI Agent 的分层记忆引擎:
TencentDB Agent Memory
不是让 AI 存下所有东西,而是让人不必重复跟 AI 交代所有事情

下面就来拆解一下,这个项目究竟能解决什么问题,背后的技术原理又是什么。
狂塞上下文,对话越来越乱
以前遇到 Agent 失忆,最直接的做法就是把历史对话全部塞进上下文,让 Agent 每次都能看到完整的过去。说实话,对话短的时候这招挺管用,可一旦牵扯到长线复杂任务,三个问题就会立刻暴露:
- ——历史对话不跨会话保留,换了会话就等于没有记忆;
跨会话断裂
- ——"我喜欢用 TypeScript"和"帮我查一下天气",两条信息的方向完全不同,混在一起等于什么都没记住;
事实与偏好混淆
- ——任务越长,历史记录越多,Token 消耗成倍增长,模型的注意力也持续衰减。
上下文膨胀
既然暴力堆历史不行,那就试试长上下文压缩?结果再次被打脸。传统的摘要压缩是有损的,压缩完就没办法还原,出了问题只能让 AI 猜,根因根本找不到。
记忆分层,对话更清晰
TencentDB Agent Memory 给出的解法是:给长期记忆建立层级,给短期记忆引入符号压缩。
长期记忆:四层语义金字塔
之前大多数记忆方案把对话切成片段,扔进向量数据库,所有信息平铺在同一层。比如"你喜欢用 TypeScript"和"你昨天问了天气"这两句话,在向量数据库里地位同等,召回时只能靠相似度碰运气,没有宏观结构引导。
这次换了个思路:
分层蒸馏,而不是平铺堆积
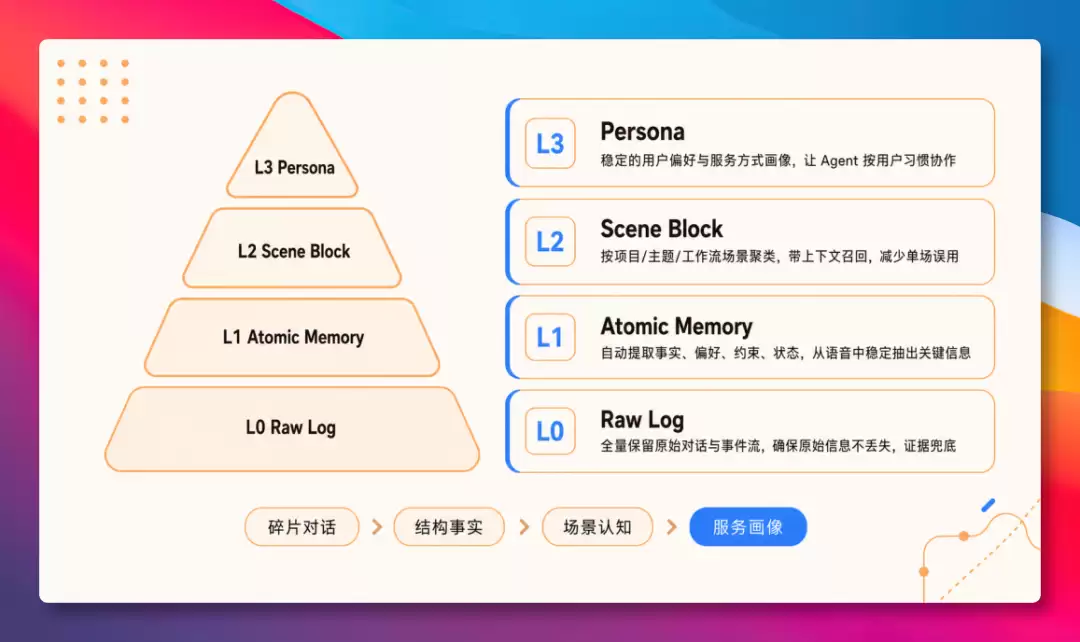
这四层从下往上依次是:
- L0:全量保留原始对话;
- L1:自动提取原子事实(代码偏好、踩坑记录、工作约定);
- L2:按场景聚类成记忆块;
- L3:持续蒸馏出稳定的用户画像。
Agent 会先从 L3 画像获取方向,需要更多细节时逐层往下钻。上层给的是方向,下层留的是证据。还有一个额外的好处:出了问题,可以沿着 L3→L2→L1→L0 这条链路一路追溯,不用在黑箱里猜。
短期记忆:Mermaid 符号画布
Agent 执行长任务时,调用工具产生的中间输出——搜索结果、代码日志、报错信息——叠加起来动辄几万 Token。如果全堆在对话上下文,很快就能撑爆上下文长度。
TencentDB Agent Memory 用 Mermaid 做符号压缩。Mermaid 这种图形化语言,既能让 LLM 精确解析,人也能直接阅读,不像 JSON 那样读起来费劲,也不像纯文本摘要容易丢失结构。
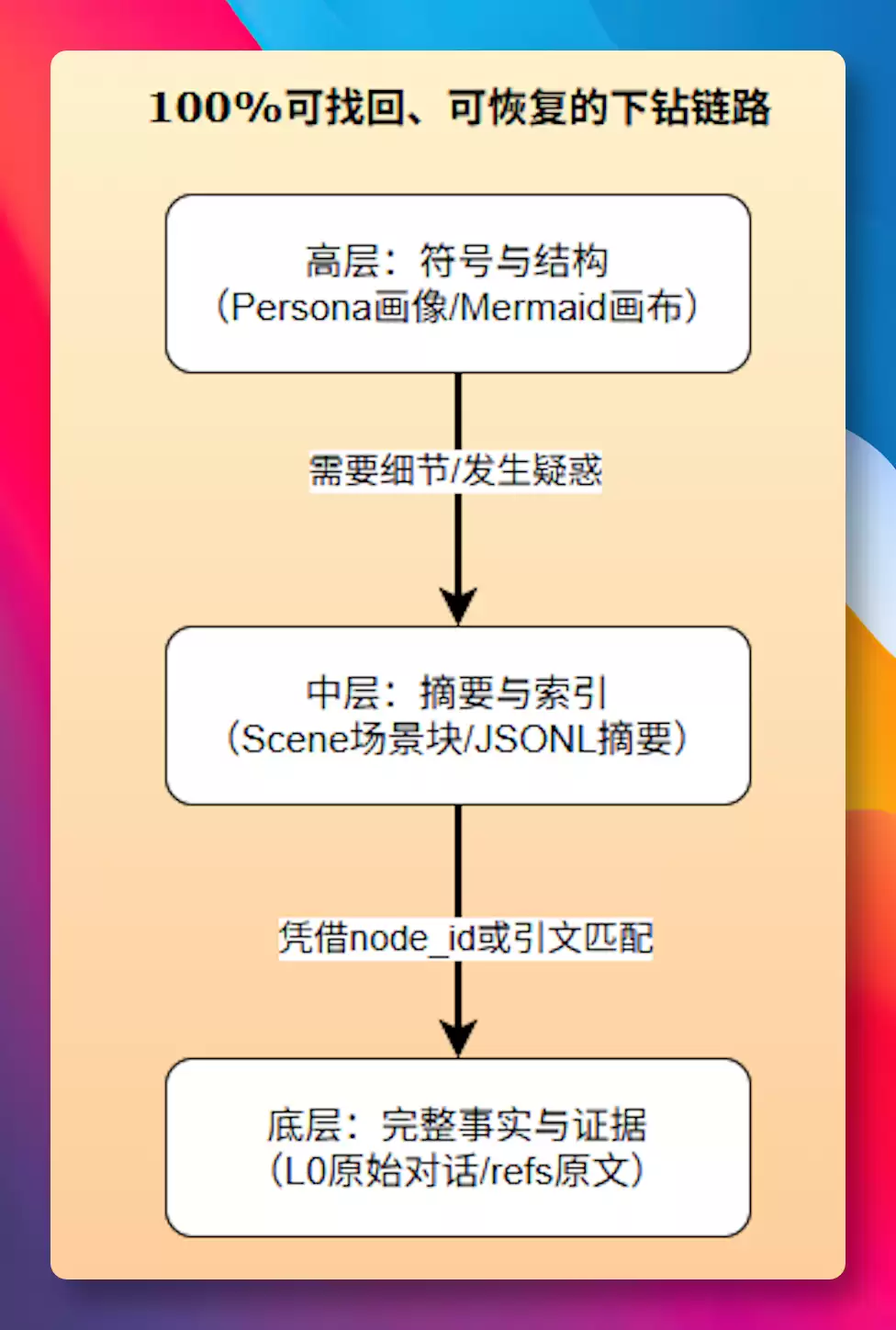
具体做法是:工具调用的详细输出保存到外部文件 refs/*.md,上下文中只保留一张 Mermaid 任务状态图,每个节点有 node_id。需要细节时,可以根据节点 ID 从文件中直接定位读取。这样既能保证原文不丢、结构可查,又能阻止 Token 线性增长。
真正价值,不止于节省 Token
以上这些解法带来的价值远不止于省 Token。值得关注的有三点:
从项目结构上看,所有记忆中间产物都以可读文件存在本地 ~/.openclaw/memory-tdai/,L3 是 persona.md,L2 是 Markdown,L1 是原始事实列表。以前大部分记忆系统出问题只能靠向量分数瞎猜,这里可以直接沿 L3→L0 一路追溯——对生产环境来说,这意味着极强的可维护性。
试想下,当打开 persona.md 文件,就能直接看到 Agent 把你记成了什么样的人。
对于开发者而言,代码本身也是一份非常值得学习的设计文档。分层记忆、符号压缩、异构存储都有清晰完整的架构,想自建类似系统的话,可以直接上手读源码学习研究。
另外,数据默认存放在本地 SQLite,不依赖任何外部 API,对企业用户或数据隐私敏感场景非常友好。
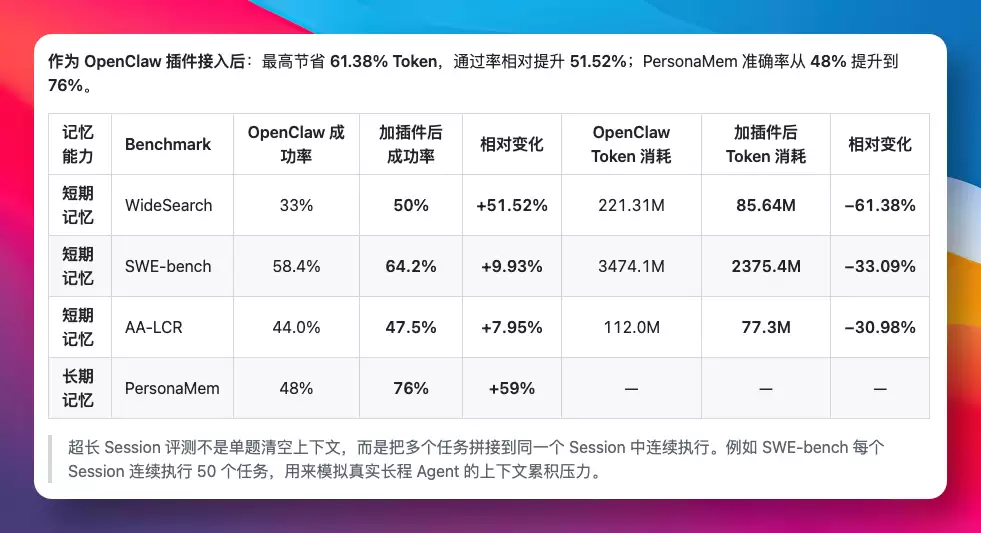
数据测试方面,以连续长任务会话为例,在 SWE-bench 上每个会话连续跑 50 个任务。WideSearch 显示 Token 消耗降低
61.38%
51.52%
48%
76%
接入很简单,不只限于龙虾
接下来聊下怎么用。项目提供了三种接入方式,都非常简单。
如果用 OpenClaw,可以作为
OpenClaw 插件
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb openclaw gateway restart
对于
Hermes Agent
最新开源的 1.0.0-beta.1 版本还提供了
独立服务模式
有了这些接入方式,不管用什么 Agent 框架,只要能发 HTTP 请求,都能快速接入,让模型的长期记忆层变成通用基础设施。
写在最后
Agent 失忆不只是使用体验问题,更是在不断浪费每一次人机协作产生的经验价值。近半年模型能力增长已在逐步放缓,下一个真正的差异化将不在模型参数量,而在经验的积累。
当我们和 Agent 协作的时间越长,它就越懂我们的代码风格、踩过的坑、惯用的解决方案。这些完全都属于我们自己的数字资产,不会因为更换或升级模型而消失。
现在腾讯云数据库团队将记忆层这套基础设施开源了,个人开发者也能轻松建立自己的经验壁垒。更重要的是,让人能从重复交代、重复踩坑的消耗里解放出来,把更多精力放在真正的判断和创造力上。
