
Qwen3-ASR:阿里开源的语音识别大模型,一行命令干掉 Whisper
阿里通义千问团队最近开源的 Qwen3-ASR 系列,在语音识别圈子里引起了不少关注。1.7B 参数的模型在公开评测中词错误率全面低于 Whisper large-v3,支持 52 种语言和方言,自带歌词转写和方言识别,用 vLLM 一行命令就能部署成 OpenAI 兼容的 API。Apache 2.0 协议,拿来就用。
Whisper 统治了两年,但裂缝已经出现
过去两年,凡是和"语音转文字"打交道的项目,绝大多数都绕不开 OpenAI 的 Whisper。
Whisper 的出现确实是一道分水岭。在那之前,做 ASR 要么花大价钱买商业 API,要么折腾 Kaldi 那套复杂到让人怀疑人生的管线——声学模型、语言模型、解码图、WFST,光搭环境就能劝退一半人。Whisper 把这些全部塞进了一个 Encoder-Decoder 模型里,一个命令就能跑,99 种语言开箱即用。
但 Whisper 也带着它那个时代的局限性。
它不会拒绝。
它不够快。
它在极端场景下不够硬。
这些问题不是 Whisper 的"bug",而是它架构的天花板。一个 2022 年设计的纯 Encoder-Decoder 模型,没有利用大语言模型时代的语义理解能力,也没有针对流式场景做架构级的优化。
阿里的 Qwen3-ASR,就是冲着这些裂缝来的。
用大语言模型"听懂"声音
Qwen3-ASR 最根本的不同在于:它不再把语音识别当成一个独立的信号处理任务,而是把它变成了"大语言模型理解音频"的过程。
这话听着有点抽象,拆开看架构就清楚了。
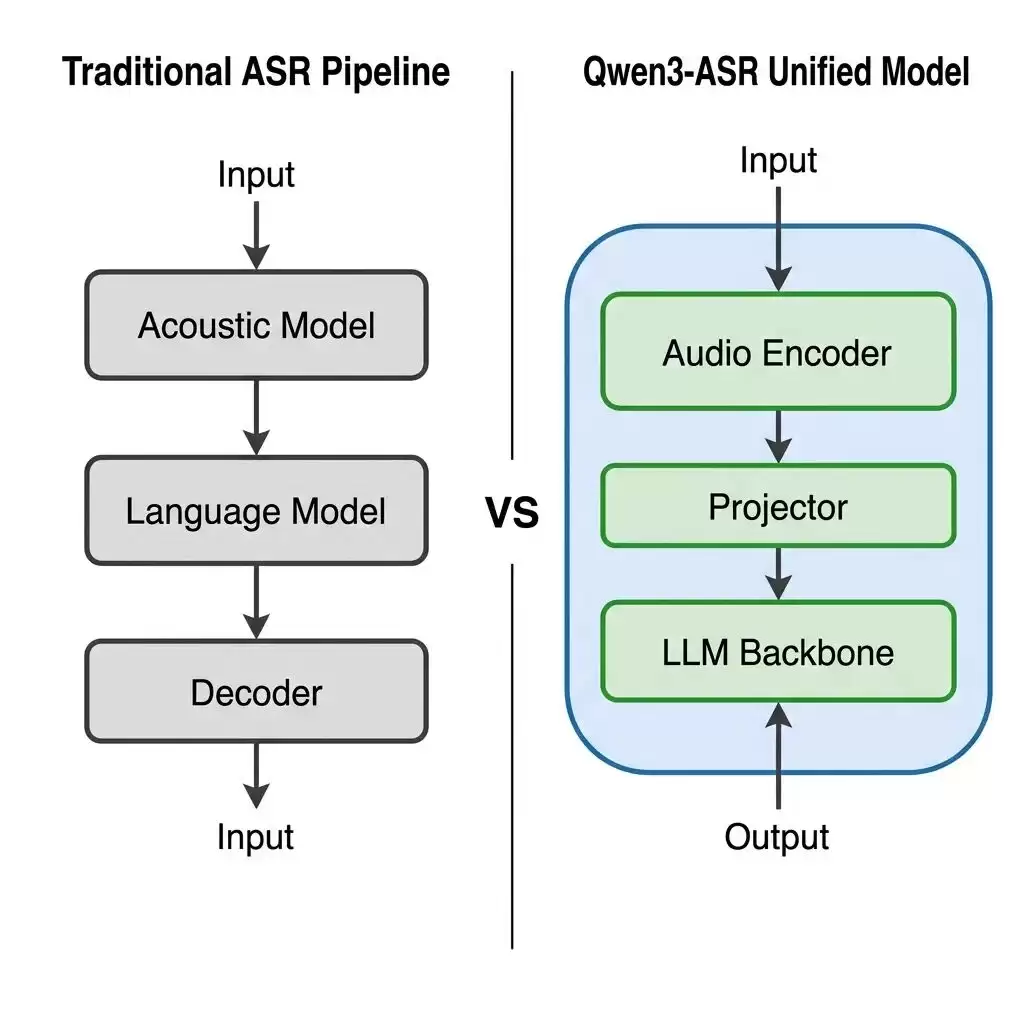
整个模型由三个模块组成:
第一层:音频编码器(AuT)。
编码器还有一个重要设计:
动态 Flash Attention
第二层:投影器(Projector)。
第三层:Qwen3 LLM 骨干。
这个架构的妙处在于:
语音识别的准确率,直接受益于 LLM 的语言理解能力。
传统 ASR 模型的语言模型是一个浅层的 n-gram 或者小型 LSTM,碰到专业术语、生僻词、新造词就容易翻车。但 Qwen3 的 LLM 骨干见过海量的文本数据,它对"这个语境下应该出现什么词"有更深层的语义理解。当音频编码器给出一个模棱两可的发音时,LLM 能根据上下文做出更准确的判断。
这就是为什么 Qwen3-ASR 在歌词转写和强噪音场景下表现特别好——不是因为它的"耳朵"比 Whisper 灵,而是因为它的"大脑"比 Whisper 聪明。
一个模型干三件事
Whisper 只做一件事:把音频转成文字。
你想知道这段音频说的是什么语言?得先跑一遍语言检测,或者靠 Whisper 开头输出的 language token 来猜,但那个准确率并不总是靠谱。你想过滤掉纯音乐或者无人说话的片段?Whisper 做不到,它会"硬听"。
Qwen3-ASR 把这三件事合成了一个模型:
- :自动判断音频是什么语言,支持 30 种主流语言和 22 种中文方言(粤语、四川话、闽南语、吴语等),以及来自不同国家和地区的英语口音
语言识别(LID)
- :核心能力,52 种语言和方言的高精度识别
语音转文字(ASR)
- :如果输入的是纯音乐、环境噪音或者无人说话的片段,模型会主动拒绝输出,而不是产生幻觉文本
非语音拒绝
单模型完成这三件事意味着什么?意味着你的生产管线里少了两个串联组件,少了两次网络调用,少了两个出错的节点。架构越简单,越不容易出幺蛾子。
不只是"比 Whisper 好一点"
光说架构漂亮不够,得看实战。
在公开评测上,
Qwen3-ASR-1.7B 拿到了开源 ASR 模型中最低的平均 WER(词错误率)
- :背景有施工噪音、咖啡厅人声嘈杂、风噪干扰,Qwen3-ASR 的识别稳定性明显更强
嘈杂环境
- :22 种中文方言不是摆设,实测粤语和四川话的识别率远超 Whisper
方言和口音
- :背景有伴奏音乐的情况下识别歌词,这是传统 ASR 模型的噩梦,Qwen3-ASR 能扛住
歌词转写
- :会议室里离麦克风三四米远的发言,Whisper 经常出乱子,Qwen3-ASR 依然稳
远场拾音
另一个竞争对手是 NVIDIA 的 Canary-Qwen 2.5B。这个模型用 FastConformer 编码器加 Qwen3 LLM 解码器,走的是 SALM(Speech-Augmented Language Model)架构。在一些英语基准上,Canary 也很能打。但 Qwen3-ASR 在两个维度上领先:
字级时间戳预测
原生流式推理
如果你需要极致的推理速度而不是极致的精度,还有 0.6B 版本可选。这个"小弟"在 128 并发下能达到
2000 倍实时吞吐
字级时间戳:不只是"听到了什么",还知道"什么时候说的"
Qwen3-ASR 家族里还有一个容易被忽略的成员:
Qwen3-ForcedAligner-0.6B
这是一个非自回归的强制对齐模型,能给转写结果里的每一个字(或者词)标上精确的起止时间戳。支持 11 种语言,能处理最长 5 分钟的音频片段。
Whisper 也能输出时间戳,但只到段落级别。你知道"这一段话大概是从第 3 秒到第 8 秒说的",但你不知道其中"人工智能"这四个字精确地出现在第 4.32 秒到第 5.17 秒。
ForcedAligner 就是干这个的。而且它的时间戳精度超过了主流的端到端对齐模型。
这个能力在以下场景非常关键:
- :精确的字级时间戳让字幕和口型完美同步,不会出现"嘴巴已经闭上了字幕还在滚"的尴尬
视频字幕
- :在一段长录音里搜索某个关键词,直接跳转到它出现的精确位置
语音搜索
- :对比标准发音和实际发音的时间对齐,用于外语学习类应用
发音评测
- :基于文本搜索来定位音频片段,然后精确裁剪
播客剪辑
使用上也很直接,ASR 模型和 ForcedAligner 可以一起加载,一次推理同时拿到转写结果和时间戳:
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
forced_aligner="Qwen/Qwen3-ForcedAligner-0.6B",
)
results = model.transcribe(
audio="meeting.wa v",
return_time_stamps=True,
)
部署:一行命令,OpenAI 兼容
说到部署,Qwen3-ASR 的开发者体验可以说是目前开源 ASR 项目里最丝滑的。
整个安装就一行:
pip install -U qwen-asr[vllm]
启动服务也是一行:
vllm serve Qwen/Qwen3-ASR-1.7B
然后你就得到了一个 OpenAI 兼容的 API 端点。可以用 OpenAI 的 Python SDK 直接调用,连客户端代码都不用改:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="Qwen/Qwen3-ASR-1.7B",
messages=[{
"role": "user",
"content": [{"type": "audio_url", "audio_url": {"url": "audio.wa v"}}]
}]
)
print(response.choices[0].message.content)
甚至还兼容 OpenAI 的 Transcription API:
transcription = client.audio.transcriptions.create(
model="Qwen/Qwen3-ASR-1.7B",
file=audio_bytes,
)
这意味着什么?如果你现在用的是 OpenAI 的 Whisper API,想切换到私有部署的 Qwen3-ASR,
客户端代码几乎零改动
base_url 和 model 名字就行。对于已经在生产环境中跑着的系统来说,这种迁移成本几乎为零。
流式推理也有。基于 vLLM 的流式后端,音频一边输入一边输出转写结果。团队还提供了一个 Flask 的流式 Demo,浏览器里打开就能用麦克风实时测试。
如果你不想折腾 GPU 环境,官方的 Docker 镜像也准备好了:
docker run --gpus all -p 8000:80 qwenllm/qwen3-asr:latest
从安装到服务启动,三分钟搞定。
长音频怎么办
现实中的语音场景经常不是"一段三秒钟的录音",而是一场两小时的会议、一堂三小时的网课、一个六小时的直播回放。
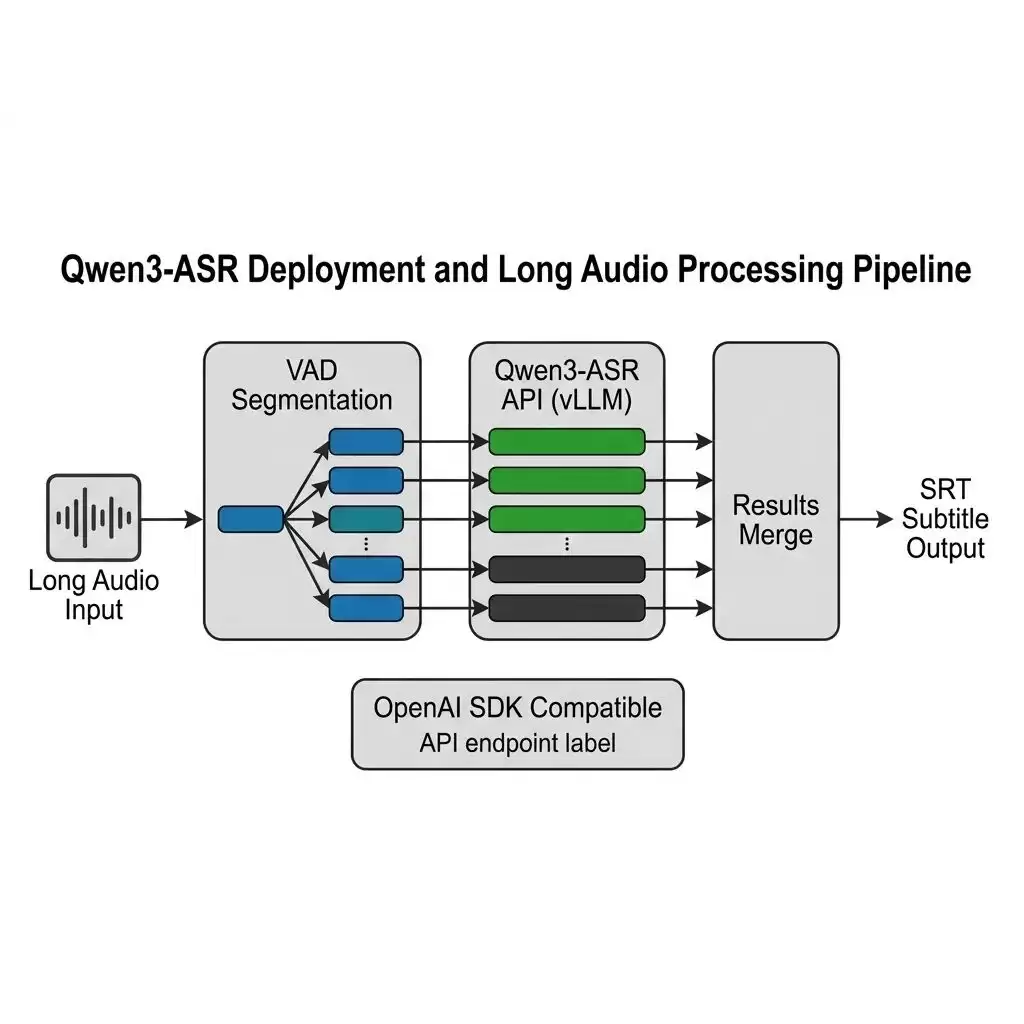
Qwen3-ASR 本身支持长音频转写,但直接丢一个六小时的文件进去显然不现实。社区已经有了成熟的方案:
VAD(语音活动检测)切分 + 多线程并发调用
流程大概是这样的:
- 先用 VAD 工具(比如 Silero VAD)把长音频按静音段自动切成短片段
- 每个片段重采样到 16kHz 单声道 PCM 格式
- 多线程并发调用本地部署的 Qwen3-ASR API
- 把各段结果拼接起来,利用 ForcedAligner 的时间戳生成 SRT 字幕文件
这套流程在社区的 Qwen3-ASR-Toolkit 里已经封装好了,开箱即用。一台有 A100 的机器处理一场两小时的会议录音,大概只需要几分钟。
如果你完全不想碰 GPU,阿里云百炼平台也提供了 Qwen3-ASR-Flash 的云端 API,按量付费。Flash 版本还支持一个独特的能力:
上下文偏置
训练的秘密:4000 万小时音频 + 强化学习
最后说说训练。Qwen3-ASR 的训练流水线分四个阶段,每个阶段解决不同的问题:
第一阶段:AuT 预训练。
第二阶段:Omni 预训练。
第三阶段:ASR 微调。
第四阶段:强化学习(GSPO)。
该换了
回到最开始的问题:Whisper 还值得用吗?
如果你的需求是"支持 99 种语言的广覆盖",Whisper 暂时还有优势。但如果你的场景是中英文为主、需要高精度、需要流式、需要字级时间戳、需要方言支持,答案已经很明确了。
Qwen3-ASR-1.7B 在精度上全面超越 Whisper,在工程化程度上提供了 vLLM 原生支持和 OpenAI 兼容 API,在开源协议上是最友好的 Apache 2.0。
从 Whisper 迁移过来的成本接近于零。
是时候换了。
