
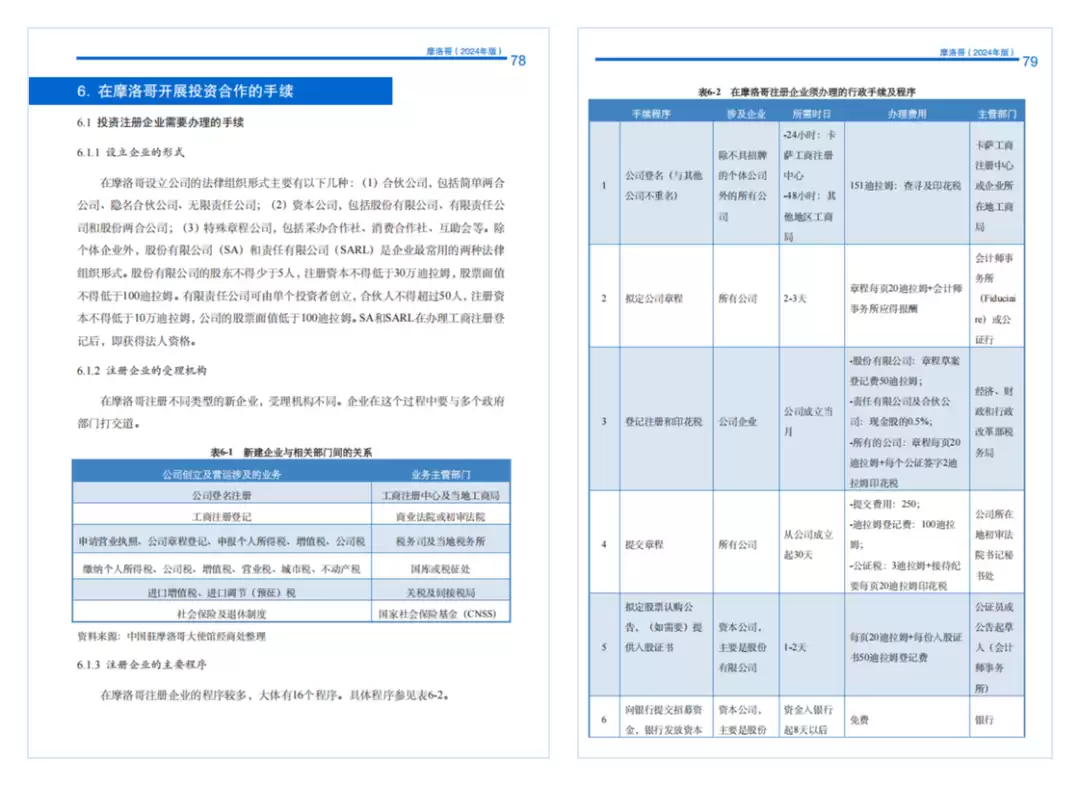
PDF2X:教材等高知识密度文档的解析与抽取实战
教材、讲义、培训手册这类文档,从来都不是“读一遍就行”的东西。它们承载着大量信息:标题层级、定义、公式、表格、图注、例题、流程、考点——每一项都指向明确的知识边界。
一旦这些文档能被稳定解析,能做的事情就太多了:知识管理、学习笔记整理、题库生成、课件生成、内部培训材料处理、甚至行业知识库的搭建。问题在于,AI 没办法一眼看穿一页 PDF 的版式。人瞄一眼就能区分哪里是标题、哪里是正文、哪个表格对应哪段说明,机器不行。它需要先拿到稳定的文本、清晰的结构和可识别的知识边界。
所以,对高知识密度文档来说,解析不是“PDF 转文字”这么简单,而是后续 AI 应用的第一层能力。
今天分享一个实际案例:一个开发者想做一个“互动课件生成器”,帮助教师把课件、讲义、教材等 PDF 文档,一步转化成可互动的课件式知识材料。在这个流程里,PDF2X 解析能力扮演的是入口——先把文档解析成机器可继续处理的 JSON 结构,再让应用做知识点提取和课件编排。
一个应用场景:AI驱动的互动课件生成器应用
这个用户的应用逻辑大概是:上传教材或讲义 PDF → 调用 PDF2X 解析出 JSON 结构化结果 → 根据解析结果抽取知识点、流程、规则和考点 → 把这些知识材料映射到课件页面。
问题首先出在输入材料解析上。因为“互动课件生成器”不能直接处理“一页排版好的 PDF”。它需要知道:这份文档有哪些标题层级?每个小节讲到哪里结束?哪一段是定义?哪个表格是数据材料?哪组内容是因果或流程?哪些内容适合变成判断题或填空题?
如果解析不清楚,后面生成的课件就会变得极不稳定。比如原文里本来是一个定义,可能被当成普通段落;原文里本来是一个表格,可能被拆散成几行文字;原文里本来是一个流程,可能丢掉顺序关系;原文里本来是一个考点,可能无法继续出题。这正是高知识密度文档的核心难点:它不只是文字多,而是信息类型多、结构关系多、后续用途也多。
01 解析前:面对的是一页排版复杂的文档
在解析前,用户手里是一页完整的 PDF。页面里可能同时有章节标题、正文解释、公式或表格、图片和图注、例题、重点提示、结论和考点。这些内容在页面上靠版式组织——标题通过字号区分,表格嵌在正文中间,图注贴在图片下方,公式和解释文字交错排列,例题和答案分布在不同区域。
对人来说,阅读没问题。但如果要让“互动课件生成器”继续处理,就必须先把页面里的内容转成机器能理解的材料。否则后续 AI 拿到的只是“很多文字”,而不是“可以生成课件的知识结构”。
02 解析后:PDF2X 输出可继续处理的 JSON 结构
调用 PDF2X 后,PDF 页面会被解析成 JSON 结构化结果。这一步满足了“互动课件生成器”的几个基础需求。
标题层级被保留
解析结果需要让应用知道:哪个是大标题,哪个是小节标题,哪些内容属于同一部分。这决定了后续课件能不能按章节和主题组织。
正文段落被拆开
长段落需要被稳定提取出来,而不是与页码、图注、表格混在一起。这决定了后续能不能抽概念、定义和解释。
表格、公式、图文内容被识别
高知识密度文档里,表格和公式经常是关键知识材料。如果它们被忽略或打散,后面的知识抽取就会丢掉重要信息。
内容边界更清楚
解析后的 JSON 结果,让用户的应用可以继续判断:这部分内容是概念、数据、流程,还是可出题点。
也就是说,PDF2X 解析之后,用户拿到的不再是一页 PDF,而是一份可以继续加工的输入。

03 从知识材料到课件组件
“互动课件生成器”要实现的,不是把原文整段搬进幻灯片,而是根据解析后的知识材料选择合适的课件组件。这里举 3 个例子。
概念定义 → 概念解释页
如果解析结果里有知识点名称、定义和关键词,就可以进入概念解释页。页面重点是解释概念,而不是堆满原文。
流程 / 因果 → 流程链页面
如果解析结果里有步骤 1 / 2 / 3,或者明确的因果链,就可以进入流程链页面。这种页面适合展示过程、机制和操作步骤。
必背 / 判断点 → 填空或选择题
如果解析结果里有关键数字、核心定义、易错点或判断点,就可以进入填空题、选择题或判断题。这类页面适合用来检查学习者是否真的理解。
到这里,PDF2X 的解析结果就完成了从“PDF 页面”到“课件素材”的转换。
它没有直接替用户完成所有课件设计,而是为“互动课件生成器”提供了稳定输入。
04 细看解析结果:如何变成知识材料
PDF2X 解析完成后,“互动课件生成器”会继续从 JSON 结果中抽取知识材料。这里只看同一页里的 3 类内容,就能说明解析在课件生成器里的作用。
概念:从一段定义到知识点
解析前,概念通常藏在正文里。例如原文可能是一段连续解释:“某某概念是指……它具有……特点,常用于……”
解析后,用户的应用可以基于这段内容提取出:
{
"knowledge_point": "知识点名称",
"definition": "这是什么",
"keywords": ["关键词1", "关键词2", "关键词3"]
}这一步之后,概念不再只是原文中的一段话,而是一个可以被课件生成器调用的知识点。它可以用于概念解释页,也可以用于问答、总结或复习卡片。
关系 / 流程:从过程说明到步骤链
教材和讲义里经常会出现过程说明:先发生 A,然后导致 B,最后形成 C;或者操作时应先……再……最后……
解析结果稳定以后,用户的应用可以继续把它整理成:
{
"process_name": "流程名称",
"steps": [
"步骤 1:先做什么",
"步骤 2:接着发生什么",
"步骤 3:最后形成什么结果"
],
"relation": "因果链 / 操作流程 / 递进关系"
}这一步让应用不只是读到一段文字,而是识别出里面的顺序、因果和步骤。这类材料后续很适合进入流程链页面。

练习 / 判断点:从考点到可出题材料
教材和培训材料中,很多内容天然适合变成练习题。比如注意……判断……这里容易混淆……
解析后,用户的应用可以把它转成:
{
"question_seed": "可出题点",
"question_type": "选择题 / 填空题 / 判断题",
"key_answer": "正确答案",
"reason": "为什么"
}这类结构化结果可以继续用于生成选择题、填空题或判断题。也就是说,解析结果不仅支持“阅读”,还支持“教学活动”。

05 使用方式
开发者可以参考 PDF2X API 文档接入解析能力。基础流程很简单:获取 API Key 并在请求头中携带 Authorization → 上传 PDF 创建解析任务 → 查询任务状态等待解析完成 → 获取 JSON 解析结果交给后续应用继续处理。
如果你想试试这个课件生成器应用,可以直接体验。解析是入口,但不是终点——它是让 AI 真正读懂一份教材的起点。
