
写Prompt别再拽高级词汇了,用大白话效果反而更好
先说个真实的实验案例。
有人把同一个指令用两种方式写给AI。一种版本是“请对以下问题进行深入分析并给出详尽的解答”,另一种是“帮我分析一下这个问题”。猜猜哪种效果更好?答案是后者,准确率高了整整8个百分点。

第一次看到这个数据时的反应,大概和屏幕前的你一样:这不可能吧?写得越专业不是效果越好吗?但这篇论文讲的正相反。它出自一项名为
Adam's Law
坦白说,这个发现确实让人震惊。先前写Claude Code的prompt时,很多人都喜欢拽词。比如想让AI检查代码,会写“请对以下代码段进行深入的逻辑审查和潜在缺陷识别,并给出具体的修复建议”。听起来很专业、很严谨,AI应该会更认真对待。直到看到这篇论文才意识到,那些花里胡哨的表述,可能一直在帮倒忙。

Adam's Law说了什么
这个研究做的事相当扎实:用100种语言、4类核心任务——数学推理、机器翻译、常识推理、Agentic工具调用——做了大规模实验。四个完全不同的任务类型,得出的结论惊人一致:把prompt里的低频词换成高频词,准确率就能显著提升。而且这不是某个模型的bug,他们测了DeepSeek-V3、GPT-4o-mini、LLaMA-3.3-70B,还有Qwen-2.5系列从0.5B到72B的所有变体,全部有效。
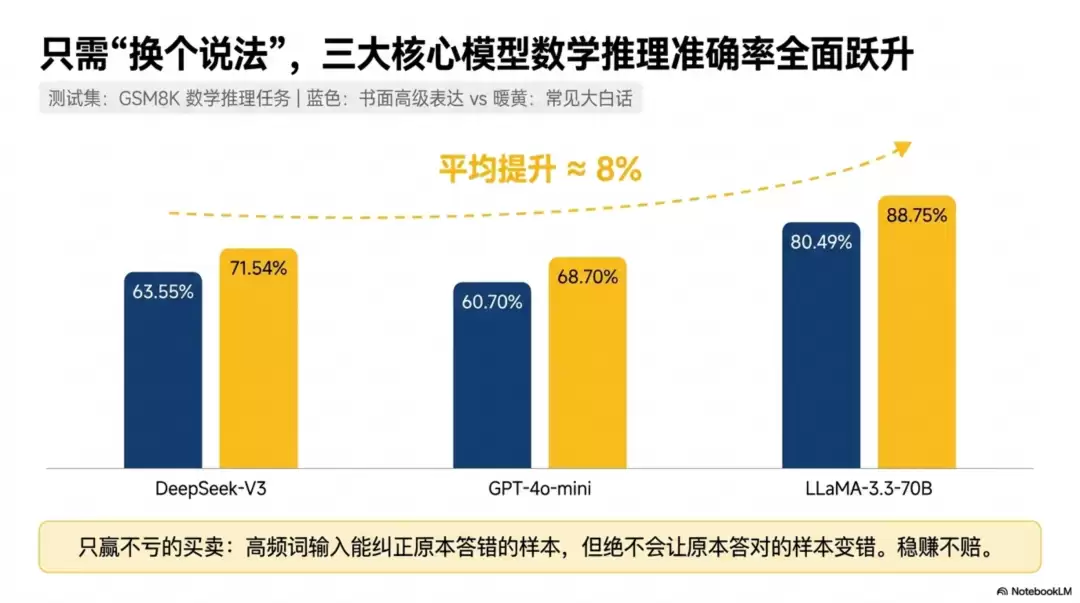
数学推理的数据最直观。GSM8K是一个标准的数学推理测试集,同一道题用两种方式写prompt:一种是常见表达,另一种是比较书面、高级的表达。结果如何?
DeepSeek-V3从63.55%涨到了71.54%。
GPT-4o-mini从60.70%涨到了68.70%。
LLaMA-3.3-70B从80.49%涨到了88.75%。
三个模型,涨了差不多8个百分点。想想这概念:很多论文花几十页论证0.5%的提升,这里一个“换个说法”就搞定了8%。
机器翻译那边更夸张。在FLORES-200数据集上测了100个语言对,用DeepSeek-V3做翻译。把prompt换成高频表达后,100个语言对里99个的BLEU分数都上升了——99个!只有1个轻微退化,不到1分,基本可以忽略。其中63个语言对改善超过1分,31个超过3分,12个超过5分。用COMET指标看,37种语言全部改善,一个都没掉。

最令人震惊的一个发现
实验里有一个结果反复看了三遍。他们测试了微调场景:用高频词改写过的数据去微调模型,效果居然超过了用原始标注数据微调的模型。这代表了什么?你花大量人力标注的数据,如果用词不够“常见”,效果可能反而不如用高频词改写过的版本。标注数据是AI行业最贵的成本之一,很多公司花几百万去标注数据,结果可能因为标注员用了太多专业术语,效果还不如用大白话重写一遍。
还有一个发现同样重要:高频输入能纠正原本答错的样本,但不会让原本答对的样本变错。这是一个“只赢不亏”的效果——你用高频表达重写prompt,答对的还是对,答错的有可能被纠正过来。稳赚不赔。
为什么会这样
论文给出了基于Zipf定律的数学证明,但用人话解释也很简单。大模型是怎么学会说话的?读互联网。它读了海量的文本,学会了“什么样的文字长什么样”。高频词就是那些在互联网上出现次数特别多的词:“帮我”“分析”“总结”这些词,模型见过无数次,内部已经形成了非常精准的概率分布。但“精炼”“阐释”“辨析”这些词,虽然意思差不多,出现频率低得多,模型对它们的内部表征就没那么“精准”。
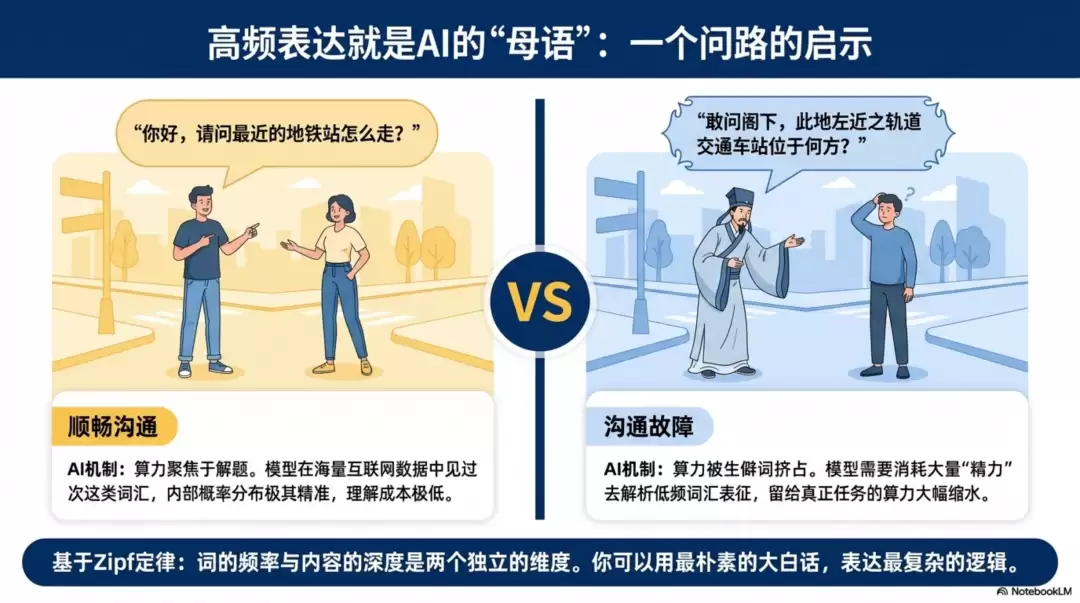
打个比方。你去一个陌生城市,跟路人问路:“你好,请问最近的地铁站怎么走?”对方立马给你指方向。但如果你说“敢问阁下,此地左近之轨道交通车站位于何方?”对方可能直接报警。模型也是一样的:高频表达就是它的“母语”。你在它的母语范围内沟通,它理解得最准确。你拽一堆它不怎么见过的表达,它就得花更多“精力”去理解你在说什么,留给真正任务的“算力”就少了。
论文里有一个细节特别有意思:他们发现频率和文本复杂度的相关系数接近0。什么意思呢?就是用简单词不等于内容变简单。你可以用大白话讨论量子力学,也可以用术语讨论天气。词的频率和内容的深度是两个独立的维度。最朴素的语言可以表达最复杂的思想,而模型恰好更喜欢朴素的语言。
对实际使用的影响
第一,改掉“越专业越好”的习惯。很多人写prompt的时候,恨不得把每个词都换成术语。“基于RAG架构的知识库检索增强系统”,不如说“能搜索文档回答问题的AI助手”。意思完全一样,但后者可能效果更好。
第二,建立“频率意识”。每次写完prompt,问自己一个问题:这个词日常跟朋友聊天会用吗?如果不会,换一个。比如“请对以下代码进行深入审查”改成“帮我看看这段代码有没有问题”;“请生成一份详尽的分析报告”改成“帮我写个分析,详细点”;“请对上述内容进行精炼概括”改成“帮我总结一下”。每一组的意思完全一样,但右边的版本大概率效果更好。
第三,句子结构也要简化。不只是单个词的问题,复杂句式本身就包含更多低频词组。“鉴于当前的市场环境,我建议我们对产品策略进行相应的调整”改成“市场变了,咱们产品策略也得跟着改”。后者不光词频高,句式也是模型更常见的结构。
论文里提到他们建了一个叫TFPD的数据集,专门用来配对“同一个意思的高频和低频表达”。这说明未来可能会有工具自动帮你优化prompt的用词频率。但在那之前,最简单的办法就是写完prompt读一遍,想象自己在跟朋友说话,把所有“书面腔”的地方改成“口语腔”。
更深层的事
聊到这,值得思考一个更深层的问题:为什么我们这么执着于把prompt写得“高级”?这背后可能是从小写作文就被教育要用“好词好句”的习惯。语文老师说“请对上述内容进行精炼概括”比“帮我总结一下”更有文采,这种思维定式延伸到了写prompt上。但AI模型不是语文老师,它不需要你展示词汇量,它需要的是准确理解你的意图。在AI面前,朴素才是真正的力量。
而且这个发现的影响范围远不止写prompt。训练数据的清洗标准,以后可能要加入“频率”这个维度;微调数据的构建方式,可能要重新设计;翻译系统、搜索引擎、对话系统,都可能因为这个规律而优化。论文里说他们用高频词数据做微调,效果超过了原始标注数据。可以说,整个AI行业的数据工程,可能都需要重新审视“频率”这个被忽略的维度。
经济学以前只看“供给和需求”,后来加入了“预期”这个新维度,整个理论体系都不一样了。Adam's Law做的事情有点类似,在“质量、规模、难度”三个维度之外,补上了“频率”这第四个维度。
写到这里还是挺感慨的。一直以为prompt写得越专业越好,结果发现那些花里胡哨的表述一直在帮倒忙。就像花了很大力气去装饰一把锤子,结果发现朴素的锤子敲钉子更准。论文里那个“只赢不亏”的发现让人印象最深——高频输入能纠正错误但不会引入新错误。这种稳赚不赔的事儿,在AI领域真的不多见。
