
Claw Team 在 SRE 场景下的实践
人工智能正经历从“个人尝鲜”到“企业落地”的转折。个人养虾的热度虽然降温,但它完成了 Agent 的全民普及教育。现任多重任务中尤其是线上巡检、定时发布、团队协作场景下,Claw 已成为许多人每天调用模型的标配入口。另一方满,企业养虾开始进入决策期,评估如何通过企业内展现的供应链系统设计智能体应用场景与迭代路径。以下分享我们团队在阿里云 SRE 系统中部署 HiClaw 多智能体的实践——从平台设计到团队协作,再到一个实际故障排查的完整闭环。
核心内容
本实践主要覆盖三个关键部分:
- HiClaw 平台的核心定位与架构设计
- 构建 SRE 多智能体组织的完整步骤
- 多智能体在运维场景下的真实协作案例
01 HiClaw 是什么
HiClaw 是一个面向企业的分布式多 Agent 运行平台。与常见的单进程个人 AI 助手不同,它自己不实现 Agent 逻辑,而是像操作系统一样编排和管理多个 Agent 容器——包括一个 Manager 和众多 Workers。这些 Agent 可以运行 OpenClaw 或 CoPaw 作为智能内核,未来还将支持 NanoClaw、ZeroClaw,甚至通过 CLI 接入企业自建 Agent。其核心价值是:让多个 Agent 在一个受控、可审计的环境中协同工作,人类全程可见、可介入。
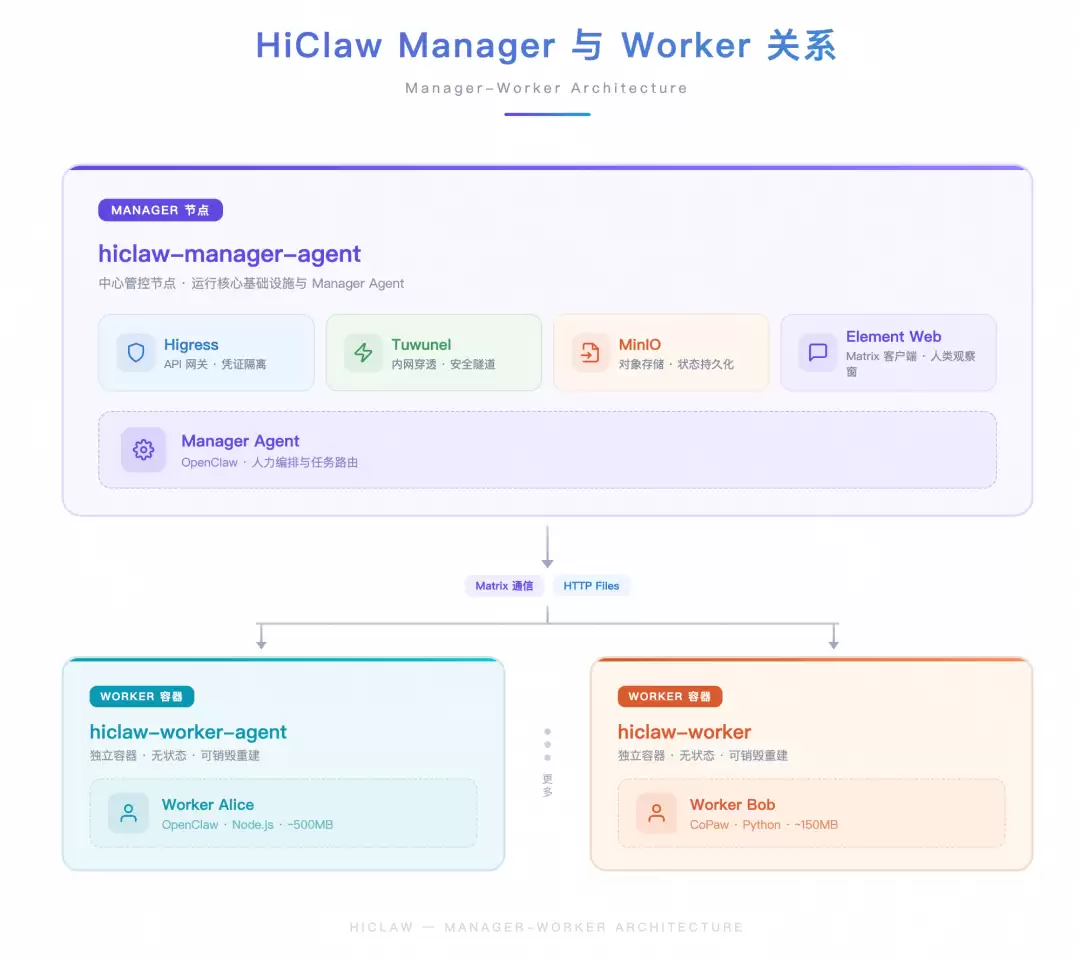
“泰山”是我们团队支撑阿里云上云原生产品的 SRE 系统。接下来,我们将在这个系统的隔离环境中部署一套 HiClaw,并应用于我们的日常运维场景。
02 构建 HiClaw 多智能体组织
HiClaw 初始化后的状态很简洁:一个唯一的真人账号(admin)和唯一的数字人(manager)。Manager 本身是一个 OpenClaw,内置任务与项目管理、系统管理、Worker 管理等 Skills,拥有操作 HiClaw 所有资源的权限,所有执行指令都需经过它。
组建 Human 团队
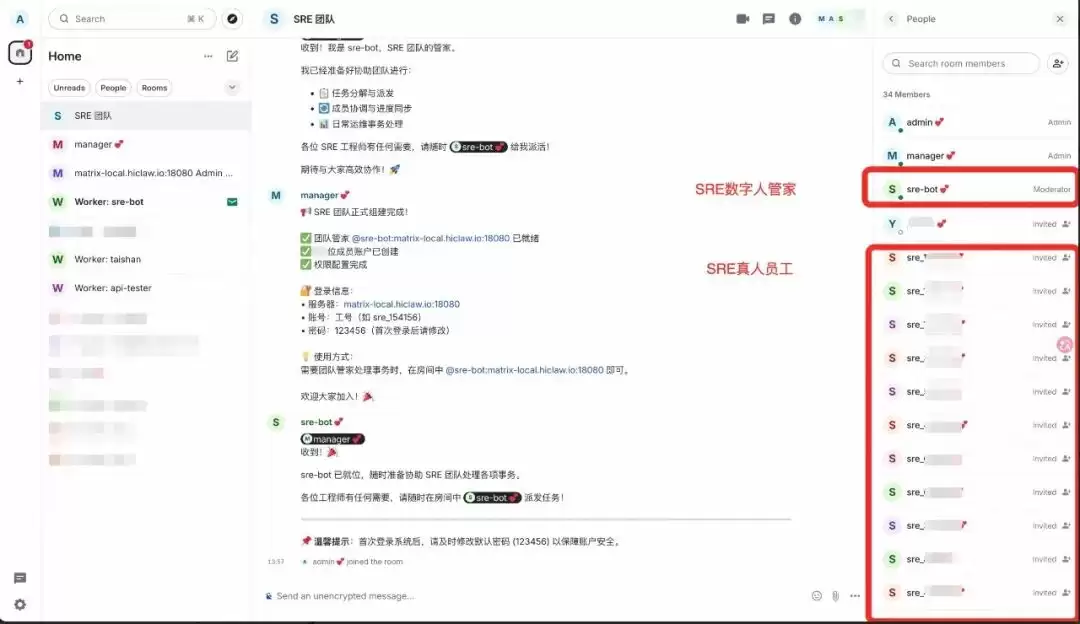
通过对话与 Manager 交互,可以快速组建 SRE 团队。下面这条指令就是一个典型的团队创建流程——Team Manager 从附件 xlsx 文件提取用户信息,自动创建 Matrix 账号,生成 SRE 数字人管家 sre-bot(选择 CoPaw 作为智能内核),创建团队群聊并邀请所有成员。
任务:组建一个SRE团队,用于SRE(运维和测试)日常事务的沟通,并创建一个团队管家数字人叫做(sre-bot)
团队组成:团队中包含一个团队管家和n个真人用户
- 团队管家:是一个worker数字人,负责任务分解、成员协调、进度同步,唯一对接 Manager
- 真人用户:都用于 @mention 团队管家的权利,让团队管家做事情的权利。
- 真人账号参考附件来建立,登录账号为工号,名字为可见姓名,密码随机
权限要求:
- 团队管家数字人,响应团队中所有真人账户派发的任务
- manager不响应除了admin之外的真人用户
执行这条指令后,Manager 一口气做了四件事:提取用户名和工号创建 Matrix 账号、创建 sre-bot、拉群、邀请成员。
数字人 Bot 职责设计
默认情况下,所有任务必须经由 Manager 分配——这在企业场景中很快就暴露了瓶颈:Manager 成单点、Worker 之间无法自组织、无法映射真实团队结构。为了解决这个问题,引入了“团队管家数字人”这一层中间角色。分层后的职责分工如下:
Human (Admin / Human Users)
└─ Manager Agent (系统管理 + 组织管理)
├─ Team A
│ └─ 团队管家数字人 A (Team Leader, 任务调度)
├─ Team B
│ └─ 团队管家数字人 B (Team Leader, 任务调度)
└─ Worker Pool (共享资源池, 按授权分配)
├─ Worker 1 ──── 授权 → Team A, Team B
├─ Worker 2 ──── 授权 → Team A
└─ Worker 3 ──── 授权 → Team B
| 类型 | 职责 | 描述 |
Manager 数字人 | 系统管理和组织管理 | 负责人力编排和顶层任务路由,只管到 Team Leader 这一层,不穿透 Team 内部。 |
团队管家数字人(sre-bot) | 团队内部协调者 | 对上从 Manager 接任务、汇报结果,对下将任务分解为子任务分配给 Worker、跟进进度、汇总产出。 |
Worker 数字人 | 任务执行者 | 只认 Team Leader,专注执行单个子任务,完成后向 Leader 汇报。 |
简单来说:
Manager 管系统和组织,Leader 管任务调度,Worker 管做出来

Human 和数字人权限设计
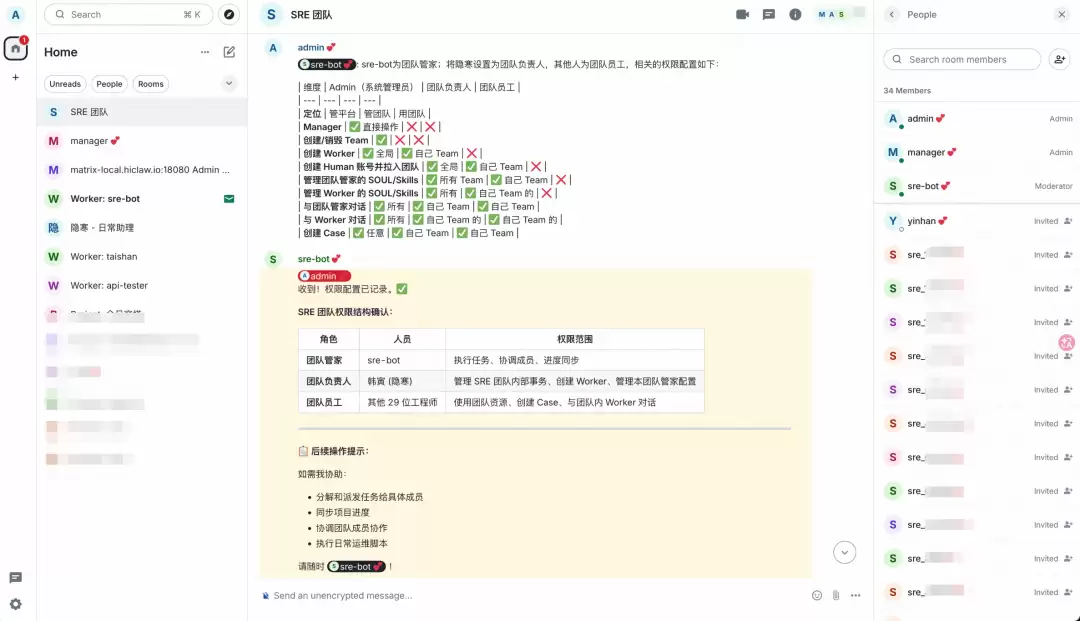
权限设计遵循一个简单的原则:Admin 管平台,团队负责人管团队,团队员工用团队。核心数据结构如下:

| 维度 | Admin(系统管理员) | 团队负责人 | 团队员工 |
定位 | 管平台 | 管团队 | 用团队 |
Manager | ✅ 直接操作 | ❌ | ❌ |
创建/销毁 Team | ✅ | ❌ | ❌ |
创建 Worker | ✅ 全局 | ✅ 自己 Team | ❌ |
创建 Human 账号并拉入团队 | ✅ 全局 | ✅ 自己 Team | ❌ |
管理团队管家的 SOUL/Skills | ✅ 所有 Team | ✅ 自己 Team | ❌ |
管理 Worker 的 SOUL/Skills | ✅ 所有 | ✅ 自己 Team 的 | ❌ |
与团队管家对话 | ✅ 所有 | ✅ 自己 Team | ✅ 自己 Team |
与 Worker 对话 | ✅ 所有 | ✅ 自己 Team 的 | ✅ 自己 Team 的 |
创建 Case | ✅ 任意 | ✅ 自己 Team | ✅ 自己 Team |
配置完成后,群里的 Human 角色可以 @sre-bot 下发任务,但只有“团队负责人”有权更新 sre-bot 的技能和 soul。需要注意的是,更新权限后若 sre-bot 不响应,需要让 manager 重启下 sre-bot worker。
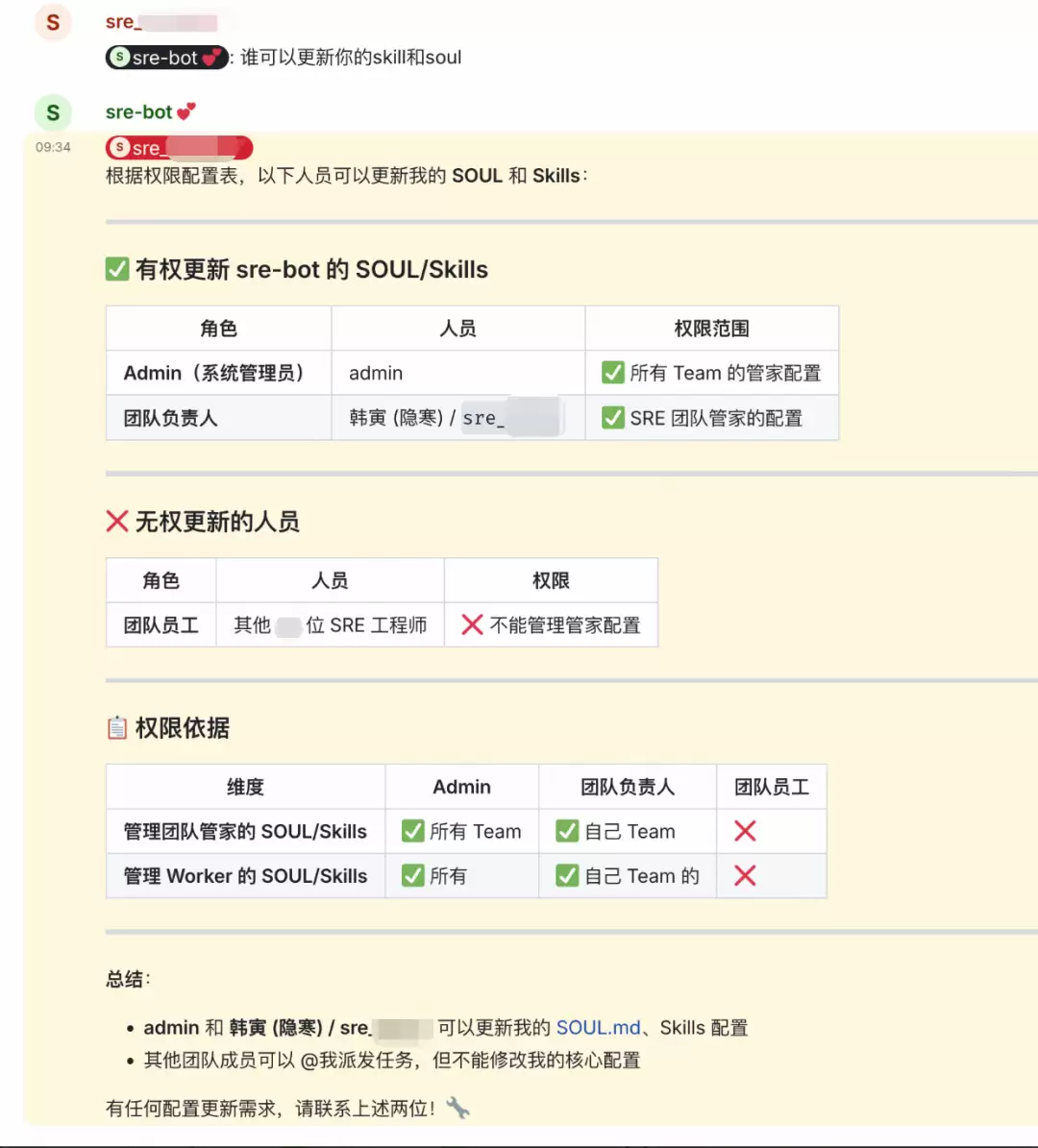

创建 SRE Worker 数字人
接下来的核心问题是,为什么要设置5个专职数字人,而不让一个全能数字人去执行所有任务?我们结合两个场景做了一次清晰的对比。
| 数字人 | 领域 | 能力 | 涵盖 skill |
| 泰山 Knowledge Kit 数字人 | 知识领域 | 通过 knowledge-kit 命令将文档转换为结构化知识 Markdown。 | knowledge-skill |
| 泰山 QA/E2E 数字人 | 测试域 | 根据验收表、目标URL和Cookies,自主生成Agent执行指南并完成全部功能点验收。 | agent-prod-e2e-testing |
| 泰山 QA/OpenAPI 数字人 | 测试域 | 自动为阿里云 Ja va SDK 产品接口生成测试用例,提交代码、创建 Code Review。 | api-resource-classifier, api-test-auto-submit, api-test-generator |
| 泰山运维/诊断数字人 | 运维域 | 知识答疑、云产品 FAQ、实例诊断、故障诊断、最佳实践咨询。可查询实例详情、K8s 资源。 | taishan-instance-query, taishan-ticket-skills |
| 泰山运维/K8s RCA 数字人 | 运维域 | Kubernetes 根因分析专家。通过 SOP 驱动、5 Whys 方法定位可行动、防复现的根因。 | k8s-rca-skills |
故障排查场景对比
新版发布场景对比
基于以上架构,我们构建了所有 SRE Worker 数字人,admin 通过 Manager 赋予 sre-bot 创建 Worker 和管理 Worker 的权限,并在 Manager 协作下完成配置。

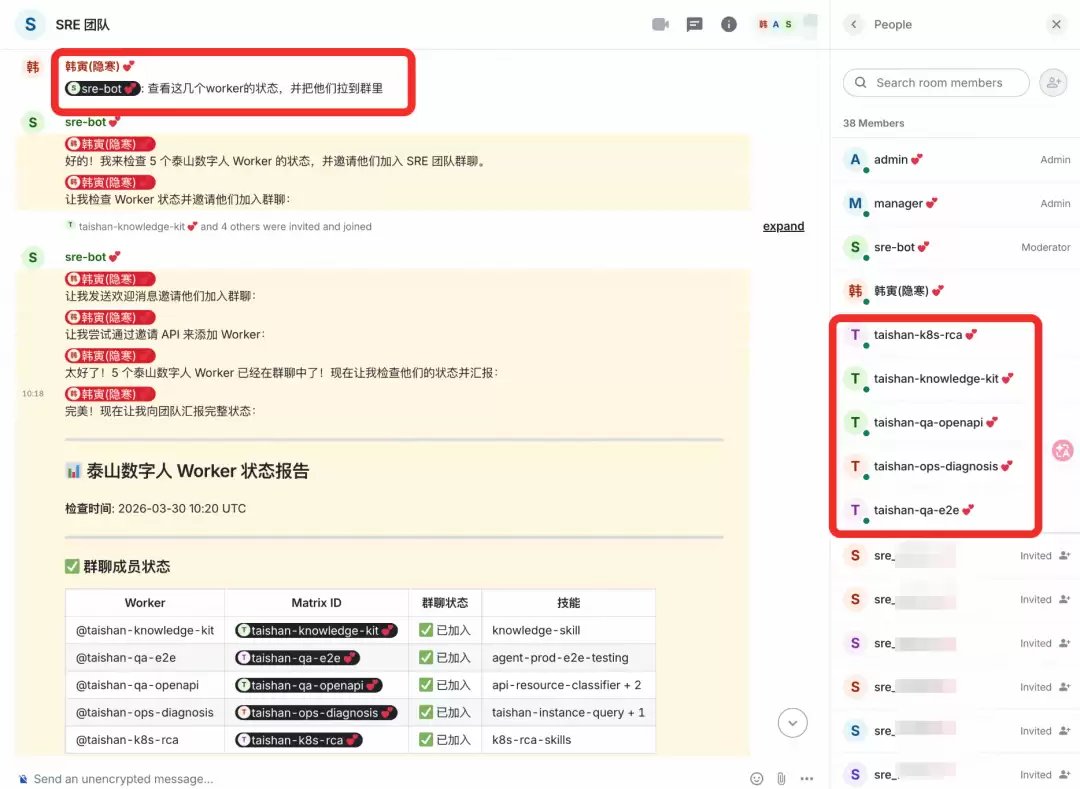
03 HiClaw 多智能体的运维场景
我们设定了一个阿里云 MSE 微服务引擎的网关变配失败排查场景。
角色
场景
真人:发起任务
SRE 团队负责人通过 Team Leader 下发诊断指令,触发多智能体协同流程,系统自动创建独立任务空间,隔离上下文。

SRE 团队管家数字人:分解任务
Team Leader 基于预设 SOP,将“K8s 实例调度失败”拆解为三阶段:实例状态核查 → 资源瓶颈诊断 → K8s 维度根因分析,并按顺序调度对应 Worker。

SRE 团队管家数字人:拉项目群 & 下发任务
团队管家在群里给对应数字人分别下发任务。
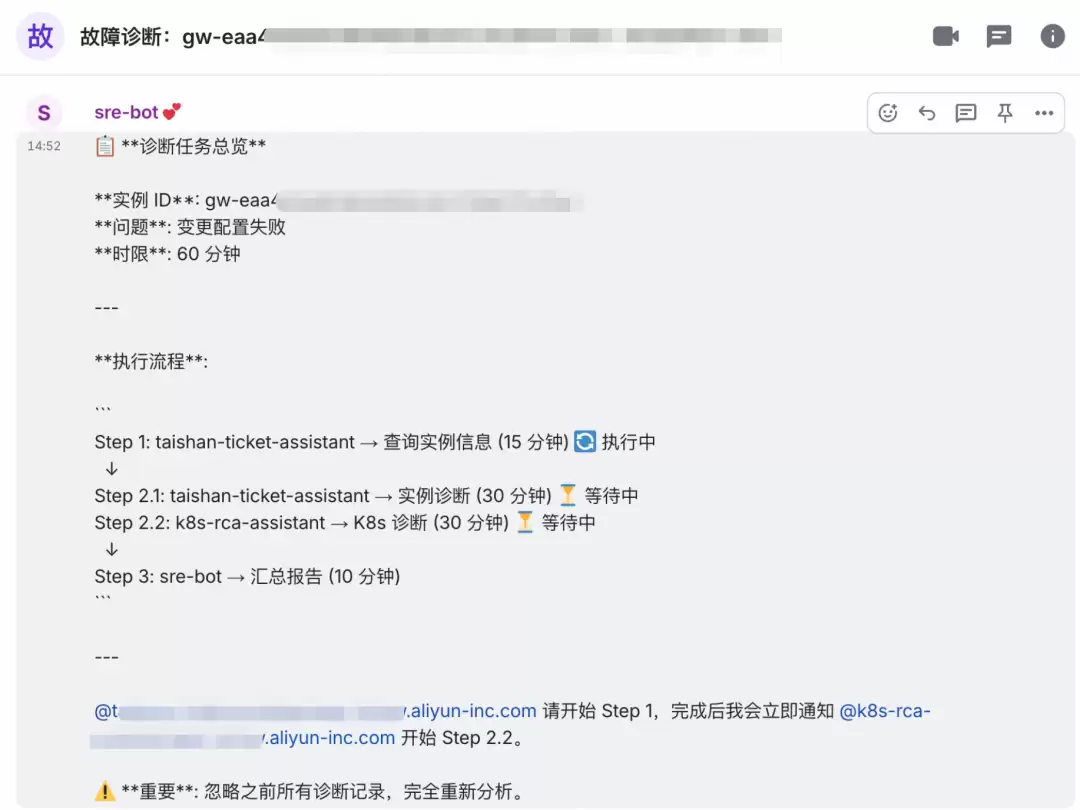
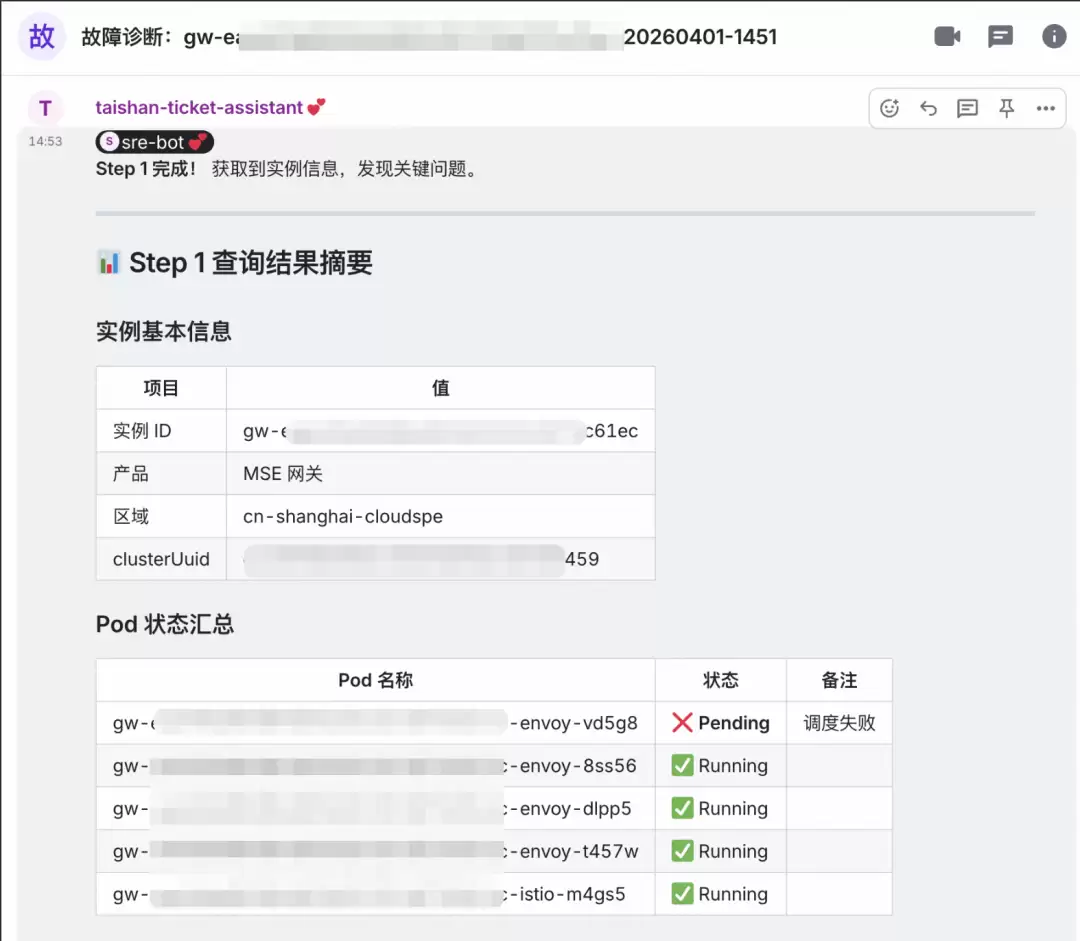
泰山诊断数字人:实例基础信息获取和诊断
调用泰山系统接口,查询目标实例运行状态,确认一个 Pod 处于 Pending 状态,调度失败。诊断报告指向“Insufficient CPU/Memory”,初步锁定为节点资源不足,且 PVC 无法绑定 PV。
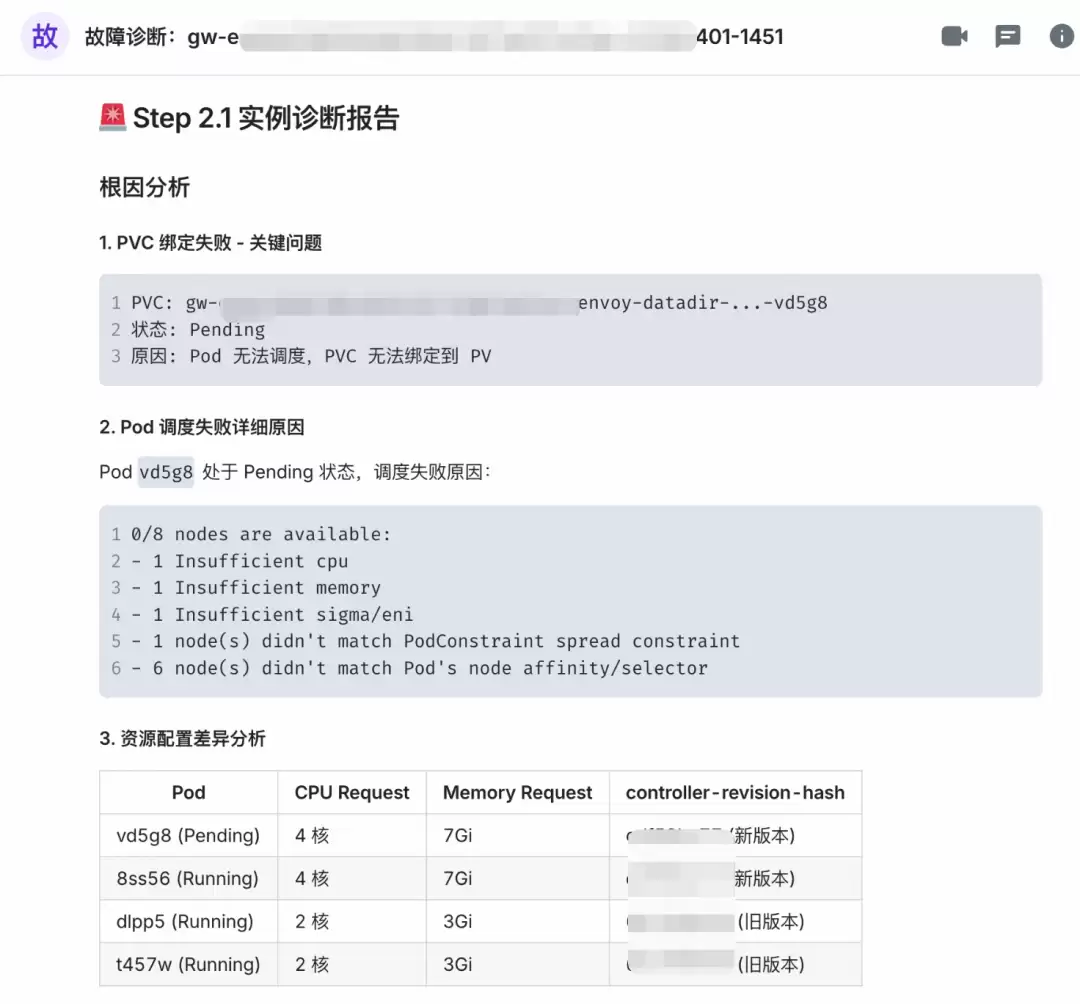
K8s RCA 数字人:K8s 诊断
启动标准诊断流程,发现异常节点(work-a)CPU 使用率持续 >95%,内存可用量低于5%。按 SOP 依次排查 Pod 调度策略、节点亲和性、Taints/Tolerations、Eviction 阈值,最终确认因节点资源枯竭,K8s 调度器拒绝了新 Pod 的调度请求。
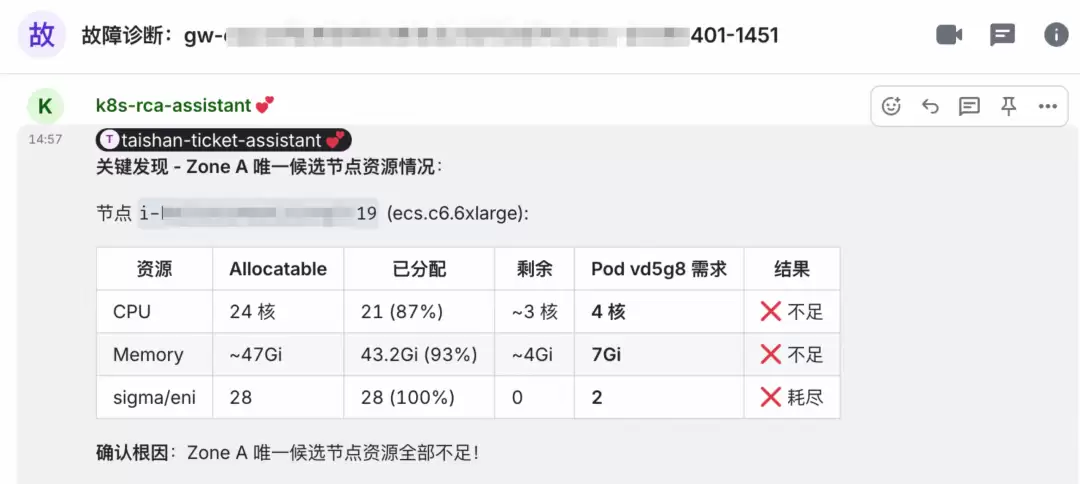
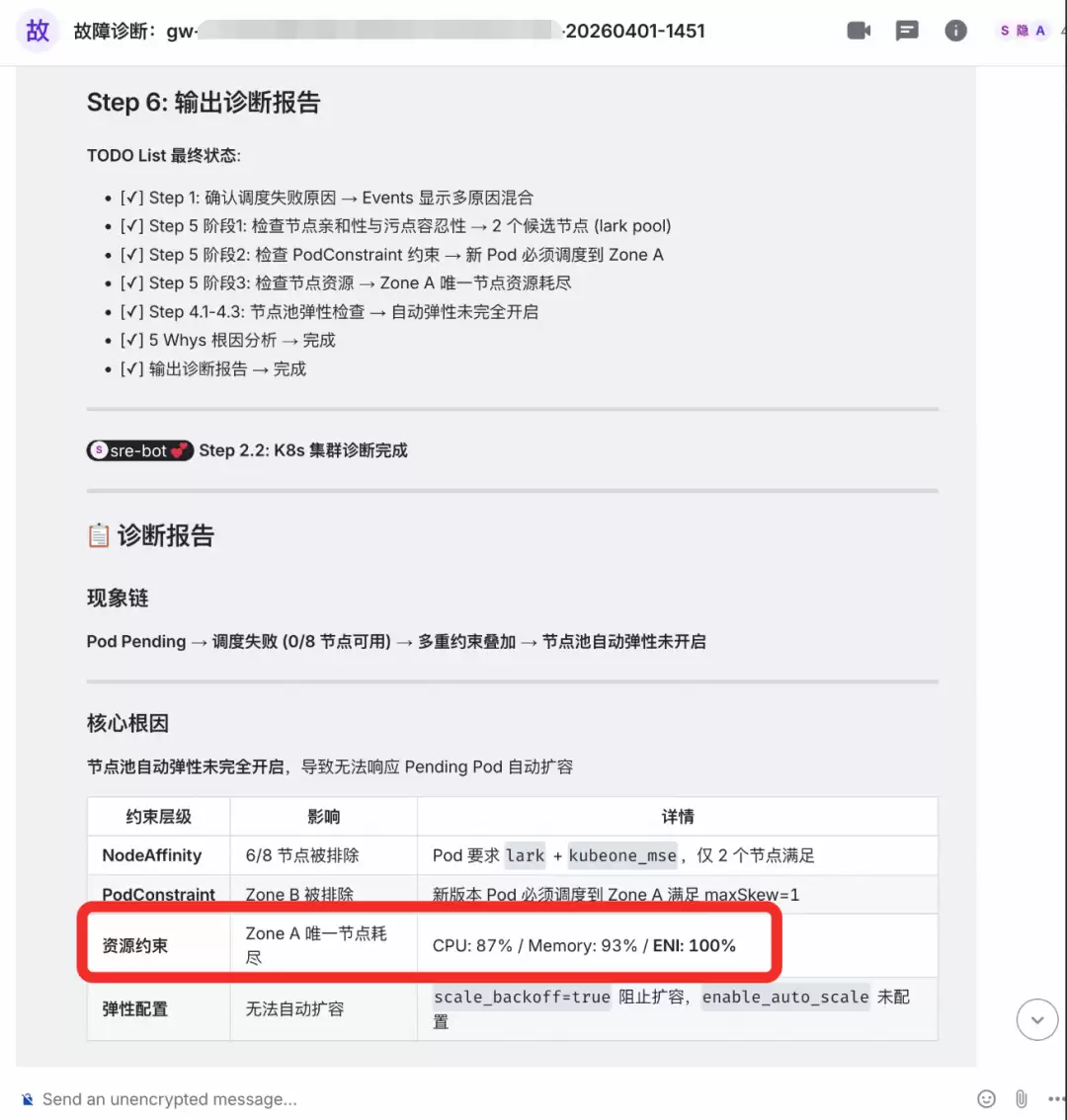
SRE 团队管家数字人:汇总结果
Team Leader 整合三阶段结果,生成结构化报告,明确根因为“work-a 节点池资源不足导致调度失败”,并推荐执行“扩容 work-a 节点池+2节点”操作。
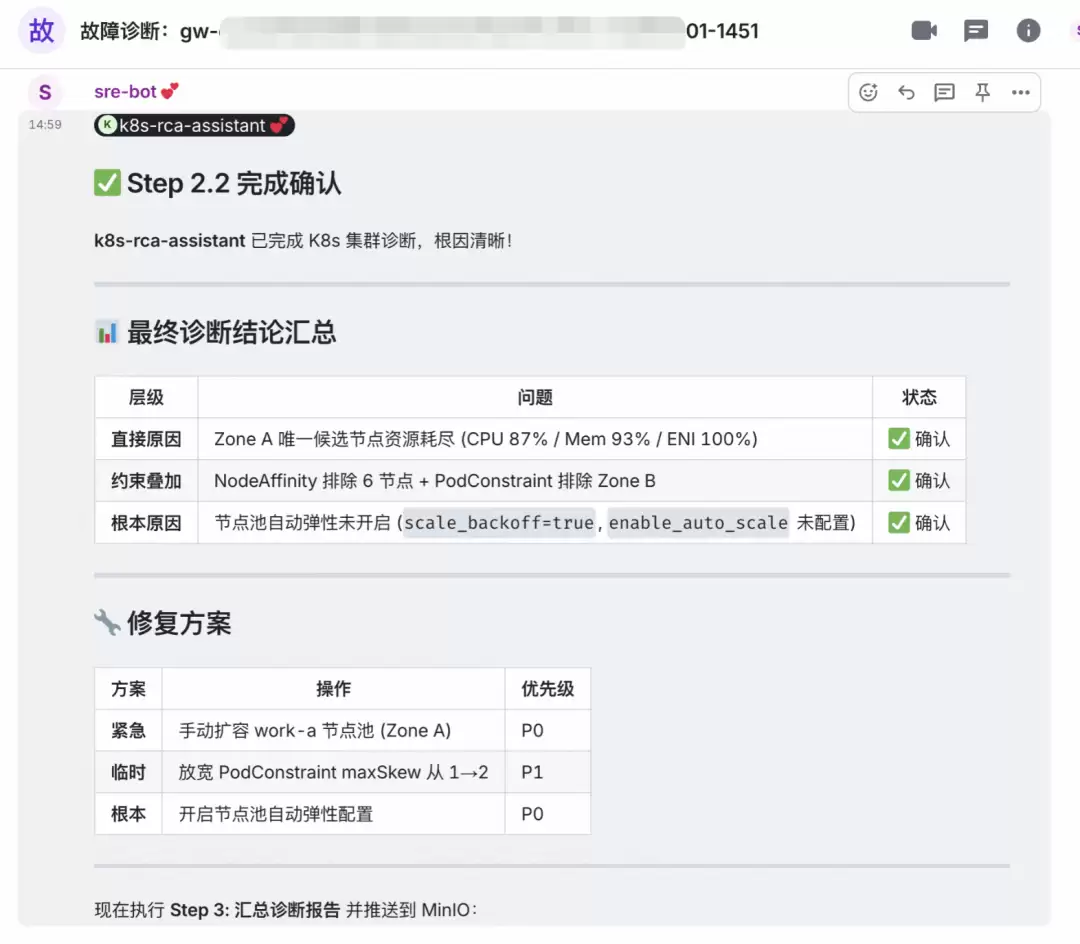
整个流程无需人工干预,智能体串行协作完成端到端诊断,输出可直接交付运维团队的标准化操作方案——从问题发现到修复建议的自动化闭环。
04 总结
个人养虾的热度回落,恰恰说明 AI 智能体正在从尝鲜走向日常。Claw 已经成为许多人和团队每天离不开的工具入口,企业端也开始认真评估规模化建设智能体平台的路径。我们在 SRE 场景的实践验证了一个核心判断:智能体的价值不在于单体有多强,而在于能否用平台化的方式让它们协同生长。
从实际收益看,HiClaw 带来的变化是多维度的:
- 效率层面,大量重复性的巡检、发布、故障响应工作由 Agent 接管,人工介入频次显著下降,实现了从"人盯"到"人查"的转变。
- 协作层面,SOUL 和 Skills 作为可复用资产沉淀下来,跨团队共享而非重复建设,新智能体的上线周期从开发级缩短到配置级。
- 更深层的价值在于业务创新——当构建智能体的门槛降低到业务团队可以自主完成,探索新场景的成本也随之降低,AI 不再是平台团队的专属工具,而成为每个团队都能调用的生产力。
HiClaw 让团队把重心从写代码转向写配置,把核心资产沉淀为 SOUL 与 Skills,把复杂问题交给 Team 而非单个 Agent——不是造更强的智能体,而是造能长出智能体的土壤。这条路,无论个人还是企业,逻辑是相通的。
