
我又把 Obsidian 知识库升级了:现在它能自己长出知识网络
之前写了两篇文章,把 Obsidian + AI 的基础管线跑通了——一套是 Hermes Agent 接入 Obsidian,另一套是用 Codex 搭了个不断进化的 AI 知识库。
它们解决的核心问题是:AI 能操作知识库了。
但跑了段时间发现:操作归操作,知识并没有真正“长”起来。Agent 确实帮你建了一堆页面,但页面之间是孤立的。打开 Obsidian 图谱一看——散的。毕竟当时只是为了跑通流程,没把重心放在图谱上。
这次升级的核心目标只有一个:让 Agent 借助 Obsidian 的 wiki link 能力,把一篇文章自动编译成互相关联的知识节点,在知识库里自己长出网络来。流程不再是“存 + 搜”,而是:文章 → Agent 拆解 → 概念页 / 实体页 / 比较页 / MOC → 每个页面用 [[wikilink]] 互相关联 → Obsidian 图谱中形成可视化知识网络。这就是本篇要讲的 Hermes-Wiki。

一、先搭一个 Hermes-Wiki 文件夹
这个文件夹要同时交给 Obsidian 和 Hermes 使用——Obsidian 负责可视化图谱和双链,Hermes 负责读写和建页。
为什么要分这么多子目录?因为得让 Agent 有能力“区分节点类型”。不同类型的页面在知识网络中扮演不同角色,不然它建的页面全是一个性质,双链就毫无意义。
建议结构长这样:
Hermes-Wiki/
├── SCHEMA.md
├── index.md
├── log.md
├── raw/
│ ├── articles/
│ ├── papers/
│ ├── transcripts/
│ └── assets/
├── concepts/
├── entities/
├── comparisons/
├── queries/
├── moc/
└── drafts/
核心原则就是一条:
不同类型的内容不要混在一起
- — 原始资料区。放文章、论文、转录稿、截图。原则:只追加只读,不修改原文。raw 是证据层,源头坏了后面全乱。
raw/ - — 概念页。比如 RAG、Agentic RAG、LLM Wiki、MOC、知识飞轮。这不是文章摘要,是跨资料沉淀的长期知识节点。
concepts/ - — 实体页。比如 Obsidian、Hermes、Claude Code、具体项目、某家公司。概念和实体必须分开,否则术语和人名工具名全混一起。
entities/ - — 比较页。比如 Hermes vs Claude Code、RAG vs Agentic RAG。适合长期更新,每篇新资料都可能补充新维度。
comparisons/ - — 值得保留的问答。不是每次聊天都存,解决重要问题的才沉淀。
queries/ - — 主题地图(Map of Content)。不是目录,是理解路线图。比如“LLM Wiki 地图”可以告诉你阅读顺序:raw → concept → MOC → Source-first → 知识飞轮。
moc/ - — 输出草稿。文章、推文、脚本、教程稿。知识库的终局是输出,不是收藏。
drafts/
二、真正的核心是这三个文件
这个 Wiki 里最重要的不是文件夹,而是三个根目录文件:SCHEMA.md、index.md、log.md。没有这三个文件,Agent 还是会乱。
1. SCHEMA.md:规则文件
SCHEMA.md 定义整个 Wiki 的规则,Agent 的所有行为受它约束:
- raw 是原始资料区,只能追加和读取,不要改写原文
- concepts 存放概念页
- entities 存放实体页
- comparisons 存放比较页
- queries 存放值得长期保留的问答结果
- moc 存放主题地图
- drafts 存放输出草稿
- 重要概念使用
wikilink - 关键结论尽量绑定来源
- 不确定内容必须标记为“待验证”
- 每次重要修改后更新
log.md - 新增重要页面后更新
index.md
不给规则,Agent 就会自作主张。今天建 summary,明天建 note,后天换一种命名——最后得到的不是知识库,是一堆 AI 生成的新垃圾。
特别强调:
“重要概念使用 wikilink”这条规则是整个知识网络能形成的底层前提
记住:让 Agent 稳定维护知识库,第一步不是给资料,是给 schema。
2. index.md:总入口
不用写复杂,早期三块就够:
# LLM Wiki Index
## 核心概念
- [[RAG]]
- [[Agentic RAG]]
- [[LLM Wiki]]
- [[Obsidian]]
- [[MOC]]
- [[双链交叉引用]]
- [[Source-first]]
## 主题地图
- [[RAG 技术地图]]
- [[LLM Wiki 地图]]
## 最近更新
待更新。
作用是让人和 Agent 一眼知道这个 Wiki 的入口在哪。
3. log.md:更新日志
每次新建/更新页面、标注来源、标记待验证项,都记进 log.md。
没有 log,AI 知识库就是黑箱
三、用 Obsidian 打开整个文件夹
文件夹建好之后,打开 Obsidian。选择“Open folder as vault”,然后选择整个 Hermes-Wiki 文件夹(不要选 raw/ 或 concepts/ 子目录)。Obsidian 和 Hermes 都需要完整结构。
打开成功后,你应该在左侧看到:SCHEMA.md、index.md、log.md、raw、concepts、entities、comparisons、queries、moc、drafts。Obsidian 侧准备完毕。
四、设置 WIKI_PATH,让 Hermes 找到它
接下来要告诉 Hermes:我的 Wiki 文件夹在哪里。这里最容易出错的是 Windows 用户。
如果你是在 WSL / Ubuntu 里运行 Hermes,那么 WIKI_PATH 要设置在 WSL 里,而不是 Windows PowerShell 里。Windows + WSL 用户可以用类似路径:
export WIKI_PATH="/mnt/c/Users/你的用户名/Hermes-Wiki"
Mac 用户一般可以用:
export WIKI_PATH="$HOME/Hermes-Wiki"
然后检查:
echo $WIKI_PATH
ls "$WIKI_PATH"
如果能看到这些内容,就说明路径打通了:SCHEMA.md index.md log.md raw concepts entities comparisons queries moc drafts
关键:
Obsidian 和 Hermes 必须指向同一个文件夹
五、先让 Hermes 只读,不要急着改
第一次启动 Hermes 后,不要一上来就让它写文件。先让它做初始化检查。
可以输入:
请读取我的 LLM Wiki。Wiki 路径使用环境变量 WIKI_PATH。先不要修改任何文件,只做初始化检查:
1. 读取 SCHEMA.md
2. 读取 index.md
3. 读取 log.md
4. 总结当前 Wiki 结构
5. 告诉我下一步应该收录哪些资料
验证标准:Hermes 能准确说出 raw/ 是原始资料、concepts/ 是概念页、moc/ 是主题地图、SCHEMA.md 是规则文件、index.md 是总入口、log.md 是更新日志。说对了,再进入下一步。
六、收录第一篇文章
现在可以做第一次真实测试。
比如你在 Obsidian 里进入 raw/articles/,新建一个 Markdown 文件,把一篇文章完整粘贴进去。然后在 Hermes 里输入:
请收录这篇文章:raw/articles/你的文章标题.md
注意:这是一篇文章草稿,请把它作为 raw 原始资料处理,不要修改原文。
要求:
1. 读取文章内容,提取核心主题。
2. 根据内容创建或更新对应的 Wiki 页面。
3. 重要概念使用 [[wikilink]]。
4. 关键结论必须标注来源:raw/articles/你的文章标题.md
5. 如果某些内容是总结归纳或待验证判断,请明确标记。
6. 更新 index.md。
7. 更新 log.md。
8. 如果适合,请创建或更新 moc/LLM Wiki 地图.md。
9. 完成后列出本次新增和更新了哪些文件。
四个要点:① raw 原文不要改;② 关键结论标注来源;③ 要求列出新增/更新文件;④ 更新 log.md。这四条确保这是一次可检查的知识编译,不是随手总结。
七、回到 Obsidian,看五个地方
Hermes 跑完后回 Obsidian 检查,重点看五个地方:
1. concepts — 概念页是否生成
应该能看到从文章中拆出的长期知识节点:LLM Wiki / RAG / Agentic RAG / MOC / Source-first / 知识飞轮。
2. entities — 实体页是否生成
概念和工具/实体应该分开:Obsidian / Hermes / Claude Code / NotebookLM。
3. moc — 主题地图是否生成
不是列清单,而是理解路线图:哪些是入口概念,哪些是进阶,哪些资料值得反复读。比如:LLM Wiki 地图 / RAG 技术地图 / AI 知识库地图。
4. log.md — 更新是否有记录
必须记录:新增/更新了哪些页面、来源文章、待验证内容、下一步建议。
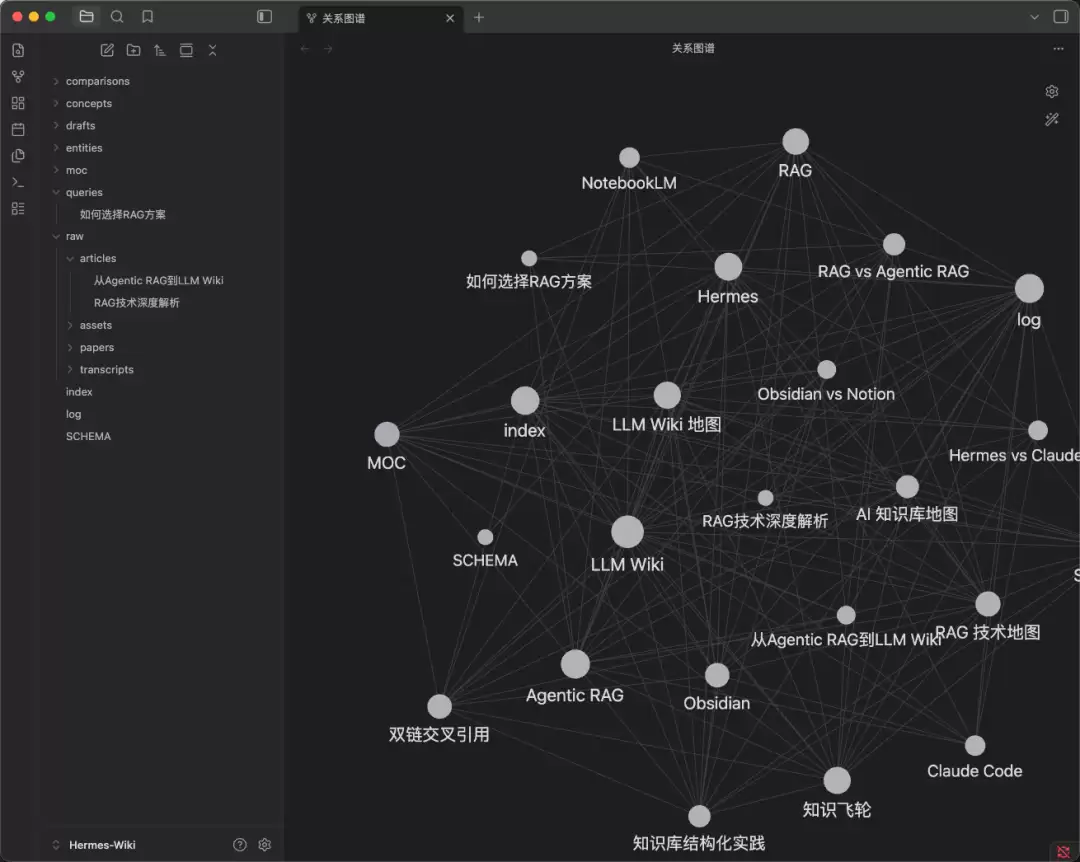
5. 图谱 — 是否形成网络(关键一步)
这才是本篇的核心验收点。打开 Obsidian 图谱视图。如果前面的 wikilink 规则生效了,你应该看到:concepts 里的概念页互相链接,entities 里的实体页和概念页交叉关联,moc 作为中枢节点把多个页面串在一起。
效果就是:一篇文章 → Agent 拆出 5-10 个页面 → 每个页面用 wikilink 互相链接 → Obsidian 图谱中形成可见的知识网络。文章越多,网络越密。这才是“知识库自己长大”的真正含义。
八、本质变化
和前面几篇的基础流程比,这次升级的关键差异不在“操作”,在“关联”:
- :文章丢进
从存资料到编译资料
raw/articles/,Agent 拆成概念、实体、MOC,每个页面都是可被引用的独立节点。 - :这是最核心的变化。Agent 不再只建页面,而是强制用
从页面孤立到自动关联
wikilink把每个新页面和已有页面关联起来。概念页连概念页,概念页连实体页,实体页连 MOC。 - :以前是“一篇文章 → 一篇总结”,现在是“一篇文章 → 多个节点 → 和已有节点自动关联 → 图谱越来越密”。文章越多,网络价值越大,不是线性叠加,是指数增长。
从线性输出到网络生长
九、最后提醒:不要一上来全自动
建议一开始保守操作:
- 只让 Agent 操作独立的
Hermes-Wiki,不要直接动主力 Vault。 - raw 原始资料只追加只读,不让 AI 改写。
- 每次生成后看
log.md,确认改了什么。 - 不确定内容一律标“待验证”。
- 先用 3-5 篇文章测试,命名、双链、MOC 规则稳定后再扩大到论文、转录稿。
AI 知识库最怕的不是不够自动,是自动生成一堆你自己都不信的东西。
总结
前面几篇解决了“AI 能操作 Obsidian”的问题,这篇解决的是“操作完能长出网络”的问题。
关键就三点,缺一个都不行:
- :让 Agent 强制建双链,没有这一步,图谱永远是空的。
wikilink规则 - :概念、实体、比较、MOC 各司其职,才有结构化网络,而不是一堆同质页面互链。
节点类型分离
- :知道每个节点从哪来、为什么创建,网络才可信。
log 追踪
人负责判断和审阅,Obsidian 负责存储和可视化,Agent 负责拆解和建链——三者打通,知识库自己就长起来了。
