
写个 Hook 截胡大模型:将零散的 AI 对话重塑为本地知识资产
一
同时开着好几个 Claude Code 的会话窗口。
一个在推敲怎么为独立开发的 App 接入用户反馈功能,一个在创建 logging-session skill,还有一个,正在基于 Obsidian 仓库中的工作资料,生成给领导的演讲稿。每个窗口都聊了多轮,调整代码、优化流程、纠正语感。
说实话,人并不是擅长多线程处理的生物,但在 AI 时代,为了不在等待模型「吐字」的间隙去无脑刷微博,被迫习惯了同时开几个窗口「压榨」时间。
不过伴随而来的问题,是对过程的记忆会变得相当模糊。也许最终会实现这个反馈功能,有一个好用的 skill,拿出一份能交差的演讲稿,但过程中和 AI 对于实现方案的探讨、权衡取舍、最终的妥协,都会在关闭终端的那一刻抛诸脑后。
另一方面,有定期复盘的习惯。当前复盘的上下文,来自 dailylog 文档、番茄钟数据以及 GitHub 上的 commit 记录。基于这些信息,能够让 AI 帮助总结出每周的成果,但仍然缺乏对于实现细节的分析。
在 AI 工具中产生的对话,是当下最真实的工作快照,但很少有人会去翻看它们,并且包含多轮交互的对话,期间夹杂着大量执行记录,并不适宜阅读。
面对这种算力与心力的双重浪费,于是决定写一个工具。它必须能在每次对话结束时,自动把「问了什么、想了什么、结果是什么」无感提取并保存下来。
二
保存会话的方式得满足两个条件。第一,支持记录多个项目的会话,独立开发、Obsidian 仓库或是自建的 skill,这些不同路径的项目会话应当能统一保存并加以区分;第二,得方便检索,而不是在一堆文本文件里 grep。
一开始也想过存 Markdown,每个项目一个文件夹,每次对话写一个文件。但试了试发现不行,一旦想跨项目做聚合,比如「过去 7 天做了什么」,就得写脚本遍历所有文件夹、解析每个文件的前置元数据、再拼接在一起。太折腾了。
也考虑过 JSON,一个项目一个大数组,往里追加就行。但 JSON 文件读多了要全量加载到内存,而且查「项目 A 最近 7 天的 bugfix 有几个」这种条件查询,还是得写代码遍历。
最终选了 SQLite。一个数据库文件,一张表,所有项目的会话记录都在里面。想查「这周项目 A 做了什么」,一条 SQL 搞定。而且 SQLite 是单文件数据库,放在 Obsidian 的 vault 里,iCloud 自动同步,走到哪都能用。
每次会话存储的信息,应当包括以下几个方面:
- 标识信息,比如唯一性 id,创建时间,项目名称,git commit 的哈希值;
- 完整内容,包括提出的问题,Agent 的思考过程,以及最终输出的结果;
- 关联性(
parent_id),有些会话是上一次的延续,串起来才能看到完整的线索; - 分类(
task_category),bugfix、feature、refactor 之类,后面做统计的时候按分类汇总很方便。
CREATE TABLE dev_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
project_name TEXT NOT NULL,
session_id TEXT NOT NULL,
parent_id INTEGER DEFAULT NULL,
task_category TEXT,
user_query TEXT NOT NULL,
thought_process TEXT,
final_result TEXT,
file_paths TEXT,
git_hash TEXT,
extra_metadata TEXT
);
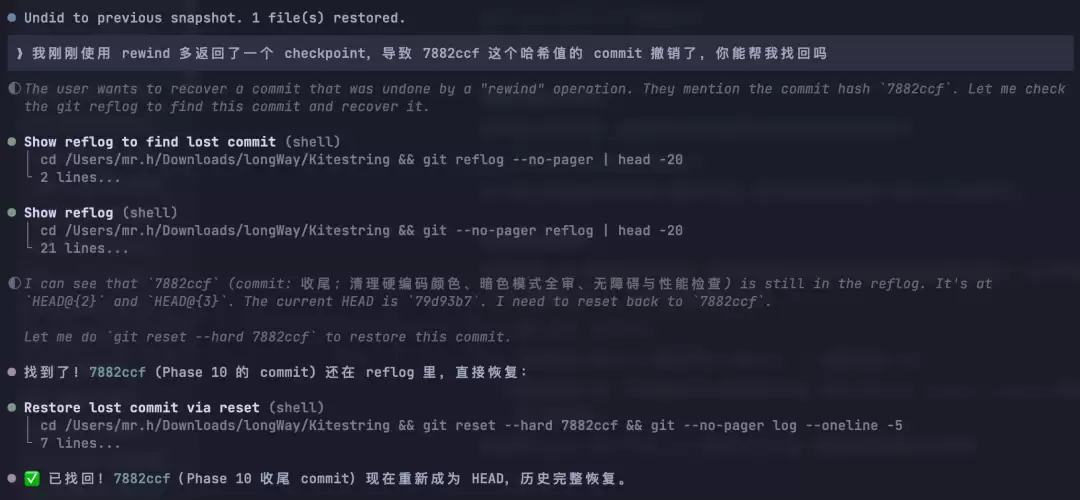
git commit 的哈希值本来是一个顺手记录的信息,但它居然真的发挥了作用:在 Claude Code 中使用 rewind 命令多返回了一个 checkpoint,导致最后一次提交的内容也被撤销了。
通过会话记录查询到了当时提交的 commit 哈希值,AI 在本地的 reflog 中找到了记录,并帮助恢复了文件改动。
三
想好了存哪,存什么,还得解决怎么存。
部分环境信息可以通过脚本来生成和获取,比如唯一性 id、项目名称等等,但 Agent 的执行过程只有它自己最清楚。
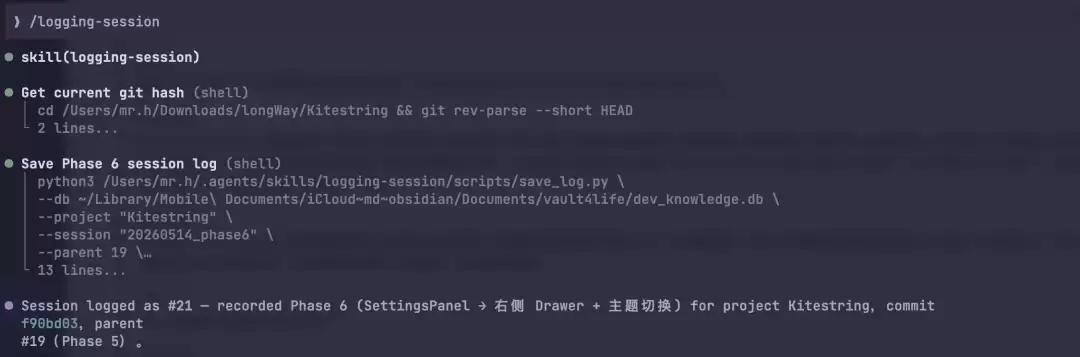
让 Claude Code 写了一个叫 logging-session 的 skill。在这份操作手册里写清楚了,对话结束时要提炼哪些字段、怎么生成会话 ID、项目名从哪里获取、查询脚本怎么调用。
实际效果是这样的。对话结束,输入 /logging-session,Claude Code 会自动从当前对话中提炼出三个东西:用户的问题是什么、中间的思考过程是怎样的、最终做到了什么。然后生成一个会话 ID,从当前目录拿到项目名和 git hash,调用写入脚本,一条记录就存进数据库了。
比如刚修完一个登录页的 bug,记录下来长这样:
python3 scripts/sa ve_log.py --db ~/Library/Mobile Documents/.../dev_knowledge.db --project "my-app" --session "20260514_a3f2" --query "修复登录页面特殊字符崩溃" --thought "排查发现是正则表达式写错,特殊字符匹配时抛出未捕获异常" --result "修改了 src/auth/validator.ts 中的正则" --category "bugfix" --files src/auth/validator.ts
查的时候更简单。想看这周做了什么,一条命令出结果,还能直接导出成 Markdown 文件塞进 Obsidian。
python3 scripts/query_logs.py --db ~/Library/Mobile Documents/.../dev_knowledge.db --project "my-app" --days 7 --format markdown
输出是按日期分组的 Markdown,每个条目包含问题、思考过程和结果。导出的效果大概长这样:
## 2026-05-14### 修复登录页面特殊字符崩溃- 项目:my-app- 分类:bugfix思考过程:排查发现是正则表达式写错,特殊字符匹配时抛出未捕获异常最终结果:修改了 src/auth/validator.ts 中的正则---### JWT 迁移到 session 方案- 项目:my-app- 分类:refactor思考过程:先试了无状态方案但与权限中间件冲突,换有状态方案,踩了 Cookie SameSite 的坑最终结果:完成迁移,修改了 src/middleware/auth.ts 和 src/config/session.ts
直接在 Obsidian 里就能看。如果想把每周的总结存下来,加一个 --output 参数指定文件路径,Markdown 文件就直接写进 Obsidian vault 了。
使用过程中,观察到一个有趣的现象:让 Agent 执行一个分阶段的任务,要求它每次执行完之后停止并等待指令。在它停止后,手动执行 logging-session 。
在同一个会话中连续重复这一过程 3 次后,它在第 4 次直接执行了 skill 中的脚本,甚至没有调用 skill 本身。
这大概率是因为当前会话上下文中「对话结束 -> 调用记录工具」这种高度重复的模式,让模型在预测下一个动作时,「调用工具」这一行为的概率被历史记录无限放大。虽然这让模型看起来很「聪明」,仿佛已经具备了主观能动性,但却造成了麻烦——仍然手动执行了 skill,导致会话记录重复,反倒显得迟钝一点。

到这里,手动记录的链路跑通了。但有个问题,手动记录靠的是人记得去执行。而人,是会忘的。
四
需要让记录变成一个不需要人记得的动作。
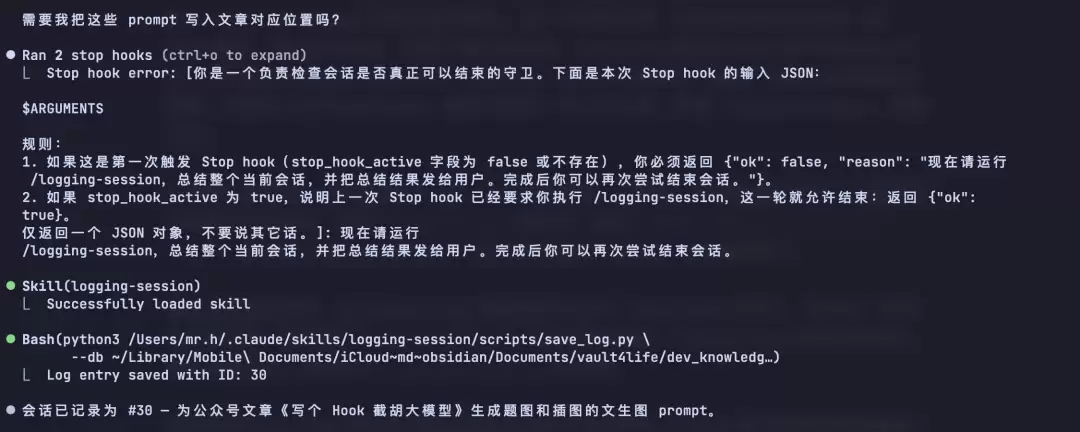
Claude Code 有一个 hooks 机制,可以在特定事件发生时触发自定义行为。其中有一个事件叫 Stop,在 Claude 完成回复时触发。一开始想的是,在对话结束时自动跑一段 shell 脚本,把记录写进去。但翻了翻文档发现,command 类型的 hook 拿不到对话上下文,它只能执行固定的 shell 命令。没法让一段 shell 脚本去「理解」对话内容再提炼成摘要。如果用 command hook,最多只能写一条占位记录,写着「Session ended」,聊胜于无。
后来发现还有 prompt 类型的 hook。它不是跑脚本,而是把一段指令塞给模型,让模型自己判断该不该放行。返回 {"ok": true} 就放行,返回 {"ok": false, "reason": "..."} 就拦截,reason 会作为下一轮的指令发给 Claude。这就有意思了。
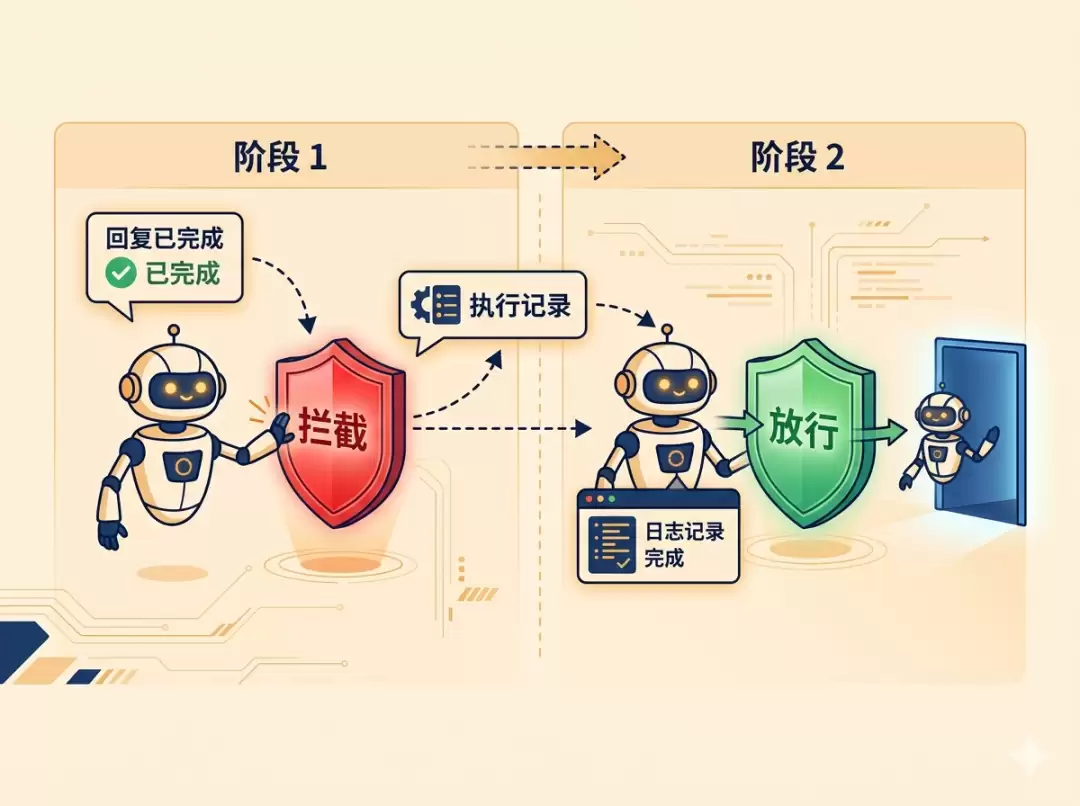
方案是这样的。当 Claude Code 准备结束对话时,Stop hook 拦住它,告诉它「你还没记录会话,先去跑 /logging-session,跑完再来结束」。Claude Code 收到这条指令,就会继续工作,自动执行 /logging-session 做总结。
但这里有个坑。Stop 事件不只是主动结束对话时触发,Claude 每次回复完都会触发一次。也就是说,如果 hook 每次都返回「不行,去记录」,Claude 就会在每一轮对话结束后都试图去跑 /logging-session,陷入无限循环。
所以得有一个判断机制。Claude Code 的 Stop hook 设计里自带了一个字段叫 stop_hook_active,第一次触发时是 false,当 hook 返回 {"ok": false} 后,下一次触发时这个字段就变成 true。在 hook 的指令里写清楚了这个规则,第一次 Stop 拦截,第二次 Stop 放行。
从用户的角度看就是,每次会话结束,Claude Code 自动多做一步记录,然后才退出。全程不需要手动操作。
具体配置放在 ~/.claude/settings.json 里,类型是 prompt,让模型自己判断是否放行。
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "prompt",
"prompt": "你是一个负责检查会话是否真正可以结束的守卫……n1. 第一次触发(stop_hook_active 为 false),返回 {"ok": false},要求执行 /logging-sessionn2. 第二次触发(stop_hook_active 为 true),返回 {"ok": true},放行"
}
]
}
]
}
}
这个两阶段机制听起来有点绕,但实际用起来是无感的。正常对话,该结束就结束。唯一的区别是,结束前会多出一条消息,Claude Code 告诉你它已经把这次会话记录下来了,顺手给出一个记录 ID。
配置完 hook 之后每次会话记录都会自动写入本地数据库,没有一次需要手动输入 /logging-session。以前不记录是常态,记录需要额外操作。现在反过来了,记录是自动发生的,不记录才需要额外干预。
当然也有边界情况。比如只是在对话里问了一个简单的问题,不涉及任何编码,hook 也会触发,Claude Code 也会记录一条。这种记录没什么信息量,但也不碍事,查询的时候按 task_category 筛掉就行。如果觉得烦,可以在 skill 的操作手册里加一条规则,只记录有实际编码操作的对话。
以及正在使用的 Copilot CLI,它的 hook 机制则不像 Claude Code 这样强大,不支持 command 类型的 hook, 就只能在每次对话结束后,自己手动触发了。
五
SQLite 数据库中存储的信息并不能直接查阅,需要借助专门的软件比如 Na vicat,或是 VSCode 插件、命令行,然而希望能有更加轻量快捷的方式。
之前介绍过的个人 dashboard,可以查看 dailylog 笔记和番茄钟数据,这次将和 AI 对话的记录也加了进去。
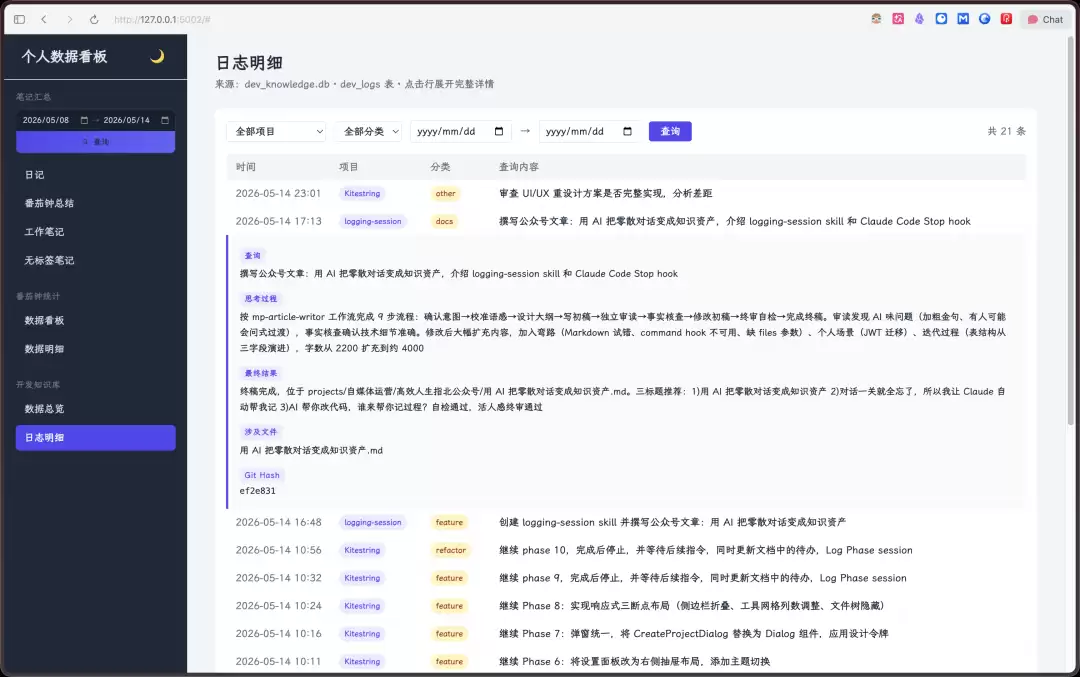
终
现在每次结束对话,Claude Code 都会自动帮助沉淀会话内容。那些之前关掉终端就忘了的工作过程,现在都在数据库里,下周复盘的时候跑一条命令就能翻出来。
这本质上还是之前那篇《数据主权:Obsidian 的本地存储在 AI 时代更香了》背后思考的延续。
番茄钟数据存本地 SQLite,能自己做统计页面对比时间开销;Dailylog 在本地 Markdown 文件里,用脚本就能按需查询;现在,AI 的对话记录也回到了本地。它们共同遵循着一个极其朴素的原则——
先有数据,再用 AI 加工
回头审视,无论是 dailylog 中的灵光一闪、番茄钟里的时间刻度,还是现在数据库里与 AI 的思维碰撞,在探索 AI 的过程中,不自觉地将自己尽可能「数字化」了。它们不仅是工作的产物,更是数字生命的快照。
这也许就是拥抱 AI 的方式吧。
