
如无必要勿增实体:我放弃了LLM Wiki,用Claude极简重构个人知识库
用Claude重构个人知识库:从信息泥沼到极简工作流
有了Claude之后,最想干的一件事,是把过去几年散落在各处的东西好好整理一下。
一部分在语雀——会议记录、月报、项目复盘、临时想法;一部分在桌面——本地文件夹里堆着PPT、Excel、PDF、截图、草稿;还有一部分是自己收藏的别人的产品、运营、营销、设计经验。这些东西单看都挺有用,但凑在一起就很麻烦:要找人找不到,要讲时讲不清,要复盘时发现同一个项目散在好几个地方。
所以最初的目标很朴素:不是做一个多酷的工具,而是把这些内容整顿成一个清晰可读、方便调用、真正属于自己的知识库。
结果刚起步就碰了壁。

真正的麻烦不是文件多,而是来源太多
起初以为,先把本地文件夹整理好就行。后来发现不对——很多重要内容其实沉淀在语雀里:过程记录、会议讨论、项目背景、当时的判断逻辑,往往都不在桌面文件里。
但语雀也不好用。它适合写文档,却不适合做全局结构管理;本地文件适合喂给AI和做原始素材库,却不适合手机随时查。还想要一个更直观的工作台——像个人博客或导航页一样,能快速看到整个知识库长什么样子。
于是问题变成了:三个地方怎么协同更好?
和Claude讨论下来,拍板了一个关键原则:
单一主源
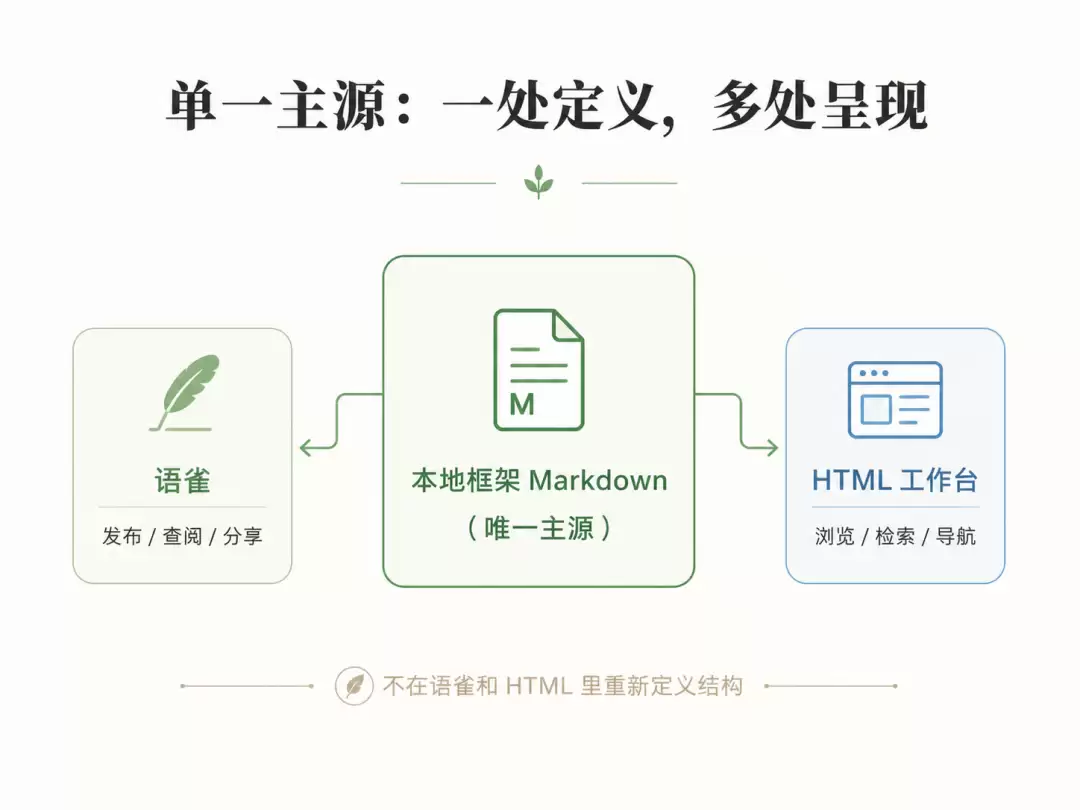
从第一个项目开始,逐渐形成的工作流
确定单一主源之后,事情才真正顺起来。先从第一个项目入手,和Claude基本形成了一个固定流程:
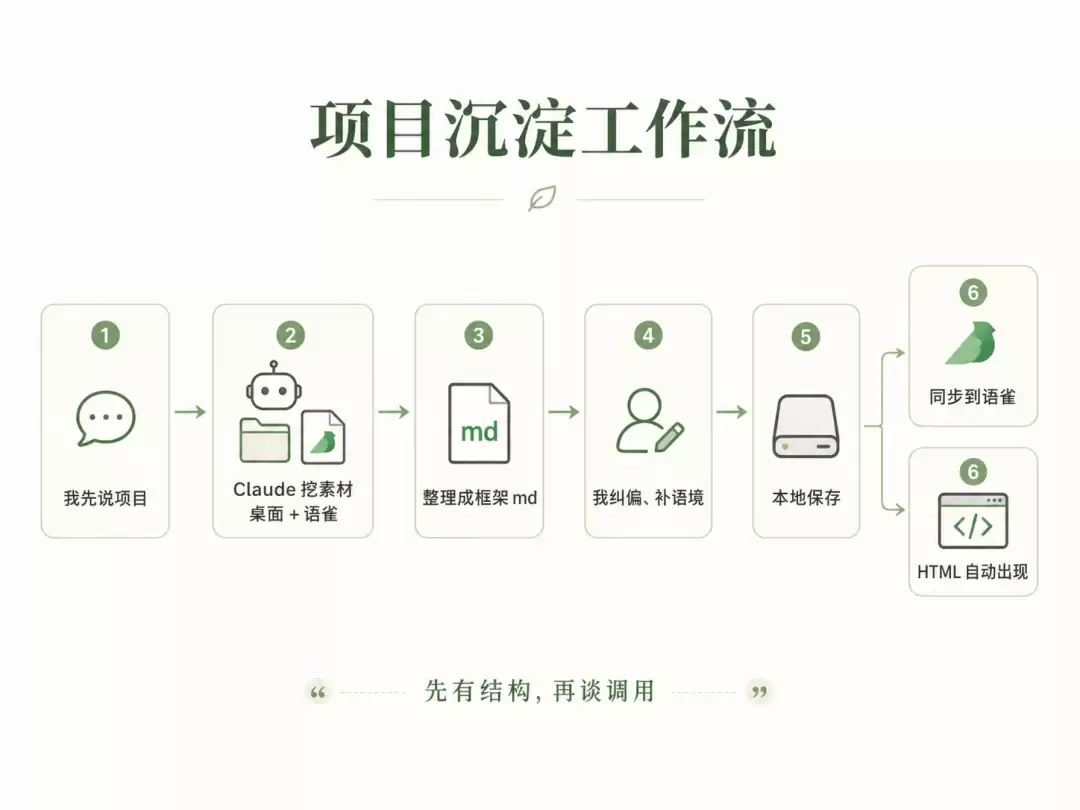
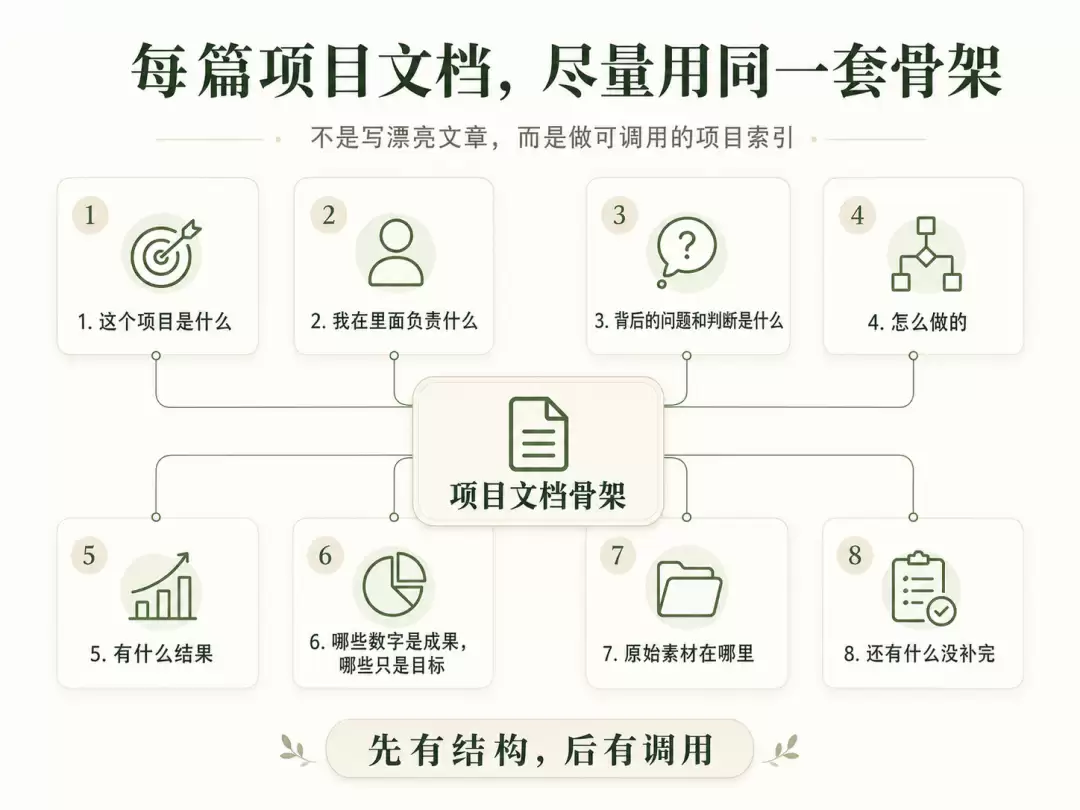
这套结构是在给未来的自己做一个可调用的索引。以后要讲项目、写述职、做简历、复盘方法论,不用再从20个PPT里翻来翻去。先看框架md,必要时再顺着素材索引回到原始文件。
最后初步的html工作台大致长这样,逐步完善中:
过程中的踩坑经验分享
第一,别一上来就全量丢给AI整理
最初也有冲动:既然有AI,那能不能把所有语雀和桌面文件都摄取一遍,让Claude先帮我总结?后来发现这很危险。全量摄取很容易把知识库变成第二个AI生产的垃圾堆。因为资料一旦太散,AI会尽量帮你归纳,但它并不知道哪些真正重要,哪些只是临时文件,哪些是自己的项目,哪些只是收藏的别人的经验。
后来换了方式。不是先把所有东西丢进去,而是先从一个具体项目开始。先判断:
- 这个项目是不是自己做的?
- 在里面到底负责了什么?
- 哪些资料能作为证据?
- 哪些只是背景或参考?
再让Claude去本地和语雀里找材料、补证据、搭框架。这个顺序很关键:自己定义主线,AI负责佐证和组织。
第二,必须分清“我做的”和“我参考的”
资料里混着两类东西:一类是自己做过的项目,一类是收藏的别人的案例、行业报告、方法论分享。AI很容易把它们混在一起——它看到一篇写得很完整的案例,就会以为那是你的项目。但这件事一旦混了,后面所有能力包装都会变得不可靠。
所以现在会强制区分:
- 自己做过的项目,进入主线项目沉淀
- 别人的经验,只能作为外部旁证、参考方法、视觉素材
- 拿不准的,先标“待确认”,不要替自己认领
第三,少建新概念,能并入就并入
知识库最容易膨胀。每看到一个有用点,就想单独建一篇。但越到后面越觉得,如无必要,勿增实体。一个东西如果只是某个项目里的补充,就应该进那个项目;如果只是某篇材料的索引,就放在参考台;只有真的能跨多个项目复用,才值得单独抽成概念。
比如AI评测能力,本来可以单独开一篇“能力矩阵”,但其实它更应该并进已有的AI内容评测体系。否则概念越长越多,最后又会变成另一套维护负担。
与LLM Wiki的关系
最初也想参考LLM Wiki这个著名的skill思路。大意是:让LLM把原始资料持续整理成一个结构化、互相关联、可以长期调用的markdown wiki。这个想法很吸引人——因为它解决的不是一次问答,而是一个长期问题:怎么让知识越用越厚,而不是每次都从零开始问AI。
但真正看了一圈之后,发现自己并不适合照搬。一方面,LLM Wiki更像一个通用的知识库工程范式,关注sources、concepts、entities、links这些结构。它适合做研究型资料库,或者给AI Agent准备长期上下文。但问题不是“怎么把资料自动编译成知识图谱”——问题更具体:
- 过去几年到底做了哪些项目
- 哪些是自己的成果,哪些只是组织口径
- 哪些是自己做的,哪些是别人经验
- 这些东西以后怎么服务述职、简历、复盘、表达
所以最后只吸收了LLM Wiki的三个思想:
- 知识要持久化,不要只停留在聊天记录里
- 原始资料要被结构化提炼,而不是简单堆进去
- 知识库要能被后续AI继续读取和使用

所以不把它叫“照搬LLM Wiki”,而是理解成:用LLM Wiki的思想,做一个职业经历和能力沉淀版本的个人知识库。这也解释了为什么没有一上来就追求自动化、互链、图谱,而是先花大量时间整理项目框架——因为最核心的不是“知识点之间怎么连”,而是“能不能把自己讲清楚”。
后面怎么维护
整理到后面,发现这个知识库其实分成了两条轴。
一条是纵轴:自己的项目和能力成长。每个项目都沉淀成一篇框架文档,最后再汇总到能力主轴里。
另一条是横轴:外部知识怎么被吸收。别人写的产品经验、运营方法、设计参考、行业报告,不是简单收藏,也不是全部搬进来,而是判断它能补到纵轴的什么位置。这样一来,知识库就不只是“我做过什么”的档案,也变成了一个持续吸收外部经验的系统。
现在给自己定了一个很简单的维护逻辑:入口少一点,节奏固定一点。
1)新资料先进入参考区,不急着进主线
以后看到新的外部资料、会议记录、设计稿、行业报告,不会马上把它塞进正本文档。先放到参考区,判断它属于哪一类:
- 能补项目证据
- 能补方法表达
- 只是视觉或素材参考
- 暂时无关,只留档
只有前两类,才值得进入主线。这条规则可以防止知识库重新膨胀。
2)定期做一次“清洁”
至少要有一个轻量的清洁动作,比如每个月或每个阶段结束时看一次:
- 哪些参考资料已经内化了,可以标状态
- 哪些待核对数字该补来源了
- 哪些新概念其实可以并回已有文档
- 哪些项目已经有新进展,需要更新“结果/待补”
知识库不是写完就结束,它更像一个持续对齐的系统。
3)AI的角色也要固定
后面会尽量让AI做这几类事:
- 从新材料里找和已有项目相关的证据
- 判断应该进入正本文档、参考台,还是只留素材索引
- 检查数字口径有没有“成果/目标/规模口径”混在一起
- 发现重复文档、重复概念、已经过期的状态
但最后拍板还是自己来——因为知识库真正服务的是自己的判断,不是AI的完整性冲动。
做完之后的感受
做完之后最大的感受是:AI确实很适合帮人整理知识库,但前提是你得先有判断。如果只是把一堆文件丢给AI,让它“帮我总结一下”,它大概率会给你一堆看似工整、但用不起来的文字。
这不是一个“AI帮我自动生成知识库”的故事。更准确地说,它是一个借助AI,把自己过去几年做过的事、学过的东西、踩过的坑,快速重新整理成一套可以被调用的系统的过程。
而且越整理越发现,知识库最重要的不是“存了多少”,而是当需要讲清楚一个项目、一个能力、一个判断时,它能不能立刻帮我们把证据、逻辑和素材串起来。如果能,那它就不只是仓库——它就是工作记忆。
