
Orchestrator 为什么比 Agentic Loop 快:LLM 决策与执行分离的架构解析
先从一个简单的例子说起。一个典型的 agentic loop,说白了就是一个 while 循环——LLM 在里头发号施令:先决定干什么,然后调用工具,观察返回结果,再接着做下一个决定。听着挺顺理成章,对吧?
这套模式确实能用,但有个让人头疼的问题:烧钱。来看一组实际数据——同样是处理一个涉及三个 agent 的查询,用 agentic loop 需要 7 次 LLM 调用,耗时 4.2 秒,花费 0.12 美元;而改用 orchestrator 模式,只需要 2 次 LLM 调用,1.1 秒,0.03 美元。同样的 agent,同样的答案,成本却差了 70%。
问题出在哪儿?循环每转一圈,就是一次 LLM 调用。每次调用不光多花 300~800 毫秒的延迟,还多掏真金白银。一次简单的“先调 check_greeting,再调 handle_hi”,两次 LLM 路由看起来还行,可一旦变成“为单个答案并行调三个 agent,按顺序执行,步骤 2 又依赖步骤 1”,再加上生产环境每秒几百个请求,agentic loop 立马就扛不住了。LLM 卡在每一次决策的关键路径上,每次循环都像在路上加了个减速带。
所以最直接的解法就是:让 LLM 只规划一次,然后别让它插手执行。
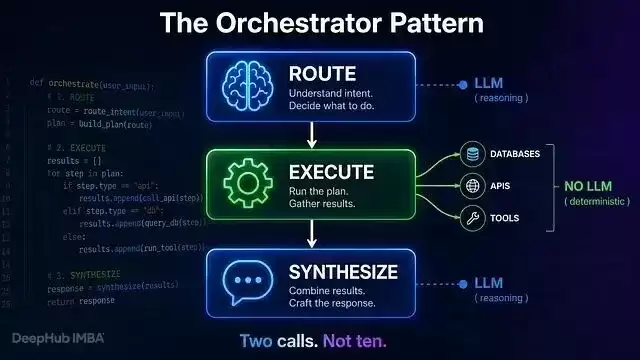
Orchestrator 模式只需要两次调用,不是十次
整个架构其实就三步:
User Query
↓
[STEP 1: ROUTE] ← 一次 LLM 调用:"哪些 agent 来处理?"
↓
[STEP 2: EXECUTE] ← 无 LLM:确定性调用 agent
↓
[STEP 3: SYNTHESIZE] ← 一次 LLM 调用:"把结果写成好答案"
↓
Final Answer看到关键了吗?LLM 只被请求两次——一次定计划,一次写答案。中间全是应用代码在跑。没有循环,没有不确定性,更没有“LLM 会不会又莫名其妙调一个工具?”这种让人血压飙升的问题。

举个例子,一个处理三种查询类型的 orchestrator 大概长这样:
- 单 agent——"当前系统指标?" → 路由到一个 agent
- 并行扇出——"给我指标和趋势分析" → 同时调两个 agent
- 顺序 DAG——"检查异常,有则拉配置" → 按依赖顺序调 agent
同样的 agent,同样的工具,但 LLM 只做一次路由决策,剩下全是应用在执行层面搞定。
Agent 注册表作为发现协议
Agent 用一个简单的字典注册能力。不需要复杂的发现协议——你自己部署的 agent,你心里清楚它们能干什么:
REGISTRY = {
"data_agent__get_report": {
"agent": "Data Agent",
"description": "Fetch the latest report for a given entity",
"execute": get_report,
},
"analytics_agent__get_trends": {
"agent": "Analytics Agent",
"description": "Get historical trends and anomaly detection",
"execute": get_trends,
},
"config_agent__check_config": {
"agent": "Config Agent",
"description": "Check system configuration for a given component",
"execute": check_config,
},
}线上部署时,注册表放在 Redis 或数据库里,agent 通过 HTTP POST 注册即可。模式始终不变——技能名到执行函数的查找表。
LLM 把 agent 当成工具定义(JSON schema)来看,但重点在于第四个元工具:
{
"name": "plan_execution",
"description": "Use this ONLY when the query requires sequential steps "
"where a later step DEPENDS on the result of an earlier step.",
"parameters": {
"properties": { "reason": {"type": "string"} },
"required": ["reason"]
},
}注意,plan_execution 本身不调用任何 agent——它什么都不做。它就是一个信号,而不是函数。当 LLM 选中它时,orchestrator 就知道该切换到顺序模式了。一次 LLM 调用、一组工具选择、三种执行策略——单 agent、并行、顺序——全都由返回的工具决定。
第一步:一次 LLM 调用统管的路由器
路由器用 temperature=0.0(确定性)做一次 LLM 调用。LLM 唯一的工作就是选工具,并且明确告诉它不要回答问题。
SYSTEM_PROMPT = """You are a query router. Your ONLY job is to decide which tool(s) to call.
Rules:
- If the query needs ONE agent, call that one tool.
- If the query needs MULTIPLE INDEPENDENT agents, call all of them.
- If the query needs steps IN ORDER, call plan_execution.
Do NOT answer the user's question — just pick tools."""单次调用:
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": query}],
tools=TOOL_DEFINITIONS,
tool_choice="auto",
temperature=0.0,
)整个路由逻辑非常简单:
tool_names = [tc.function.name for tc in reply.tool_calls]
if "plan_execution" in tool_names:
→ mode = "sequential"
elif len(tool_names) == 1:
→ mode = "single"
else:
→ mode = "parallel"LLM 返回结构化的工具调用,一个工具 → 单 agent,多个工具 → 并行,plan_execution 元工具 → 顺序。一次调用,三种策略。
第二步:不需要 LLM 的执行器
这是 orchestrator 真正省成本的地方。执行器是纯 Python——没有 LLM、没有不确定性、没有延迟冲击波。三种模式:
Single
result = REGISTRY[tool_name]["execute"]()Parallel
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {name: pool.submit(REGISTRY[name]["execute"]) for name in tool_names}
results = {name: f.result() for name, f in futures.items()}Sequential
for step in plan:
results[step["tool"]] = REGISTRY[step["tool"]]["execute"]()零 LLM 消耗,所以线上部署时换成 asyncio.gather 加 HTTP 调用就行。
路由之后,系统就和其他微服务编排没什么区别了。延迟可预测,调试直来直去,可观测性用标准工具就能搞定。"AI"被压到两层(路由和合成)里,中间全是确定性的执行,调试起来非常舒服。
第三步:润色答案的合成器
Agent 输出的是 JSON,用户要的是自然语言。所以需要再来一次 LLM 调用,把数据转成响应:
response = client.chat.completions.create(
model=deployment,
messages=[
{"role": "system", "content": "Summarize the agent results into a clear, helpful answer."},
{"role": "user", "content": f"User asked: {query}\nResults: {json.dumps(results)}"},
],
temperature=0.7,
)注意,路由用 0.0、合成用 0.7:路由要精确,合成要可读。不同的工作,参数自然不同。
三种查询,三种模式
完整管道就三个函数调用:
decision = route_query(client, deployment, query) # LLM 调用 1
results = execute(decision) # 无 LLM
answer = synthesize(client, deployment, query, results) # LLM 调用 2查询 1——Single:
查询 2——Parallel:
查询 3——Sequential:
同一个管道,三种执行策略,始终是两次 LLM 调用。
总结
Agentic loop 把 LLM 同时当作大脑和手——每步既决策又执行。而 Orchestrator 把两者拆开:
- LLM = 大脑 → 定计划(一次调用)
- 应用 = 手 → 执行计划(确定性)
- LLM = 嘴 → 解释结果(一次调用)
这套分离就是 orchestrator 能大规模扩展的原因。"大脑"(路由)可以缓存——相同查询在 temperature=0.0 下始终走相同路由。"手"(执行)就是 HTTP 调用。"嘴"(合成)是唯一的创造步骤。线上场景里,如果 API 消费者要原始 JSON,连合成那一步都能省——压到每个请求一次 LLM 调用。
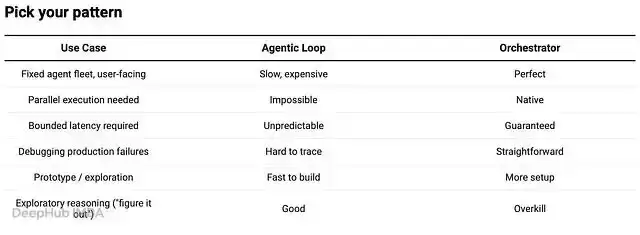
所以简单概括:Agentic loop 适合前期探索,而 Orchestrator 才是生产环境该用的东西。
-

- Loop无限循环1000关版
- 益智休闲 | 13MB
- 不花钱