
废片也能变大片,北大开源首个「美学照片重构」模型
你拍下一张照片,AI也许能帮你调亮、美颜、换个滤镜,却很难真正把它变成你心中想要的样子。
一张照片不好看,往往是因为一开始就没拍对:构图偏了、视角歪了、姿态僵了。现有图像美化工具可以调亮度、加美颜、套滤镜,却无法重新组织构图、修正拍摄角度、调整人物姿态,因此难以修正拍摄阶段留下的结构性缺陷。
针对这一挑战,北京大学彭宇新教授团队在美学理解领域开展了最新研究,定义了
美学照片重构
AesRecon
在此基础上,团队进一步提出美学照片重构模型
AesFormer
相关论文已被ICML 2026接收,并已开源。

从「表层修饰」到「画面重构」
拍照,是记录日常场景、情感与回忆的重要方式。但真正动人的瞬间往往稍纵即逝。要定格这样的画面,拍摄者需要在按下快门的瞬间,快速判断构图、视角、人物姿态等关键因素。
对专业摄影师而言,这种判断来自系统训练与长期实践;而对普通用户来说,由于缺乏摄影经验,拍出的照片常常存在构图偏移、视角失衡、姿态僵硬等问题,导致实际成片与心中期待的理想画面产生明显落差。
为了弥补这种落差,用户通常会使用
图像美化工具
(1)照片调色工具
(2)人像美容工具
然而,这些方法主要改善色彩、光影和人物外观,却难以修正拍摄阶段留下的「
结构性缺陷
换句话说,现有图像美化工具还缺少一种关键能力:在保持人物身份和场景内容基本一致的前提下,对照片的构图、视角、人物姿态等进行合理调整,从画面结构层面提升照片美感。研究人员将这一任务定义为
美学照片重构

图1. 美学照片重构任务示意图
然而,要实现美学照片重构并不容易,主要面临两个难点:
(1)高质量美学语料稀缺
(2)模型美学能力不足
针对上述问题,北京大学彭宇新教授团队提出了一套新的方案。团队首先提出了基于拍照教学视频的美学语料挖掘方法
VCMP
AesRecon
在此基础上,团队进一步提出美学照片重构模型
AesFormer
(1)美学规划:
(2)美学编辑:
实验结果表明,AesFormer在美学照片重构评测基准上取得了优于现有方法的结果。
研究人员将图像美化从以色彩、光影和人物外观调整为主的
表层修饰
画面重构
技术方案
现有图像资源中,能够呈现「同一人物、同一场景、由差到优」的成对人像照片样本十分稀缺,难以支撑模型学习真实的照片重构过程。互联网拍照教学视频为这一问题提供了可行的数据来源。
此类视频通常会完整记录同一人物、同一场景下的拍摄优化过程:摄影师与模特不断调整机位、构图与人物姿态,让画面从效果普通的原片,逐步优化为更具美学表现力的成片。

图2. 基于拍照教学视频的美学语料挖掘方法(VCMP)框架图
基于这一观察,研究人员提出了
基于拍照教学视频的美学语料挖掘方法VCMP
美学照片重构数据集与评测基准AesRecon
在此基础上,VCMP通过四个阶段完成语料挖掘:
(1)出彩成片定位
(2)普通原片匹配
(3)照片去干扰
(4)拍摄事件对齐
最终,AesRecon包含9071对严格对齐的「普通原片-出彩成片」人像照片样本。
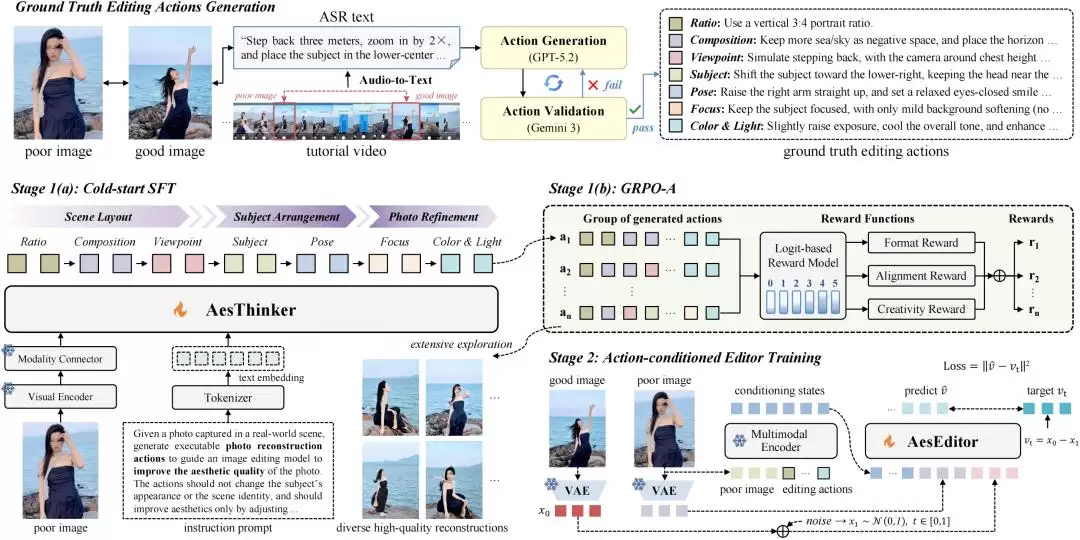
图3. 美学照片重构模型(AesFormer)框架图
为解决现有图像编辑模型美学能力不足的问题,研究人员提出
美学照片重构模型AesFormer
如图3所示,AesFormer采用「美学规划+美学编辑」的两阶段方法:
(1)美学规划
(2)美学编辑
阶段I:美学规划
针对AesRecon中的每组照片对,研究人员首先提炼摄影师与模特在拍摄过程中围绕构图、视角、姿态等因素进行的调整,形成从普通原片到出彩成片的美学优化方案。
在此基础上,对多模态大模型进行冷启动监督微调,将美学优化方案建模为符合摄影逻辑的有序决策序列,引导模型沿七个递进的摄影维度分析照片问题,使其具备基础的美学理解、问题诊断与方案规划能力。
训练样本统一表示为(p,q,a):其中p为普通原片,q为任务指令,a为美学优化方案。模型在给定p和q的条件下学习生成a,即最大化目标优化方案的条件对数似然,损失函数定义如下:
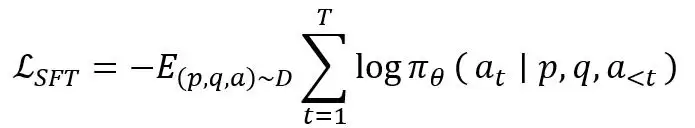
虽然监督微调为模型打下了基础,但仅依赖SFT容易让模型「死记硬背」。对于美学照片重构来说,这一点尤其关键:
同一张照片并没有唯一的「正确改法」
为此,研究人员进一步提出
美学引导的组相对策略优化
阶段II:美学编辑
研究人员
训练样本统一表示为(p,a,g):其中p为普通原片,a为美学优化方案,g为出彩成片。模型以p和a为输入,以g为监督目标进行训练。实验基于Qwen-Image-Edit-2511,训练得到美学编辑模型AesEditor。
推理时,AesFormer采用「美学规划+美学编辑」的两阶段串联流程:先由AesThinker生成美学优化方案,再由AesEditor结合输入照片与优化方案,生成最终的重构照片。
实验结果
表1展示了AesRecon评测基准上的美学照片重构结果。AesFormer在各项指标上均优于开源模型,并与Google闭源商业模型Nano Banana Pro表现相当,在多数指标上取得了更优结果,验证了其可靠的美学照片重构能力。
进一步地,研究人员探究了一个关键问题:现有图像编辑模型表现不佳,是否是因为缺少明确的编辑指令?换言之,
能否通过简单组合现有的Thinker与Editor来实现美学照片重构?
为此,研究人员使用Qwen3-VL-8B和GPT-4o生成优化方案,再由不同的编辑模型根据方案完成照片重构。结果显示,这类组合并未带来稳定提升,部分情况下甚至导致性能下降。这表明,美学照片重构无法通过简单的「生成指令+执行编辑」实现,主要原因在于:
(1)通用Thinker缺乏美学理解能力
(2)通用Editor缺乏美学执行能力
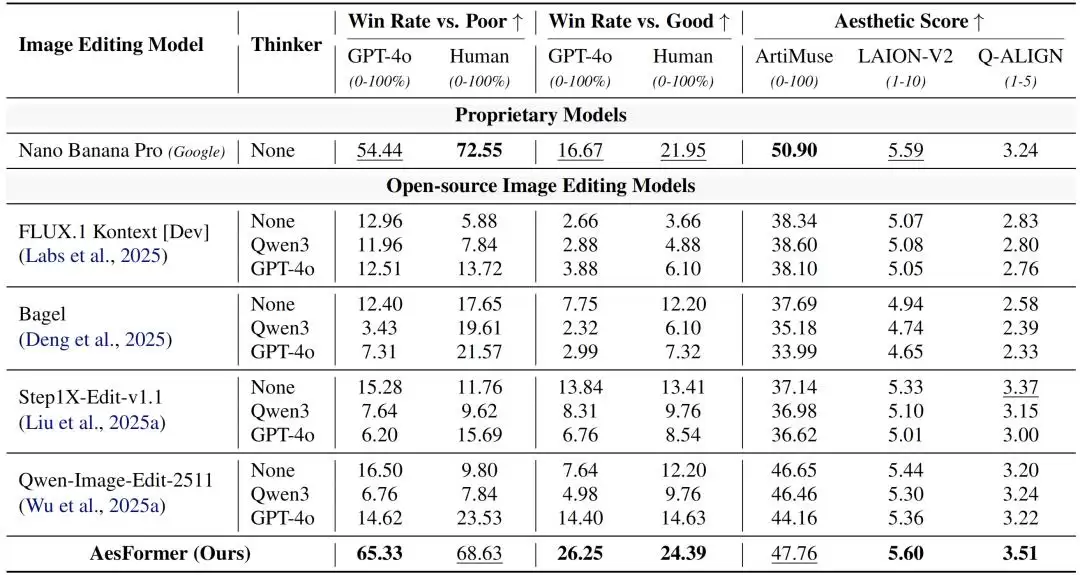
表1. 美学照片重构模型(AesFormer)在AesRecon评测基准上的美学照片重构结果
图4的案例展示表明,开源图像编辑模型通常难以完成美学照片重构所需的结构性编辑,因此无法有效修正拍摄阶段留下的构图、视角与姿态问题。相比之下,AesFormer通过将美学规划与图像编辑解耦,能够更稳定地通过画面重构提升照片美感。

图4. 美学照片重构模型(AesFormer)案例展示
项目价值
针对高质量美学语料稀缺、模型美学能力不足的问题,研究人员通过从互联网拍照教学视频中自动挖掘美学语料,构建了一个新的美学照片重构数据集与评测基准AesRecon,并提出美学照片重构模型AesFormer:首先,通过美学规划模型分析照片问题,并生成美学优化方案;其次,通过美学编辑模型将优化方案转化为像素级编辑,完成照片重构。
研究人员将图像美化从以色彩、光影和人物外观调整为主的表层修饰,升级到能够优化构图、视角与人物姿态的画面重构,为AI理解与生成高质量摄影作品提供了新的研究视角与技术路径。




