
Agent自进化新范式:孙立超团队提出OpenSkill,刷新多项基准SOTA
当前,自进化Agent的持续学习基本都靠成功轨迹、现成技能或者明确反馈。可在真实部署场景下,这些前提条件往往很难同时满足,结果就是Agent不断卡在原地,既没法积累经验,也没办法迭代自己的表现。
针对这个瓶颈,里海大学孙立超团队与合作者提出了一个新的框架——
OpenSkill
即使不依赖目标任务的监督信号,Agent也能自己拿到可执行、可迁移的技能

结果显示,
OpenSkill在多个基准测试上都达到了SOTA的自动化表现
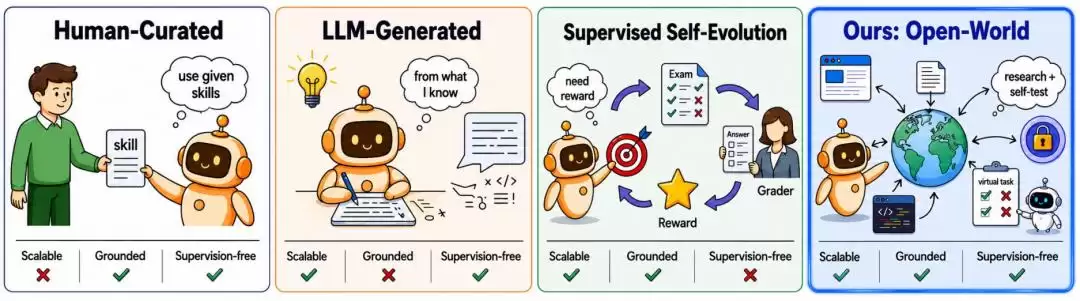
图|自进化Agent技能的范式。
OpenSkill 是怎么设计出来的?
OpenSkill 是怎么设计出来的?
一句话概括:OpenSkill是一个面向开放世界的Agent技能框架。它把任务指令、执行环境、基础模型、工具访问权限、开放世界资源这些因素作为输入,整个流程拆成三步:
开放世界知识获取
无泄漏技能进化
零样本目标评估
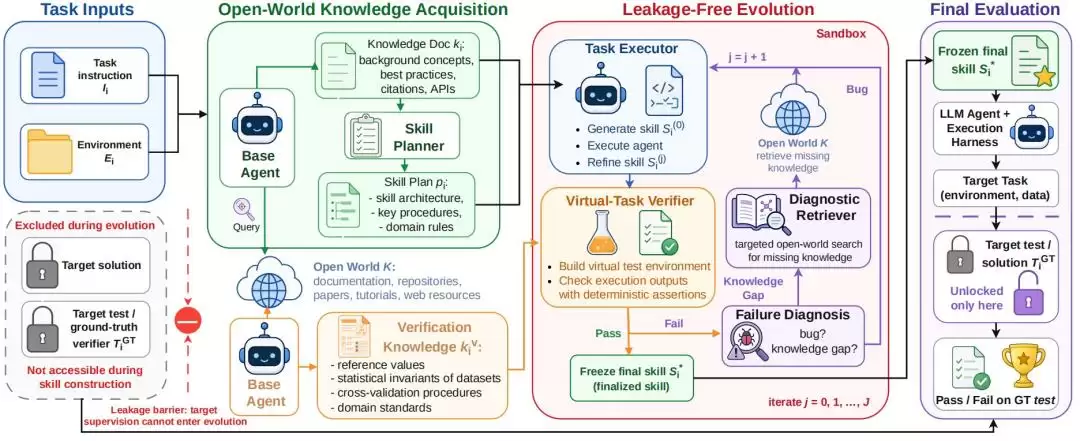
图|OpenSkill 框架概览。
开放世界知识获取:
无泄漏技能进化:
零样本目标评估:
实验结果怎么样?
实验结果怎么样?
为了验证OpenSkill到底行不行,团队从
基准测试表现
技能迁移
消融实验
1. 基准测试:OpenSkill总体表现领先
OpenSkill在三个基准测试、两个目标Agent上,都拿到了最佳自动化表现。在SkillsBench上,它把Opus 4.6和GPT 5.2的总体通过率直接抬到了43.6%和42.1%,比最强基线高出了8.9和8.8个百分点,离人类参考上限只差1到3个百分点。更有意思的是,在Opus 4.6上,11个领域里有8个都达到了最佳或并列最佳的效果。
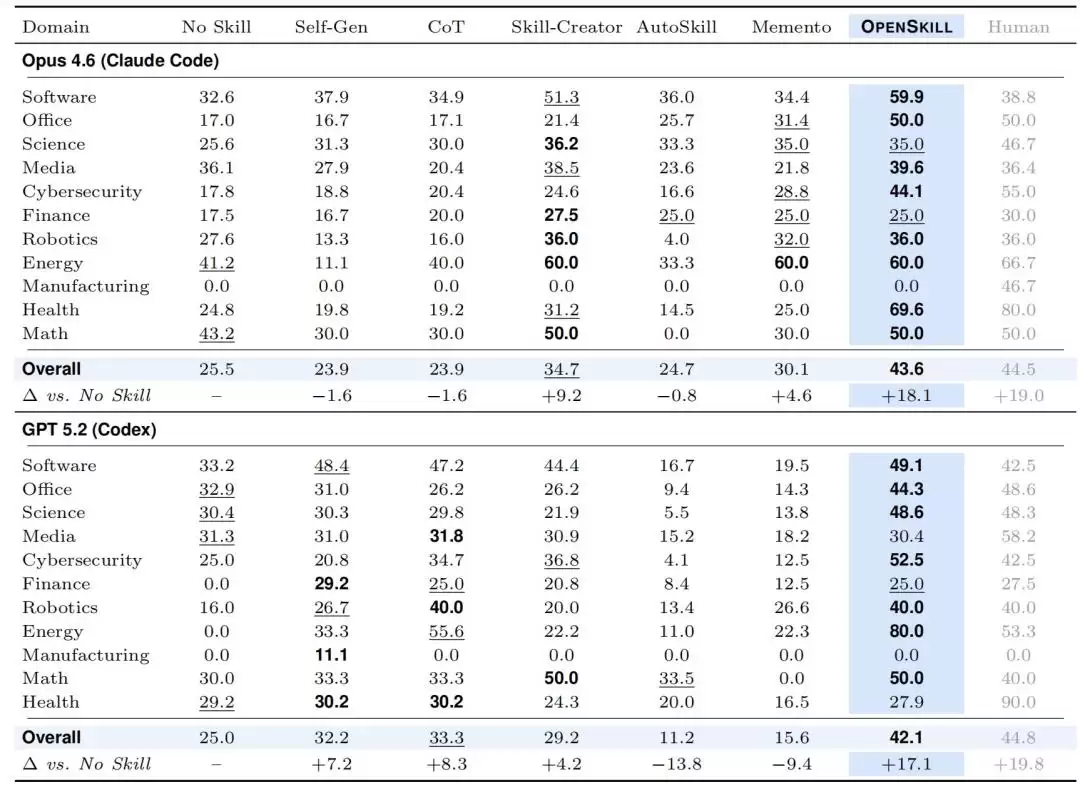
图|SkillsBench在11个领域的主要结果:展示了两个目标Agent在各领域上的平均奖励。
类似的优势也出现在另外两个基准上。在
SocialMaze
ScienceWorld
OpenSkill就是所有自动化方法里表现最好的
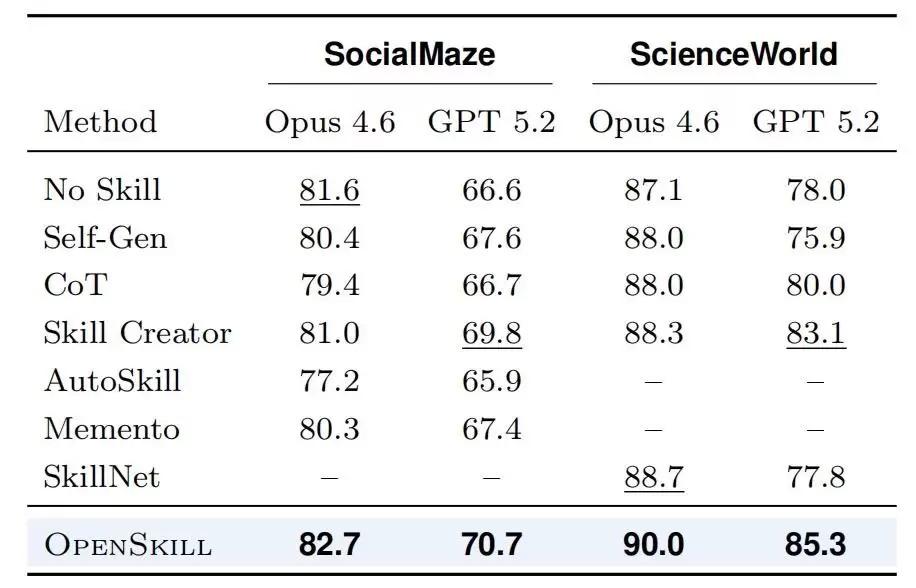
图|两个目标Agent在SocialMaze和ScienceWorld上的平均奖励。
2. 技能迁移:不用额外适配,就能迁移到更弱模型
在技能迁移这部分,团队把Opus 4.6生成的技能,直接移植到了Haiku 4.5、Qwen 3Coder、DeepSeek V3、Mistral Large 3这4个更弱的模型上,完全没做额外适配。结果很清楚:
这些技能在4个目标模型上都带来了非常明显的增益
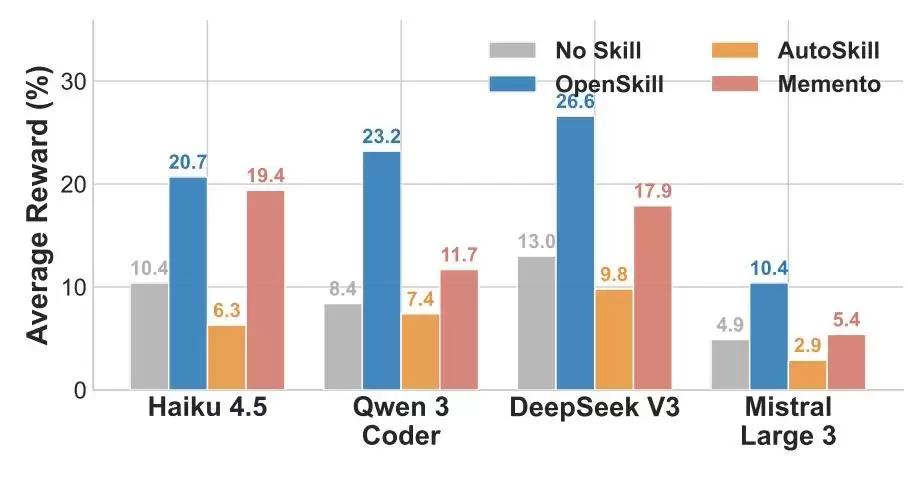
图|由Opus 4.6生成的技能迁移到其他模型后,在SkillsBench上获得的平均奖励。
3. 消融实验:三轮迭代效果最好
在SocialMaze上,OpenSkill在3轮迭代时达到了最高的82.7%,但如果继续增加到5轮和10轮,效果反而往下走。消融结果也指出,开放世界检索和虚拟验证器,每一块单拎出来都能提升表现,但合在一起效果才最好。团队进一步发现,
虚拟验证器跟真实评测结果之间的一致性很高
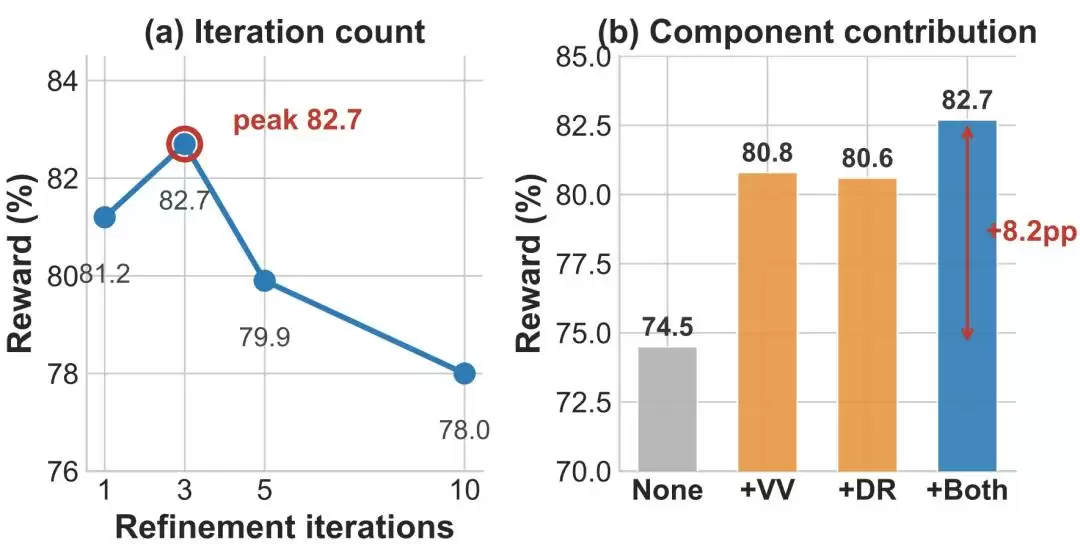
图|SocialMaze上的消融实验。
局限与未来方向
局限与未来方向
当然,团队的坦诚也值得关注。开放世界知识源本身就可能存在噪声、过时甚至相互矛盾的信息,而虚拟任务也很难完全复现真实任务的复杂程度。尤其在深层语义验证和反作弊元验证这些环节上,目前的覆盖还比较有限。
另一个不得不提的问题:
成本高、耗时长
展望未来,团队明确了三个大方向:提升知识源的可信度、增强虚拟任务对真实任务的覆盖能力、以及想办法降低整体成本与时延。毕竟,成本也是落地时绕不开的大山。
更多技术细节,可以参考原论文。




