
瓴羊副总裁王赛:做真正可商用的ChatBl,坚持智能准确性与数据安全性并重
在最近的一次行业分享中,瓴羊副总裁王赛抛出了一个相当笃定的判断:
数据分析依然是大数据领域最普遍、最有价值的场景,也是AI时代帮助企业找到成功路径的关键抓手。
随着技术迭代和应用场景的不断拓展,数据分析正从传统的报表输出,一步步进化成深度的业务洞察与决策支持。对于企业来说,除了一门心思搞商业模式创新、运营方法升级之外,能不能把自己沉淀下来的业务数据真正用起来,再反哺回业务一线,这才是支撑企业长期持续发展的根本。
谈到企业数据的建设路径,王赛给出了一个相当清晰的三层架构,值得反复琢磨:
- :先把数据存起来,确保有足够的计算能力兜底,这是一切的前提;
底层架构
- :数据存下来了,还得经过生产、加工、治理这一整套工序,把原始的、杂乱的数据,变成真正可用的数据资产;
数据治理与应用
- :有了好数据和好架构,最后一步就是提供友好的可视化工具和洞察分析能力,让数据分析真正落地。
分析与可视化
作为在大数据行业摸爬滚打了18年的老兵,王赛对这些年技术进步带来的变化感受极深。
“十几年前,金融、电信这些行业建数据仓库,用的软件几乎清一色是国外产品。但到了今天,我们的国产数据产品在行业里已经表现得相当出色,给客户提供了不少优质的落地方案。”这句话背后,是整个行业从跟跑到并跑,甚至在某些领域开始领跑的缩影。
今年6月,
Quick BI连续第五年入选Gartner®分析和商业智能平台魔力象限
智能准确性与数据安全性并重
过去一年,随着大模型在数据应用端的加速落地,市面上涌现了不少ChatBI类产品。但现实情况是,基于大模型的NL2SQL在一些关键领域的表现往往不尽如人意,甚至可以说相当尴尬。
问题出在哪?主要集中在几个方面:问数场景的覆盖度不够广(比如汇总、占比、趋势、排名、同环比等常见需求),对复杂计算的兼容性有限(像聚合二次计算、筛选聚合再筛选、动态环比这类操作),权限管理不够精细(比如行列级别的权限管控),可视分析能力薄弱(图表的呈现、筛选排序的二次交互),以及模糊语义识别能力不足(像一些习语、缩写的理解)。这么多短板叠加,导致企业在实际应用中很难真正“问”起来。
相比之下,Quick BI的智能问数(ChatBI)凭借多年积累的商业智能分析经验和对垂直领域的深度理解,在以上五大方面都表现出了明显的优势。尤其在复杂计算的兼容性和模糊语义识别这两个关键节点上,处理得相当出色,这才让企业有了“大胆问起来”的底气。
会上,王赛专门针对这些能力提升进行了现场演示,还原了真实的业务场景。比如在电商平台的销售场景中,当业务人员提问“销售额大于1万的省份有哪些”时,Quick BI的智能问数(ChatBI)需要调用二次复杂计算能力,才能给出准确答案。
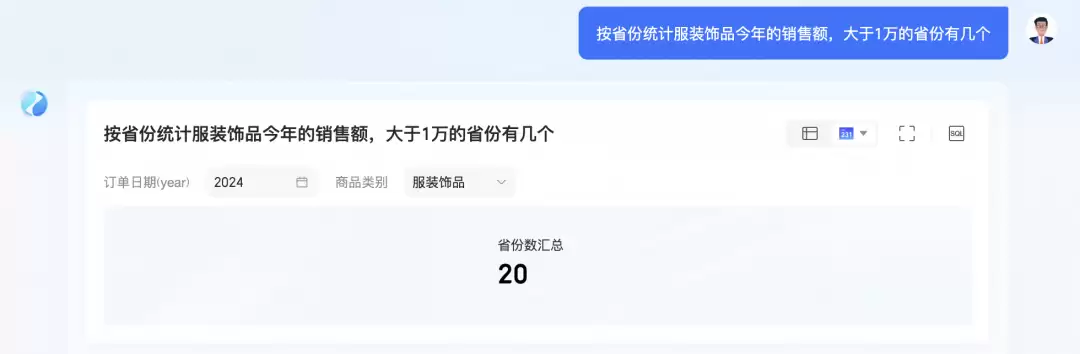
再比如模糊语义的识别,目前智能问数(ChatBI)已经能轻松应对。当用户提问“小郑”时,系统能精准定位到“郑强”的相关数据结果。
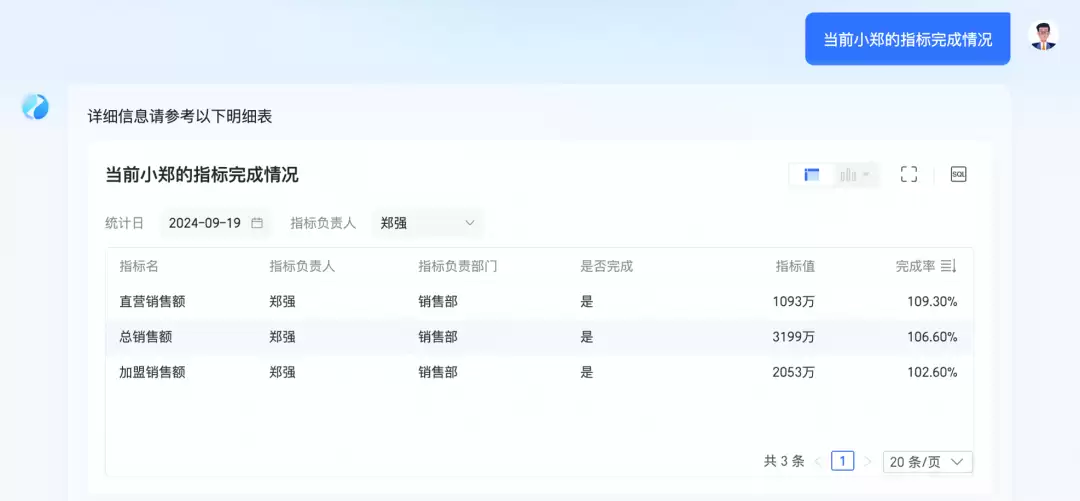
此外值得一提的,是Quick BI对精细化权限管控的考量。当前它支持问数权限的分层管理,可以灵活设定管理人员与使用者。这意味着企业内部可以根据不同业务组织开放相应权限,数据权限甚至能精细到表格的行、列级别,极大地保障了企业的数据安全管理。
能让企业「问」起来,才是真正的ChatBI
目前,Quick BI的智能问数(ChatBI)能力已经在多个行业的业务场景中落地开花。
在某大型乳业品牌的供应链场景中,Quick BI帮助企业在内部建立了一套智能问数体系。业务部门可以直接用自然语言提问,快速获取数据,还能高效定位问题原因。这套体系覆盖了自然语言问答、多维度灵活查询、多时间粒度指标表现分析,以及查询结果的可视化展现,真正把数据分析工具变成了一线业务员的日常利器。
在能源领域,Quick BI帮助某能源国央企实现了自然语言交互式的数据即时问答。系统支持多样化的提问方式,包括快捷提问、直接输入问题、基于问数结果的进一步筛选和图表切换,全面满足了业务日常使用需求。更值得一提的是,该企业的数字化部与市场营销部联合开展了针对某项关键流程指标的多维自助问答,进一步提升了数据的可用性和响应速度。这才是ChatBI该有的样子——不是摆着看,而是真正能用、好用。
