
前OpenAI CTO创业后首个「交互」大模型:原生、实时处理人机协作
从Siri到ChatGPT,我们与机器的对话似乎总隔着一层无形的屏障——一问一答,规规矩矩,却少了人与人之间那种流畅自然的互动感。问题出在哪?关键在于,目前绝大多数大模型仍固守于“轮次式交互”的框架。用户说完,模型再答;模型生成时,无法同步接收新的信息。所谓的“实时对话”,本质上还是靠外部工程框架,将语音识别、大模型、语音合成这几个模块拼接起来实现的同步假象。
不过,这个局面或许即将被打破。近日,由前OpenAI CTO Mira Murati创立的Thinking Machines Lab,发布了其首款交互模型(Interaction Models)的研究预览。这项研究旨在重新定义人机对话,其展示的全新交互能力,在智能性与响应速度上,据称已达到了当前最先进的水准。

研究团队的核心突破在于,让模型能够持续接收音频、视频和文本流,并同步进行回应、工具调用和后台推理。这听起来简单,实现起来却需要一套全新的系统架构。
面向实时协作的双模型系统
面向实时协作的双模型系统
为了实现真正的实时交互,Interaction Models采用了一套精巧的双模型设计:一个具备时间感知的“交互模型”负责前台实时互动,另一个“异步后台模型”则处理需要长时间推理或工具调用的任务。多模态架构与流式推理服务为这套系统提供了低延迟的保障。
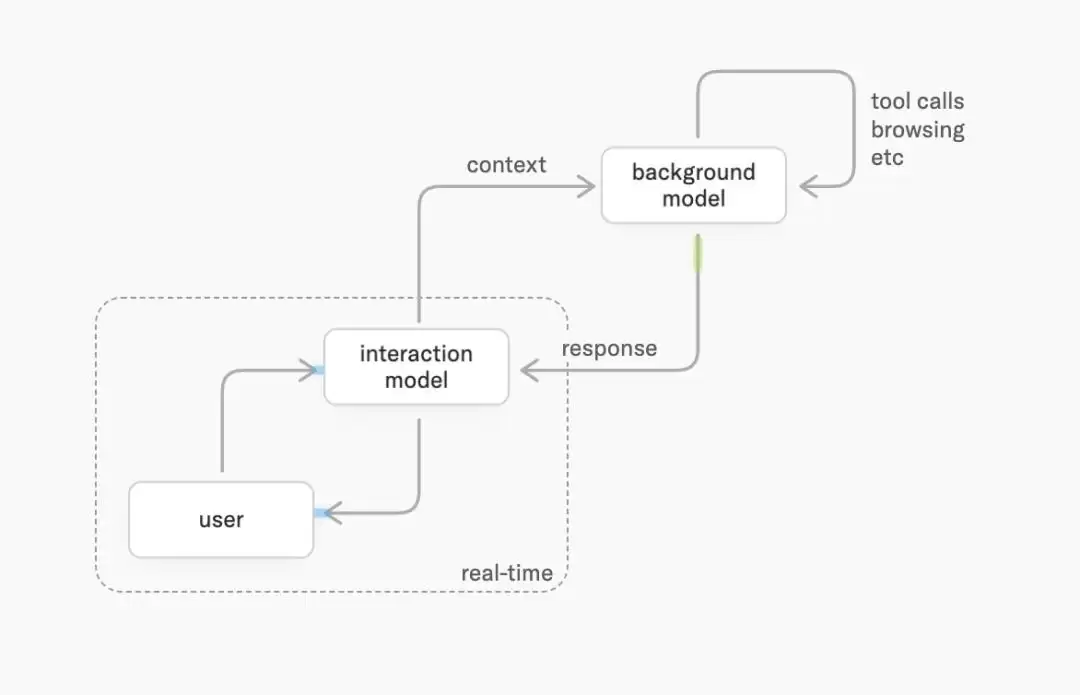
图|用户持续与交互模型互动,同时后台模型执行异步任务。两个系统共享上下文。
交互模型:200毫秒级实时对话管理
这套系统的灵魂在于引入了“时间对齐微轮次”的概念。它将连续的输入和输出切割成200毫秒的片段,让模型能够像人类一样,持续“听”和“看”,并同步“思考”与“回应”。
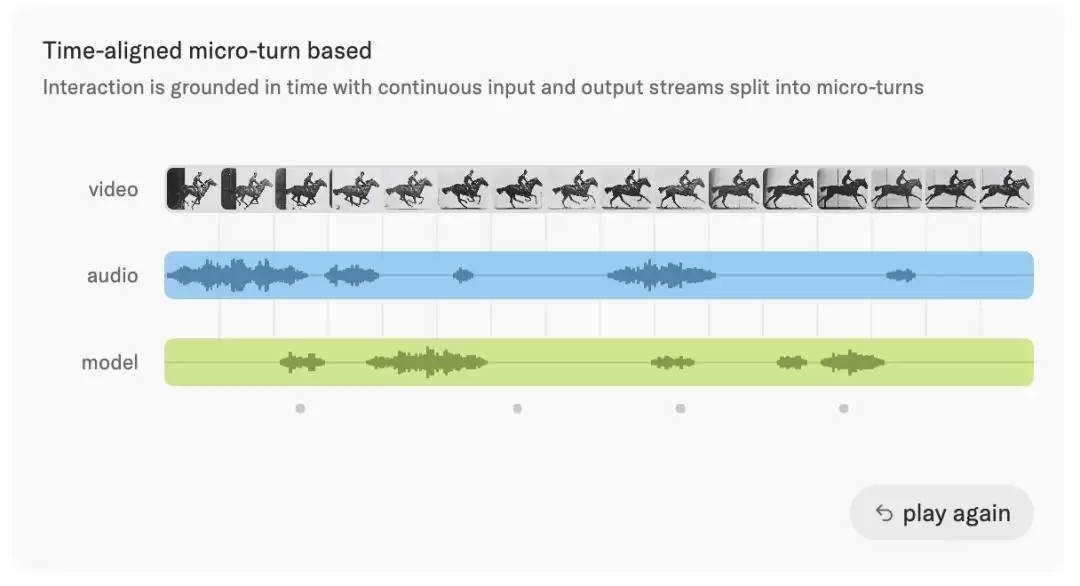
图|轮次式模型看到的是一条交替的token序列。具备时间感知能力的交互模型看到的是连续的微轮次流,因此沉默、重叠发言和打断仍会保留在模型上下文中。
这意味着,用户的每一次停顿、犹豫、自我修正,甚至视觉上的动作变化,都成为了模型判断下一步行动的宝贵线索。模型不再需要等待一个完整的指令句,就能判断此刻是该接话、等待还是提问。在官方演示中,当研究员Lilian Weng在讲故事时,模型能独立判断她是在思考还是在期待回应,无需任何额外的对话管理模块介入。
后台模型:把异步任务接入实时对话
当对话涉及需要查资料、复杂计算或长时间规划的任务时,交互模型便会将完整的上下文“移交”给后台模型。这个后台模型异步运行,生成结果后以流式方式返回,再由交互模型无缝融入对话。用户完全不必等待,可以继续说话,感觉就像在与一个“一心多用”的超级助手交谈。
底层服务:用早期融合与流式会话压低延迟
为了支撑200毫秒级的实时交互,研究团队在底层做了大量优化。他们采用了早期融合路线:音频以dMel频谱图形式输入,图像被切分成40×40的块进行编码,音频输出则通过专门的流式解码器生成。

图|单个200毫秒微轮次中的交互模型架构示意图。模型可以接收文本、音频或视频中的任意一种或多种输入,并预测文本和音频输出。
在推理侧,团队运用了“流式会话”技术,将连续片段追加到GPU内存的持久序列中,大幅减少了内存重新分配和元数据计算的开销。这些优化能力已被整合进SGLang上游,并通过内核优化等手段,共同支撑起低延迟的双向服务。
更低延迟,更强实时交互
更低延迟,更强实时交互
光有架构创新还不够,性能究竟如何?研究团队使用现有的交互基准、音频智能基准,并结合自建的实时交互任务,对TML-Interaction-Small模型(一个276B参数的MoE模型)进行了全面评估。
在常规交互基准FD-bench V1上,该模型的优势主要体现在响应速度。其简单话轮延迟仅为0.40秒,显著低于GPT-realtime-2.0 minimal的1.18秒等竞品。在更复杂的FD-bench V1.5(测试打断、附和等场景)中,其交互质量平均得分达到77.8,也高于几个实时模型对照。
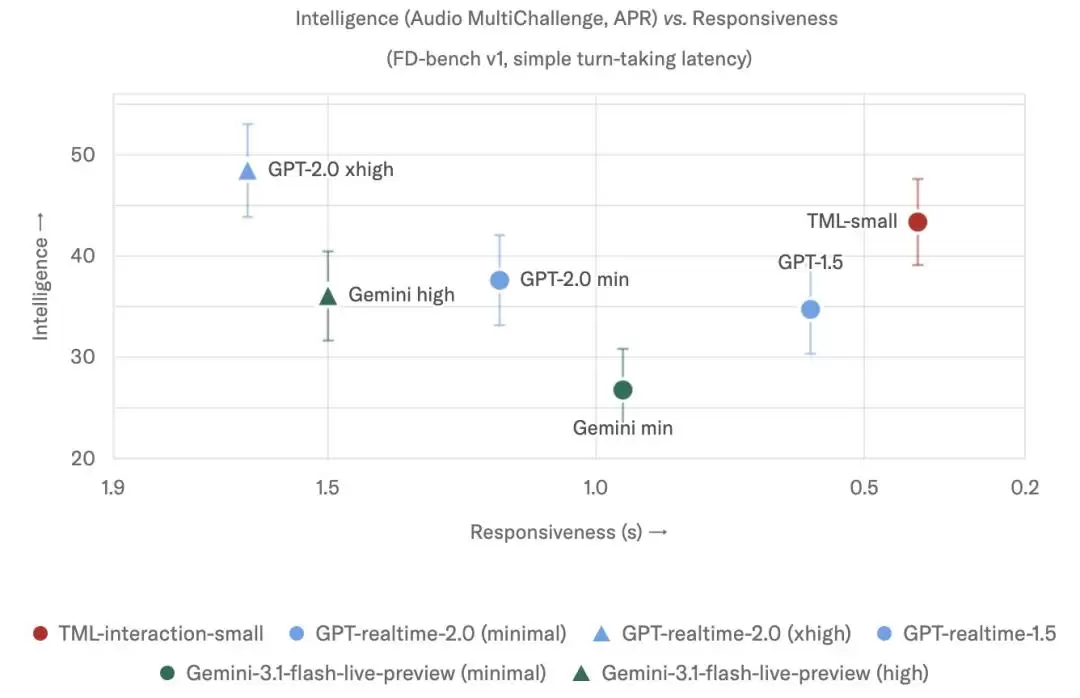
图|该模型在交互质量方面表现较高,同时在非thinking模型中具备较高智能水平。最佳响应速度以用户与模型交互之间的延迟衡量。
当然,对于实时模型,低延迟必须与高智能、强安全并行才有效。因此,团队还测试了其在工具调用、视频问答、安全拒答等多方面的能力。结果显示,其文本指令遵循准确率与顶级模型接近,同时在安全边界上也有可靠表现。
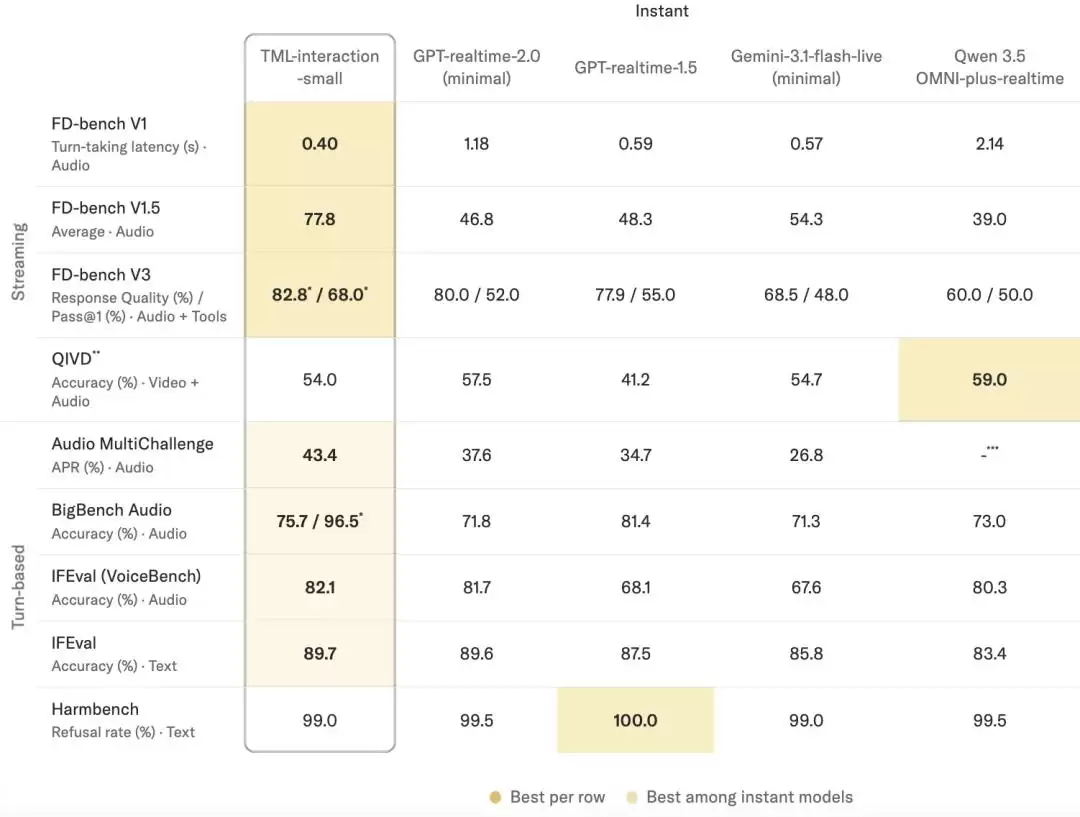
图|对于需要推理或工具调用的基准,结果为启用后台Agent后的表现。
更值得关注的是团队设计的几组内部实时任务测试。例如,TimeSpeak测试模型能否在用户指定的精确时间点做出回应;CueSpeak则测试模型能否识别用户语音中的微妙线索并适时接话。在这两项评估时间感知和语义触发能力的任务上,TML-Interaction-Small得分(64.7和81.7)远远将GPT-realtime-2.0 minimal(4.3和2.9)甩在身后。
在视觉主动响应方面,模型同样表现出色。在需要根据视频内容主动计数或回答问题的任务上,该模型得分显著高于基线和不回答的对照组,展现了其多模态实时理解与响应的潜力。
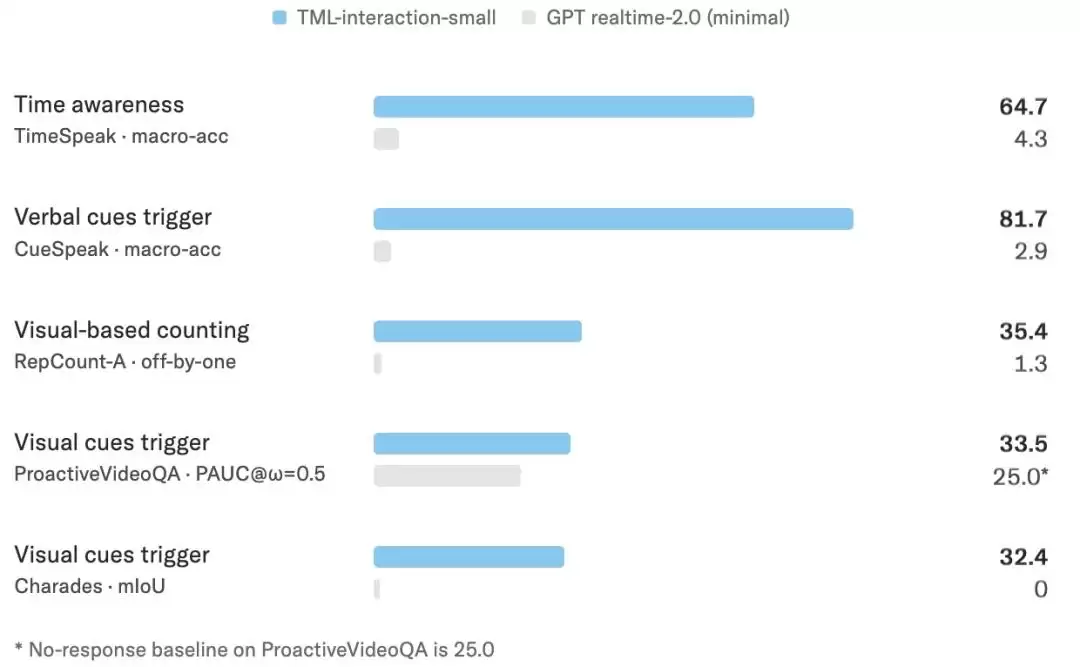
图|ProactiveVideoQA上的不回答基线为25.0。
不足与未来方向
不足与未来方向
尽管前景令人兴奋,但必须清醒认识到,Interaction Models目前仍处于研究预览阶段,要成为一个稳定可用的实时协作系统,还有几座大山需要翻越。
首先是长上下文管理的挑战。
其次是现实部署的约束。
第三是模型规模的限制。
第四是安全与信任的难题。
最后,后台智能体的协作机制仍处早期。
总而言之,Thinking Machines Lab的这项工作,为人机交互推开了一扇新的大门。它不再满足于模拟对话,而是开始构建一种能够感知时间、理解语境、并同步思考与行动的“数字协作者”。虽然前路漫漫,但方向已然清晰。




