
Text-to-SQL技术演进 - 阿里云OpenSearch-SQL在BIRD榜单夺冠方法剖析
一、引言
自然语言转SQL(Text-to-SQL),说白了就是让咱们用大白话就能查数据库——不用学那些复杂的语法,直接问“上个月销量最高的产品是啥”,系统自动给你生成SQL。最近阿里云OpenSearch搞了一套“一致性对齐”技术,在BIRD数据集上直接拿了个第一,把IBM、Google、字节跳动、斯坦福这些大厂和名校都甩在了后面。这篇文章就聊聊Text-to-SQL这门技术是怎么一步步演进的,再扒一扒OpenSearch-SQL到底用了什么招数。
(信息来源:2024年8月29日)
二、背景
Text-to-SQL其实不算新东西,学术界研究了十多年。核心目标很直接:让用户随口一问,系统就能精准地把SQL写出来。过去因为语法复杂、逻辑绕,这活儿基本停留在实验室里。但大模型一来,工业级方案就开始冒尖了。
这技术最大的难点在于:你得准确理解用户想问什么,识别出问题里的实体和关系,然后映射到数据库的表、列和对应的SQL操作。模型不仅得懂自然语言,还得吃透SQL语法,面对千奇百怪的数据库结构时还得有泛化能力——这要求不低。
为了推动这事儿,陆续出了不少公开数据集和基准测试,比如WikiSQL、Spider、BIRD。这些标准帮大家训练模型、比对比对效果,也让Text-to-SQL系统从最开始的简单单表查询,一步步进化到能处理多表关联、比较运算、聚合函数这些复杂查询。应用场景一下子就宽了。
下面是个极简的Text-to-SQL例子:
三、技术演进
3.1 传统方法
3.1.1 基于Sketch
这类方法的核心思路是把SQL拆成固定的“架子”(Sketch),比如SELECT部分、AGG函数、WHERE条件这些模块,然后让模型往这些槽位里填具体内容。最早的代表是Seq2SQL,它直接用神经网络分类来预测每个槽位该填什么。这种拆法确实降低了任务复杂度,但问题也很明显——架子的表达能力有限,处理简单查询(比如WikiSQL)还行,一遇到Spider那种复杂语法和嵌套结构,就露怯了。
后来Coarse2Fine、RYANSQL这些方法做了改进:不光是填槽,还让模型先生成一个自然语言查询的“架构”,再从中生成SQL。这样一来,面对复杂的语法和多变的数据库,扩展性好了一些。
3.1.2 基于中间语言
还有些研究者发现:直接生成SQL太难,不如先生成一种更接近自然语言的中间表示,然后再转成SQL。比如IRNet专门为SemQL设计了一套中间语言,模型先写出SemQL,再翻译成SQL,难度一下子就降下来了。
3.1.3 小结
传统方法还包括用预训练模型替换编码器、用图结构分析语法树、重点过滤数据库信息等。总体来看,基于Sketch或中间语言的做法,本质上是“模型能力不够,人工设计来凑”。最终效果很大程度上依赖于手工设定的框架到底能表达多复杂的SQL,这也限制了这些方法的迁移能力——换一个领域就得重新调架构。
3.2 LLM方法
大模型能力上来以后,局面就不一样了。LLM驱动的方案在迁移性和推理能力上明显优于传统方法,Text-to-SQL正式进入新阶段。更复杂的SQL任务也能有效处理,不用再死磕那些人为设计的框架。数据集也从Spider过渡到了BIRD,挑战难度直线上升。
举个例子:传统方法里的经典模型T5-Base在Spider上能到71.1%的准确率,但到了BIRD上直接掉到7.06%。而GPT-4在Spider上到了83.9%,在BIRD上还有54.89%。这差距说明大模型在迁移性和应对复杂问题上确实有底子。
3.2.1 标准框架
虽然LLM驱动的Text-to-SQL还没形成一套铁打的框架,但从目前效果好的方案来看,大致可以归纳成四个步骤:
- 把数据库必需的信息收拾好。包括清洗DDL、处理存储值、维护向量数据库、准备Few-shot示例。
准备阶段:
- 根据具体问题,筛选出关键信息帮模型降低难度。数据库太大、任务太复杂时,先过滤出相关的字段和值。
提取阶段:
- 用好所有准备信息,让大模型生成SQL。这里可以用COT、任务分解、Few-shot等手段来引导模型。
生成阶段:
- 根据执行结果或规则,对生成的SQL进行自动修正。比如把跑不动的SQL改好,或者用大模型做二次选择。
优化阶段:
3.2.2 代表方法
LLM驱动的方法里,有几个代表性选手值得一说:
- 用链式推理(COT)生成SQL,逻辑链条更清晰。
DIN-SQL:
- 用SFT微调模型专门干这活,展示了预训练模型在特定任务上的适应力。
ExSL + Granite-34B-Code:
- 靠任务分解降低复杂度,多步骤问题处理得更好。
MAC-SQL:
- 搞了动态Few-shot策略,不同场景下适应性更强。
DAIL-SQL:
- 用更精细的抽取模式筛选关键字段,处理复杂SQL时表现出色。
CHESS:
这些方法在实际中都拿到了不错的效果,大模型在Text-to-SQL上的潜力可见一斑。
四、OpenSearch-SQL方法剖析
在梳理完LLM驱动的Text-to-SQL方法后,我们提出了OpenSearch-SQL,目标是给这套流程定个标准模板,同时解决当前方案里一些共性问题。OpenSearch-SQL有两个版本,都遵循下面这个多Agent框架:
4.1 OpenSearch-SQL, v1
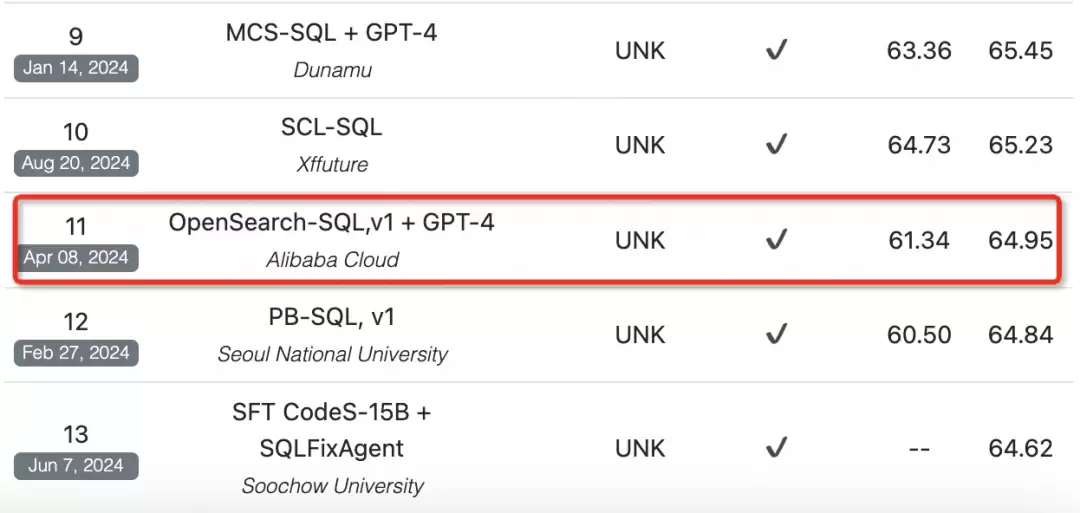
在v1版本中,我们第一次把上面那个框架给定了下来。目前v1在BIRD榜单上排第十一(刚提交时是第二名)。
框架里三个Agent:
- 准备好Few-shot示例、数据库值的向量库以及结构信息。
预处理Agent:
- 用动态Few-shot驱动LLM生成SQL。
生成Agent:
- 根据执行结果纠错修正,输出最终SQL。
优化Agent:
v1效果不错,但深入分析后发现,多Agent协作时,生成阶段的任务复杂度和指令遵循失败是两个主要瓶颈。具体来说:
- 从表、列、值这些组件直接跳转到完整SQL,思考过程太复杂,模型容易掉链子。
生成阶段任务难度过高:
- 比如提取字段时内容不完整或不一致;生成阶段没用好提取的信息;生成的SQL风格跟数据库不匹配;甚至提示里明说了需求,LLM还是当耳旁风。
指令遵循失败:
4.2 OpenSearch-SQL, v2
针对v1的问题,v2一开始就定了两个核心方向:
- 如何降低SQL生成的难度 →
渐进式生成
- 如何提高LLM指令遵循的成功率 →
一致性对齐
4.2.1 渐进式生成
降低难度,我们想了个新法子:一步一步地生成SQL的各个部分——SELECT、WHERE、GROUP BY……用一种COT的思路,先写分析,再确定列,再找值,最后拼SQL。举个例子:
What is the phone number of the school that has the highest a verage score in Math? #reason: The question want to know the phone number of the school, so the SQL SELECT schools.Phone and the condition is the school that has the highest a verage score in Math. #columns: schools.Phone, schools.CDSCode, satscores.A vgScrMath #values: highest a verage score in Math refers to ORDER BY satscores.A vgScrMath DESC LIMIT 1 #SELECT: phone number of the school refers to schools.Phone #SQL-like: SELECT schools.Phone FROM schools ORDER BY satscores.A vgScrMath DESC LIMIT 1 #SQL: SELECT T1.Phone FROM schools AS T1 INNER JOIN satscores AS T2 ON T1.CDSCode = T2.cds ORDER BY T2.A vgScrMath DESC LIMIT 1
这么做的优势很明显:
- 环节之间gap小,哪个步骤出了问题一目了然。
- 可以先忽略语法上不重要的信息(比如JOIN),聚焦核心逻辑。
- COT一次性完成,避免了多Agent协作带来的不一致性。
4.2.2 一致性对齐
指令遵循的问题,我们先看了看经典的提升方法:Post-training(比如SFT、RLHF、DPO)。这些方法虽然可能导致通用能力下降,但对子任务来说,能快速对齐风格。不过挑战也不少:
- 数据准备和不确定性:对齐子任务需要大量数据,训练结果还不好控。常见做法是只对生成SQL的步骤做SFT,其他部分靠GPT-4这样的基座模型,这样数据需求小,但潜力没完全发挥。
- 通用能力损失:有些小模型SFT后简单问题表现好了,复杂问题反而变差。这说明光盯着特定任务训练可能会损害模型的适应能力。
所以关键是怎么在Agent层面保证大模型的指令遵循效果,而不是一股脑去微调。我们做了一系列实验,发现两个现象:
- 复杂任务拆成简单子任务后,子任务的指令遵循程度高很多。
难度相关性:
- 模型能答对的SQL,仍然有概率出错——概率和问题难度正相关。实验里,相同prompt两次生成的badcase大约有10%的差集。
生成波动性:
基于这两个发现,OpenSearch-SQL里用了
Double Check + Vote
- 把子任务拆得更小,降低LLM解决难度,同时方便检查指令遵循质量,不行的就重新生成。分解后子任务简单到可以直接用规则检查对齐,不用再靠Agent指令。
任务分解:
- 根据执行结果分类纠错——不同错误类型用不同的prompt来修正。
SQL纠错:
- 用Self-consistency和投票机制,选出一致性最高的SQL作为答案;如果多个一样,挑执行时间最短的那个。准确率和效率都提高了。
Vote:
4.3 展望
一致性对齐还有不少优化空间。如果把模型输出做得更原子化,Text-to-SQL的上限还能再拔一截。原子化的Agent任务让大模型可以快速搭各种任务链路,而且能热插拔——灵活接入不同任务。这种机制既提高了模型的适应性,也方便开发者快速实现特定功能,整体效率会更高。
五、快速体验OpenSearch-SQL
了解了OpenSearch-SQL的具体方法和性能表现之后,企业和开发者可以快速上手体验一下它的实际效果。目前OpenSearch-SQL已经正式上线,用户可以在OpenSearch搜索开发平台中直接感受它的表现。
