
HyperEyes – 小红书联合剑桥推出的并行多模态搜索智能体
多模态搜索领域,最近有个新玩家引起了不小的关注。小红书和剑桥大学联手,推出了一个名为HyperEyes的并行多模态搜索智能体。这名字听起来就挺“犀利”的,它的核心,在于做了一件碘伏性的事:把过去“先定位、再搜索”的两步走流程,彻底揉成了一个动作。
简单来说,传统方法就像让你在一张合影里找人,你得先一个个把人脸框出来,再挨个去数据库里比对。而HyperEyes的思路是,我一眼看过去,就能同时把所有人的信息都给找出来。它首创了一种叫“UGS”(统一有依据搜索)的范式,把视觉定位和检索这两个步骤融合成了一个“原子动作”。这意味着,它可以在单轮交互内,并发地定位并搜索图片中的多个实体。
为了实现这种高效率,团队祭出了一个“双粒度效率感知强化学习”框架。效果如何?数据说话:其30B参数版本在六个主流基准测试中,准确率比同规模最强的开源模型高出9.9%,而工具调用轮次却减少了惊人的5.3倍。这基本上是在准确率和效率之间,找到了一个相当漂亮的帕累托最优点。
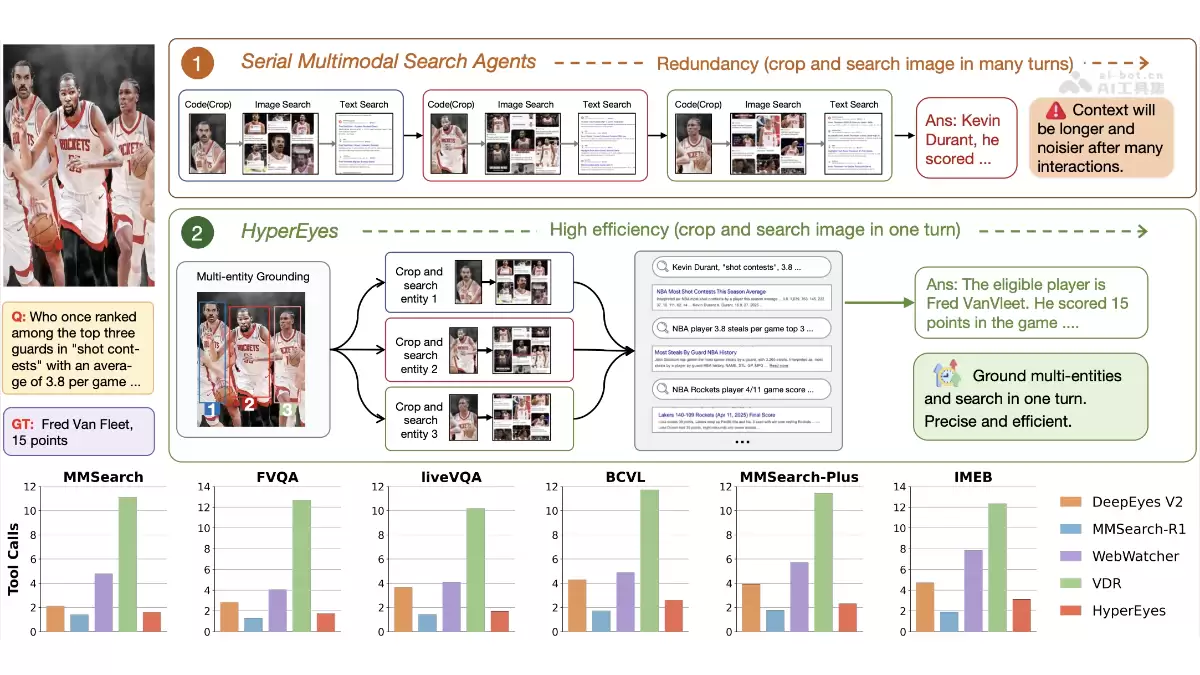
HyperEyes的主要功能
这个智能体到底能干什么?我们拆开来看:
- :这是它的看家本领。面对一张包含多个目标的图片,它不再需要像老式流水线那样,先裁剪再一个个串行搜索,而是可以单轮并发搞定所有。
并行多模态搜索
- :技术实现上的关键。它将视觉定位的“框”直接作为参数,嵌入到检索动作中。一次函数调用,就能携带多个目标框的信息出去搜索。
统一有依据搜索
- :为了训练出这种高效能力,团队设计了一套数据合成方法。通过在递增的轮次预算下提纯高效轨迹,构建了多达3万条、零冗余的并行种子数据。
渐进式拒绝采样
- :训练的核心机制。包含两部分:TRACE负责动态收紧轨迹级的效率标尺;OPD则在失败轨迹上,注入更精细的Token级纠正信号。
双粒度效率感知RL
- :为了公平衡量这类任务,项目还配套发布了一个包含300个实例的多实体视觉评测集,以及一个CAS评分体系,用来联合量化准确率和搜索效率。
IMEB基准评估
- :它并非单打独斗,而是集成了图像搜索和文本搜索工具,支持同时获取视觉和文字两种证据。
多工具协同
HyperEyes的技术原理
光看功能可能觉得有点“黑箱”,我们稍微深入一下,看看它背后的技术逻辑是如何支撑起这些能力的:
- :这是根本性的改变。它将视觉定位从独立的前置步骤,转变为检索动作的内嵌参数,从物理层面打通了单轮多目标并发的通路。
UGS动作空间重构
- :巧妇难为无米之炊。团队通过拼接图片合成多实体查询场景,并基于知识图谱随机游走构造复杂的多约束问题,同时剔除那些有“捷径”可走的简单样本。
并行数据合成流水线
- :训练中的效率指挥棒。它用当前已知的最优轨迹作为动态标尺,只有模型表现得比这个标尺更高效时,才会给予奖励,而且这个标尺每轮都会自动收紧。
TRACE动态参考奖励
- :一种精准的纠错机制。当轨迹最终答错时,会启动一个更大的235B教师模型,为这段失败轨迹提供密集的、Token级别的监督信号,目的是保护模型已经学会的“高效并发”本能。
OPD非对称策略蒸馏
- :训练时,通过GRPO方法,将轨迹级的效率奖励和Token级的蒸馏损失结合起来,同步优化策略网络的准确率和效率。
联合优化目标
- :最终的衡量标准。采用一个特定的公式(Acc²×100/(N_tok+2N_tool+1)),将准确率、Token消耗和工具调用轮次统一到一个效率指标下,非常直观。
CAS成本感知评分
如何使用HyperEyes
如果你对这项技术感兴趣,想自己上手试试,大致可以遵循以下路径:
- :代码和模型已在GitHub上开源。
获取开源资源
- :你需要下载并部署Qwen3-VL-30B或更大的235B版本作为视觉语言模型的主干。当然,前提是你的GPU显存足够支撑推理。
准备基础模型
- :智能体需要调用外部工具。你需要接入图像搜索和文本搜索的API(例如Bing Image Search或Google Custom Search),作为它执行并行搜索的“手和脚”。
配置外部检索工具
- :使用时就简单了。上传一张包含多个实体的复杂图片,输入你的自然语言问题。接下来,HyperEyes会自动执行UGS,单轮并发定位并检索所有目标。
输入多实体查询
- :模型会返回结构化的结果,包括最终答案,以及为每个实体找到的视觉证据和文本证据。
查看并行搜索结果
- :你可以使用项目提供的CAS指标,来量化评估整个过程的综合效率,看看它到底省了多少事。
评估搜索效率
HyperEyes的核心优势
说了这么多,它到底强在哪里?与现有方案相比,优势是全方位且显著的:
- :其30B版本平均工具调用轮次仅需2.2次,这相当于同规模最强开源模型效率的5倍以上(提升5.3倍)。
效率飞跃
- :在六大基准上,准确率领先最强开源对手9.9%。其235B版本更是以仅1.1%的差距,逼近了谷歌的Gemini-3.1-Pro。
准确率领先
- :并行策略有个附带好处,就是能规避过度检索产生的“幻觉”。在真假证据混合的测试中,其准确率提升了3.7%到5.8%。
抗噪声鲁棒
- :UGS范式彻底消除了对串行裁剪的依赖。这意味着,前置步骤的定位偏差,不会再像多米诺骨&牌一样污染后续所有的搜索结果。
消除错误级联
- :在准确率-效率的二维权衡曲线上,它实现了全面占优。其CAS评分达到了次优开源模型的7.6倍。
帕累托最优
- :它的高效不是某个单点优化,而是从动作空间设计、数据合成到强化学习训练的全栈底层重构,系统性地解决了“串行困局”。
全栈效率重塑
HyperEyes的同类竞品对比
空口无凭,我们把它和市场上其他知名的视觉搜索智能体放在一起对比,差距一目了然:
| 对比维度 | HyperEyes-30B | DeepEyes-V2 | VDR |
|---|---|---|---|
| 开发团队 | 小红书/剑桥大学 | 小红书 | 未公开 |
| 搜索范式 | 并行并发(UGS) | 串行裁剪-搜索 | 串行深度搜索 |
| 平均工具轮次 | 2.2 | 3.6 | 11.6 |
| 6基准平均准确率 | 64.0% | 39.1% | 54.1% |
| IMEB准确率 | 46.7% | 18.0% | 21.2% |
| CAS效率评分 | 0.910 | 0.119 | 0.014 |
| 核心机制 | TRACE+OPD双粒度RL | 工具奖励激励 | 多轮深度推理 |
| 错误级联风险 | 免疫(原子动作) | 高风险 | 中等风险 |
HyperEyes的应用场景
这样一种能“一眼多看”的智能体,能在哪些地方大显身手?想象空间其实很大:
- :分析一张历史合影或团体照,并发检索其中多位人物的身份、职业及相关历史事件信息。
多人物视觉推理
- :面对一张摆满商品的复杂场景图(如货架、橱窗),快速并发搜索所有商品的实时价格、品牌详情和用户评价。
电商商品比对
- :回答诸如“图片中这座建筑、那幅画和这个雕塑之间有什么历史关联?”这类涉及多实体关系的复杂查询。
跨模态知识问答
- :对一张包含多人物、多场景的新闻图片,并发检索验证图中各元素的真实性、时间地点及背景信息。
新闻事实核查
- :处理论文中复杂的截图,其中可能包含多个图表、公式和引用标记,并行定位并检索其对应内容。
学术图表解析
- :快速审核用户上传的复杂图片,对其中可能存在的多个违规实体(如违禁品、不当标识)进行并发搜索与判断。
社交媒体审核
总的来说,HyperEyes的出现,不仅仅是一个模型性能的提升,更代表了一种解决复杂视觉搜索问题的新范式。它将“并行”思想贯穿到底,从底层动作设计到上层训练评估,为我们展示了多模态智能体在效率和精度上实现双重突破的一种可能路径。对于需要处理海量、复杂视觉信息的应用来说,这类技术无疑值得密切关注。




