
以下是一些与嵌入(Embedding)相关的资源:
在大型语言模型的应用中,有三个关键技术绕不开:提示工程、嵌入和微调。其中,嵌入尤其关键——它直接决定了模型能否真正“读懂”文本。无论是搜索引擎、私人知识问答系统,还是内容推荐,背后都有它的身影。
嵌入(Embedding)的基本概念
嵌入到底是什么?按照OpenAI官方文档的定义:“嵌入是将概念转化为数字序列的数值表示,使得计算机能容易理解这些概念之间的关系。”
简而言之,嵌入把“含义”这个抽象概念,变成了计算机能处理的数字序列。
每一个嵌入都是一个浮点数向量,代表一段文本的语义信息。在向量空间中,两个嵌入之间的距离,直接反映了两段文本在含义上的相似度。举例来说,如果两段文字意思相近,它们的向量表示也会彼此靠近。这种向量化的表示,能精准捕捉文本之间那些微妙的特征差异。
所以,嵌入的核心价值在于:它帮助计算机理解人类信息所表达的“含义”。无论是文本、图像还是视频,嵌入都能提取出关键特征之间的“相关性”,并在搜索、推荐、分类和聚类等任务中发挥重要作用。
嵌入(Embedding)是如何工作的?
来看三个句子示例:
- “猫追逐老鼠。”
- “小猫捕猎啮齿动物。”
- “我喜欢火腿三明治。”
如果让人来判断,前两句意思几乎相同,第三句则毫无关联。但有趣的是,只看原始文本,第一句和第二句只共享了“The”这一个词。那么,计算机是怎么识破这种“文字伪装”,判断出前两句相关、第三句不相关的呢?
关键就在嵌入:它把离散的单词和符号,压缩成了连续的数值向量。如果把这些短语在坐标图上画出来,结果会是这样——

通过嵌入技术,文本被投射到多维向量空间。计算机能清楚地“看到”:句子1和2因为语义相似,在空间中彼此靠近;而句子3则因为无关,被远远甩开。如果再引入第四句“Sally 吃瑞士奶酪”,它的位置可能会落在句子3(奶酪可以放三明治里)和句子1(老鼠喜欢瑞士奶酪)之间——你看,这个空间甚至能反映出“奶酪”这个概念的多种关联。
当然,这个例子只用了两个维度(X轴和Y轴)。实际嵌入模型要复杂得多。比如OpenAI的模型“text-embedding-ada-002”,输出的向量多达1536个维度。正是这种高维空间的刻画能力,让计算机能分辨出文本中极其微妙的语义差异。在三维空间中,不同主题的文本(动物、运动员、电影、车辆、村庄)会自然地形成聚类。
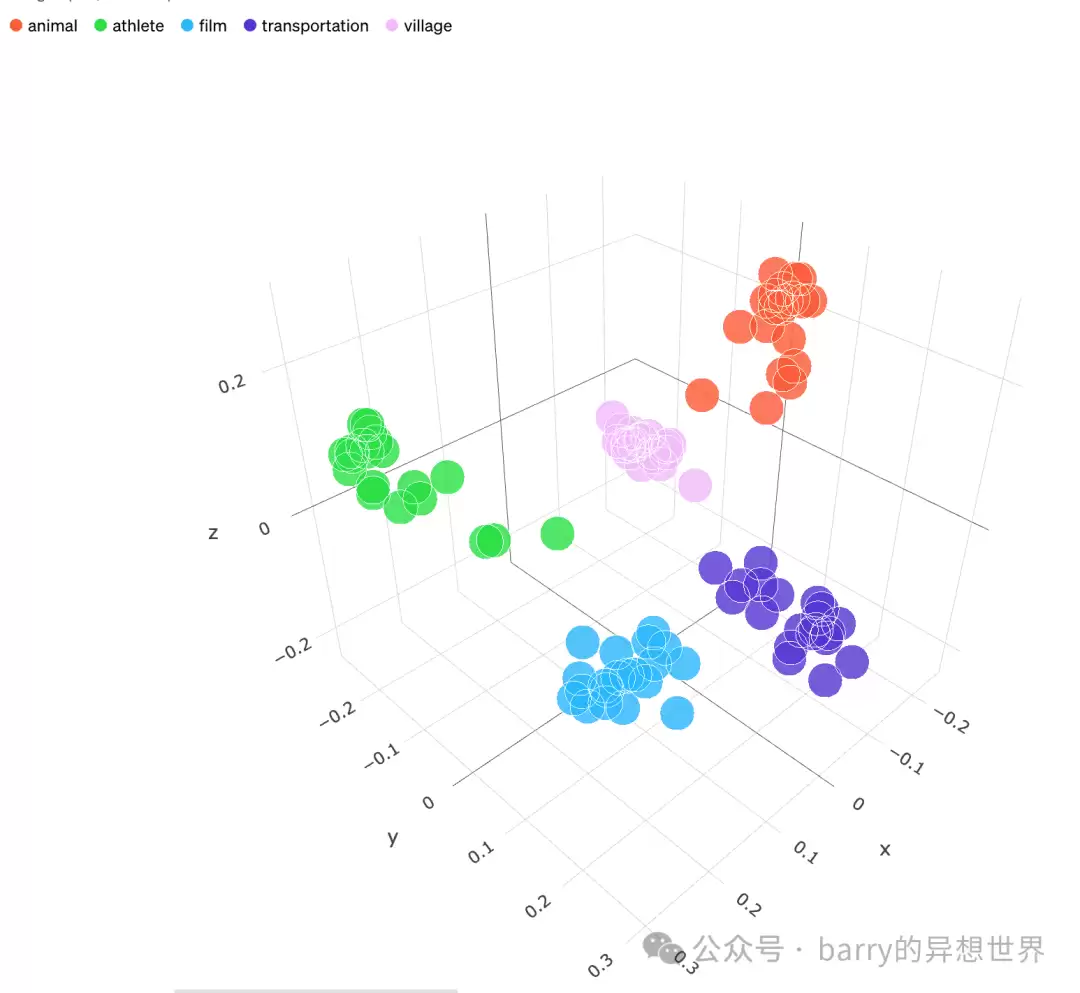
嵌入式的优势是什么?
ChatGPT虽然擅长回答问题,但它有一个明显的短板:它的知识范围仅限于训练时看到的数据。一旦涉及训练数据之外的特定领域知识(比如医学、法律、金融),或者组织内部的非公开资料,GPT的表现就会大打折扣。
要让GPT学习新知识,主要有两种方式:
- ——在额外的训练集上对模型进行微调。
模型权重(微调)
- ——直接把新知识作为提示的一部分输入模型。
模型输入(Few-Shot提示)
微调听起来更“高级”,因为它让模型从数据中深度学习。但它在事实回忆方面其实并不可靠。我们不妨来打个比方:如果把大型模型想象成一个参加考试的学生,那么模型权重就像他的长期记忆。微调相当于提前一周突击复习。可一旦考试来临,模型可能忘掉以前学过的内容,也可能答出一些从未被教过的东西,表现得像个“半吊子”。
而使用嵌入,情况就完全不同了。这就像学生没怎么复习,但带了一张“作弊纸”进考场。面对问题时,他只需要快速查阅作弊纸,就能给出准确答案。考完试后,作弊纸一扔,不占任何“脑容量”。整个过程简洁高效,技术实现也是如此。
不过,这种“作弊纸”方法也有局限。每次考试,学生只能带有限的几页笔记,不可能把所有教材都带进去。同样,大型模型单次能接收的文本量(最大令牌数)是有限的。GPT-3.5的令牌限制是4K(约5页纸),而GPT-4把这个上限提高了八倍,达到32K(约40页)。
那么问题来了:当需要处理的数据量远超这个令牌限制时,该怎么办?这正是基于嵌入+上下文注入的语义检索策略大显身手的地方。
之前有一篇文章讨论过“GPT-4与微软新必应的集成效果为什么不如预期”,那里简要提到了嵌入在搜索引擎中的应用。接下来,我们用构建一个本地知识问答系统为例,把原理讲清楚。这个过程可以分三步走:
步骤1:数据准备
- 准备好本地知识库的文本资料,比如文章、报告、日记、博客、网页、研究论文等。
收集:
- 把整篇文档拆成更小的文本片段。
切分:
- 用OpenAI API或本地嵌入模型,把每个文本片段转化为多维向量。
嵌入:
- 数据集较大的话,把向量存起来备用;数据集较小的,也可以临时存储。
存储:
步骤2:语义检索
用OpenAI Embedding API或本地嵌入模型,把用户的问题也向量化。
通过相似性度量(比如余弦相似度或欧几里得距离),找到与问题最相似的文本片段。
步骤3:文本注入与回答
把用户的问题,以及检索到的最相似文本片段(TopK),作为上下文提示一起注入LLM。
LLM根据这些提示,结合少量示例,生成最终答案。
下面是整个实现流程的示意图:
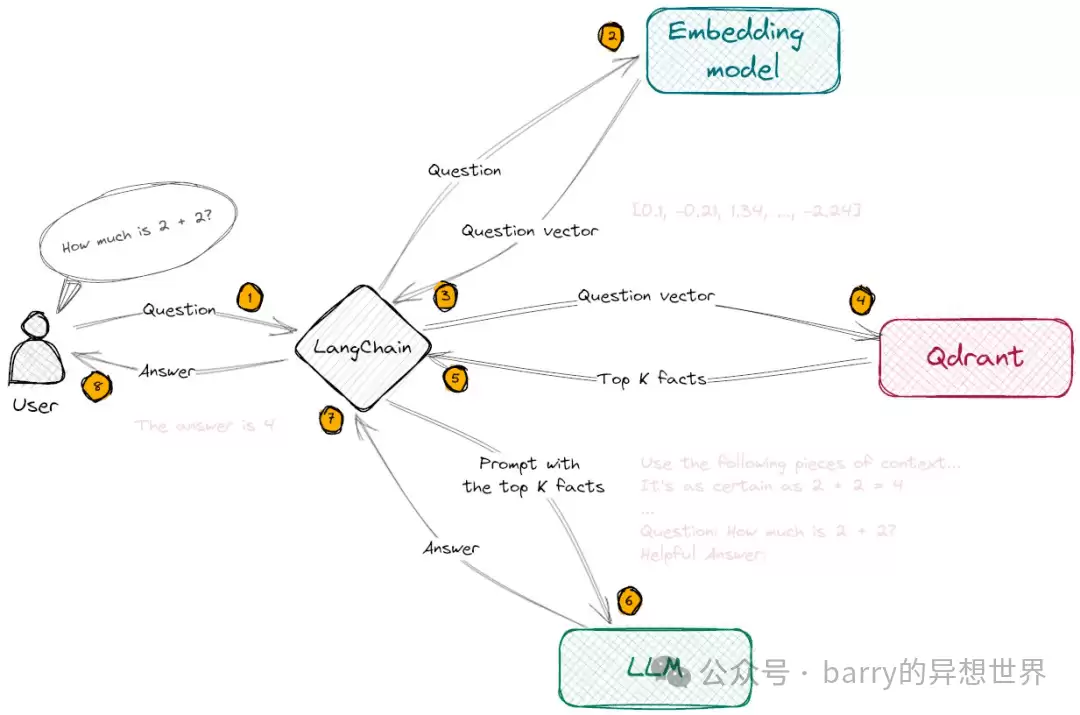
嵌入式语义检索 vs. 基于关键词检索:优势对比
- 嵌入式检索能捕捉词与词之间的语义关系,让模型真正理解“相关”意味着什么。而关键词检索往往只认字面匹配,很难看出词汇背后的联系。
语义理解:
- 遇到拼写错误、同义词或近义词,嵌入方法依然能准确判断。关键词检索在类似情况下则容易“掉链子”。
鲁棒性:
- 许多嵌入方法支持跨语言检索。比如你用中文输入问题,它能找到英文文本中的相关内容——这对关键词检索来说基本是道“超纲题”。
多语言支持:
- 一个词在不同语境下可能含义完全不同。嵌入方法可以根据上下文为词分配不同的向量表示,从而区分一词多义。关键词检索在这方面就显得力不从心。
语境理解:
说到语境理解,人类交流时之所以能“心有灵犀”,靠的是共享的知识和经验。比如“你应该Google一下”这句话,只有当你既知道Google是搜索引擎、又知道它常被用作动词时,才算真正理解。同样,一个好的自然语言模型,也必须能根据上下文推测每个词、短语、句子或段落的可能含义。
嵌入检索的限制
- 即便用了嵌入,仍然绕不开令牌长度的问题。为了控制注入上下文的令牌数量,通常会把TopK检索中的“K”值设得比较小,这就有可能遗漏重要信息。
输入令牌限制:
- 目前GPT-3.5和许多大型模型还不具备图像识别能力。但在实际工作中,很多知识检索任务需要结合文本和图像——比如学术论文里的插图,或者财务报告中的图表。
仅限文本数据:
- 当检索到的文档内容不足以支撑模型回答问题时,模型可能会尝试“脑补”,编造一些看上去合理但实际错误的内容。
可能产生虚构内容:
不过,这些问题并非无解,已经有相应的应对策略:
- 有一篇论文《使用RMT扩展Transformer至1M令牌及更远》提出,用循环内存技术可以把模型上下文长度有效扩展到200万个令牌,同时保持高精度。此外,像LangChain这样的应用也通过工程手段巧妙绕过了令牌限制的瓶颈。
令牌限制:

- 除了GPT-4本身支持图像理解外,还有一些开源项目(比如Mini-GPT4,结合BLIP-2)也实现了基本的图像理解能力。这个问题相信会在不久的将来迎刃而解。
多模态理解:
- 这个其实可以在提示层面就解决。最简单的方法:在提示中加一句“如果你不知道答案,就直接说不知道,不要编造答案。”效果立竿见影。
虚构问题:
当然,在实际应用开发和落地过程中,还有不少坑需要填:
问题阶段做摘要时,如何避免信息丢失?
不同应用场景下,该选哪种相似性算法?
文档可信度该怎么评分?
不同模型在提示模板层面有哪些差异?
注入上下文后,文档分段方式会对问答效果产生多大影响?
以下是一些与嵌入(Embedding)相关的资源
矢量数据库
Pinecone(全托管)
PGVector(免费)
Wea viate(开源)
Qdrant(矢量搜索引擎)
Milvus(专为可扩展相似性搜索设计)
Chroma(开源嵌入式存储库)
Typesense(快速开源矢量搜索引擎)
Zilliz(由Milvus驱动)
文本矢量化工具
文本相似性比较算法
余弦距离
L2平方距离
点积距离
汉明距离
