
Agentic RAG 与图任务编排
一个朴素的 RAG 系统,流程上大致是这样:用户提出问题,系统基于提问去召回信息,再对召回结果做一轮重排序,最后拼好提示词交给大模型来生成答案。
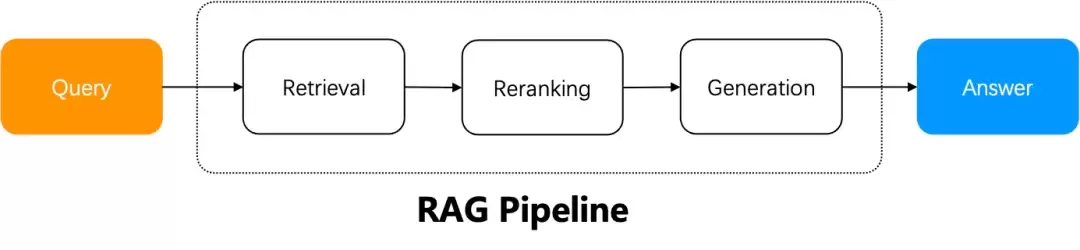
在一些简单的场景下,这种朴素的RAG确实够用——毕竟答案就藏在检索结果里,交给LLM处理就好。但现实往往没那么理想:用户的意图经常是模糊的,没法单靠一次检索就精准命中。比如,让系统对多份文档做个总结,或者提出需要多步推理的问题,这就不是直接检索能解决的了。这时候,就得请出 Agentic RAG——在问答流程中引入一套任务编排机制。
Agentic RAG,顾名思义,就是基于 Agent 的 RAG。
Agent 和 RAG 的关系,其实是互为基石。
引入了 Agent 的动态编排能力。这样一来,系统就能根据用户提问的不同意图,灵活地进行反馈、改写查询,甚至进行“多跳”式的知识推理,最终把那些复杂的问题给答明白。
要理解 Agentic RAG 是怎么工作的,不妨先看两种高级实现。先说 Self-RAG(参考文献[1]),它的流程大致如下:
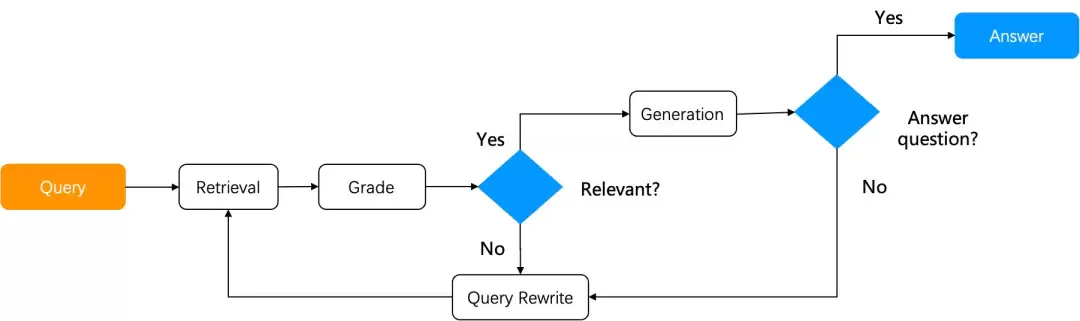
Self-RAG 本质上是给 RAG 加了一层“反思”机制。从知识库里检索出结果后,它不急着用,而是先掂量掂量:这结果跟用户的问题沾边吗?如果不沾边,就重写查询,再来一遍 RAG 流程,直到相关性达标为止。要想实现这套机制,得搞定两个关键组件:
- 一套基于图(Graph)的任务编排系统。
图里要跑的各种必要算子——在 Self-RAG 里,评分算子就是重中之重。原始论文里,需要自己训练一个打分模型来给检索结果打分;不过实际落地时,直接用 LLM 来评分也能行,这样能简化开发,少依赖其他环节。
Self-RAG 算是 Agentic RAG 里相对初级的版本,RAGFlow 已经把这个功能做进去了。实践证明,它在应对比较复杂的多跳问答和多步推理时,确实能带来明显的性能提升。
接着说另一种实现——Adaptive RAG(参考文献[2])。它的思路更聪明:根据用户提问的不同意图,动态切换策略:- 如果问题简单直接,那就让 LLM 直接回答,不用绕弯子走 RAG 检索。
开放域问答:
- 先把一个复杂查询拆成几个简单的单跳查询,然后反复跟 LLM 和 RAG 检索器打交道,逐个解决子问题,最后把答案拼起来。
多跳问答:
- 专治需要多步逻辑推理的复杂问题。这类问题往往要综合多个数据源的信息,一步步推理。自适应检索会迭代地调用 RAG 检索器和 LLM,逐步搭建起解题所需的信息链条。
自适应检索:
从下图能看出来,Adaptive-RAG 的工作流跟 Self-RAG 挺像的,只不过在前面多加了一个查询分类器。正是这个分类器,让它有了更多样的对话策略可选。
看完这两个例子,可以总结出:这类高级 RAG 系统,都离不开一个基于图的任务编排系统,而且得具备以下能力:- 能复用已有的 Pipeline 或子图。
能跟外部工具(比如 Web Search)协同工作。
能对查询任务做规划,比如意图分类、查询反馈等。
目前比较主流的任务编排系统实现,有 LangChain 的 LangGraph 和 llamaIndex;Agent 的开发框架方面,则有 AgentKit、Databricks 新发布的 Mosaic AI Agent Framework 等等。任务编排系统必须基于图来实现,图里的节点和边定义了应用的流程和逻辑。节点可以是任何可调用的算子,也可以是其他可运行的组件(比如串联起来的多个算子或 Agents),每个节点负责完成特定任务。边则定义了节点之间的连接和数据流向。图还需要有状态管理能力,这样节点跳转时,状态就能实时更新。需要特别注意的是,这种基于图的任务编排框架并不是一个 DAG(有向无环图),而是一个必须有循环的系统。环是提供反思机制的基础,对 Agentic RAG 的编排来说,至关重要。没有反思机制的 Agent,充其量只能做点类似工作流的任务编排,根本实现不了高级的多跳和多步推理,也无法像人类那样真正“思考”着去解决问题。吴恩达总结过四种 Agent 设计模式(参考文献[3]):反思被放在了第一位,其他三个都是工作流相关的——工具、规划和多 Agent 协同。反思之所以被单独拎出来,就是因为思考和推理都得靠它。而 Agentic RAG,正是这种反思机制在 RAG 领域的具体体现。
Agentic RAG 代表了一种信息处理方式的变革,它给 Agent 本身注入了更多智能。
参考文献:
- Self-RAG: Learning to retrieve, generate, and critique through self-reflection, arXiv preprint arXiv:2310.11511
Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity, arXiv preprint arXiv:2403.14403
https://www.deeplearning.ai/the-batch/issue-242/
