
测评 | 4090 显卡对 AI 模型到底有没有用?一张图告诉你真相
今天这篇测评,想聊一个很实际的问题:显卡到底能不能给AI模型推理带来实实在在的加速?
01 细节
先交代一下测试环境:
使用显卡:4090D
待测 AI 模型:whisper 音频转文字 AI 模型
被测数据:10s 长度音频、30s 长度音频
02 背景
之前做音频转文字的时候,一直没开显卡加速,全靠CPU硬扛。昨天刚把显卡推理加速的流程跑通,今天赶紧拉出来对比一把——
有没有显卡,对AI模型推理的加速效果到底差多少?
whisper 官方一共提供了八个模型版本:tiny、base、small、medium、large、large-v1、large-v2、large-v3。不同模型在准确率和速度上的差异很大,所以这次把每个模型都测了一遍。
03 无显卡
先看10秒长度的音频,无显卡加速,纯CPU推理的结果:
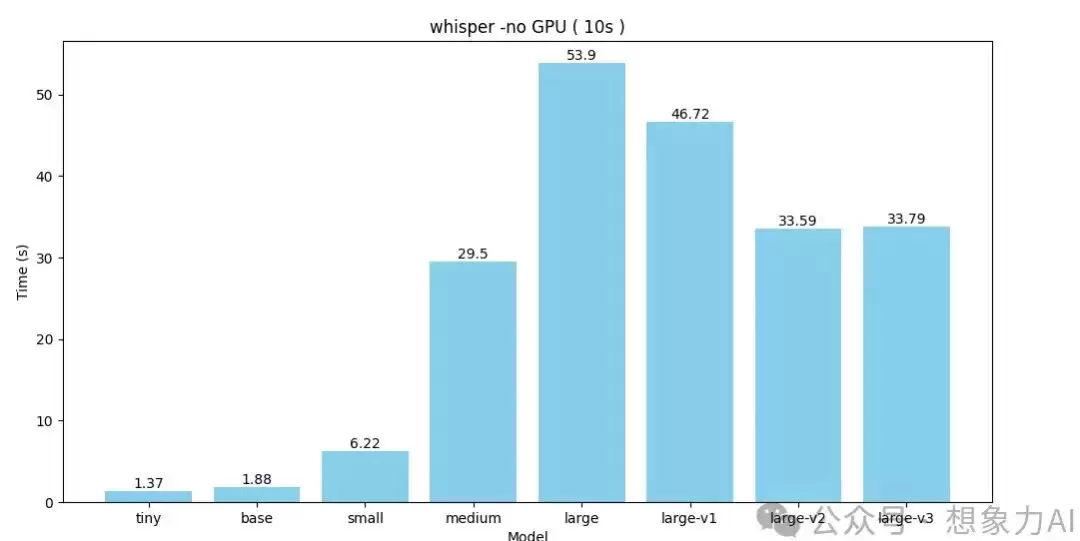

tiny 和 base 模型跑得飞快,但识别准确率明显拉胯,出现了错别字。说白了,
这是拿智商换速度
从 medium 模型开始,准确率终于上来了,但消耗的时长也突然飙升——10秒的音频,medium 跑了29秒,几乎是原音频长度的3倍。到了 large 系列,时间更夸张,基本都在40秒开外。
04 有显卡
接下来上显卡推理加速,同样的10秒音频,结果完全不一样:
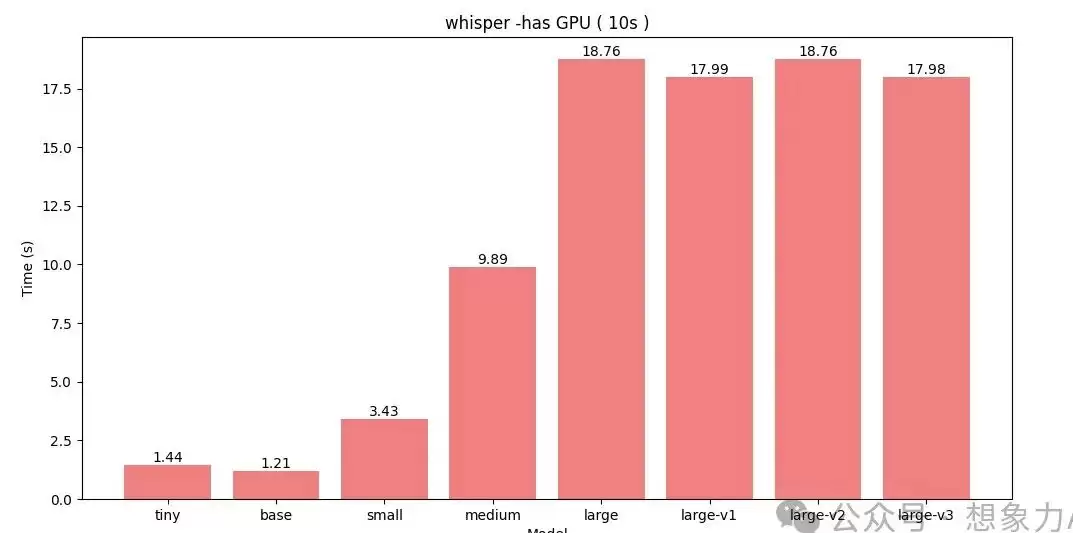

有显卡加持后,large 系列模型的推理时间全部稳定在18秒左右,不到原音频长度的2倍。对比之前动辄30~50秒的CPU推理,这已经降了一大截。
05 进一步对比
这时候会想:原音频长度对推理时长的影响有多大?换个30秒的音频再来一轮:
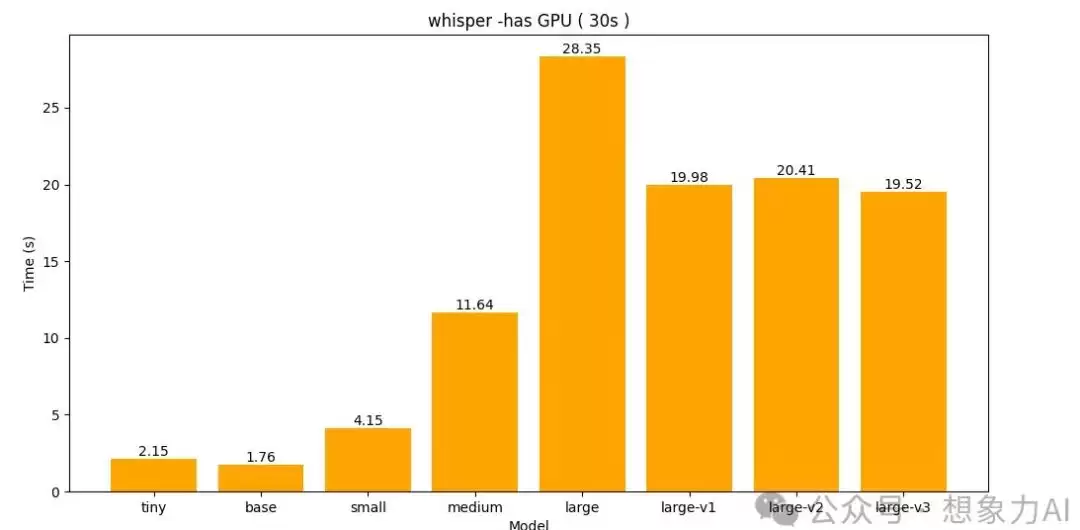
把三次测试的结果放在一起,趋势就很清楚了:
蓝色是无显卡+10秒音频,红色是有显卡+10秒音频,橙色是有显卡+30秒音频。
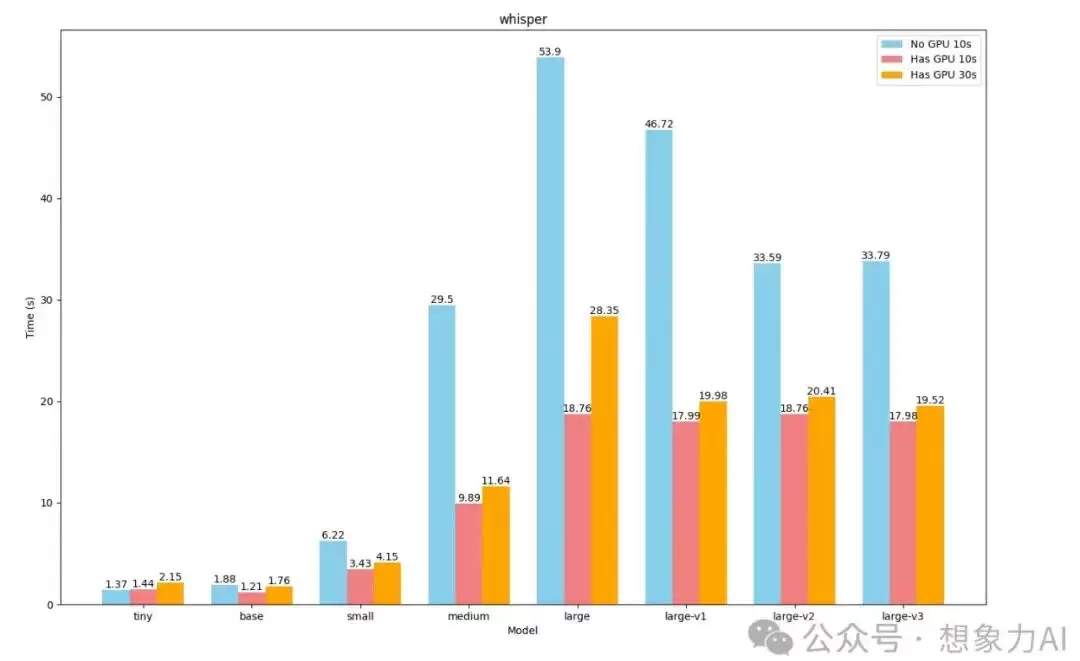
从柱状图上能直观看到,无显卡的large系列耗时普遍在40秒以上,而有显卡后全部压在20秒以内,差距非常明显。
06 结论
在保证准确度的前提下——比如都使用 large 系列的模型——无显卡的平均时长为
42.00秒
18.37秒
结论很清楚:使用 GPU 后,推理速度提升了约 56.26%。
从整体测评结果来看,这块显卡的价值总算没白费。也给大家一个推荐:
