
提示工程师的“末日”?北大发布PAS系统,自动增强提示,解放你的双手!
“技术的终极承诺是让我们通过按一个按钮就能指挥世界。”——这话出自沃尔克·格拉斯穆克之口,放在今天的大模型时代来看,倒像是为提示工程量身定做的注脚。
自大型语言模型(LLM)崭露头角以来,提示工程——也就是通过不断调整指令来优化模型输出——就成了模型调参之外,另一门充满“玄学”色彩的炼丹手艺。随之而来的,是“提示工程师”这个新兴角色的崛起。但问题在于,哪怕是最老练的提示工程师,也很难保证自己调出来的提示就是最优解。这种不确定性,恰恰是LLM落地时最头疼的瓶颈。
最近,北京大学团队拿出了一套名为PAS的系统,试图解决这个痛点。这套系统主打“即插即用”,目标是自动增强提示,让模型输出质量大幅提升。根据他们公布的数据,PAS在多个基准测试上实现了平均超过6个百分点的效果提升,个别场景甚至超过了10个百分点。更关键的是,这个过程是全自动的——换句话说,它想把提示工程师从繁琐的手工调试中彻底解放出来。
提示工程的困境:不是不想优化,是成本太高
提示工程的核心目标,是通过自动化的方式增强提示,减少人工干预,同时提升LLM在特定任务上的表现。这个思路本身没问题,但现有的方法,包括链式思考(Chain of Thought)和思维树(Tree of Thought)这类策略,虽然在逻辑一致性上有所改善,但扩展性很差。你要让它们覆盖更多场景,就得投入大量资源去评估每个提示的“适应度”,一旦涉及多组提示的探索,计算负担立刻就拉满了。
还有些研究试图从优化器的视角来自动寻找提示,或者把演化算法引入离散提示优化。这些方向有潜力,但实际落地时依然面临同样的困境:成本太高,效率太低。
PAS系统:一个“即插即用”的自动补丁
北大团队的做法很有意思。他们没有试图从零开始重构提示工程的方法论,而是走了一条更务实的路——给原始提示“打补丁”。PAS系统的核心思路是自动生成高质量的补充提示,然后把它和原始提示拼接起来,形成一个增强后的输入。这样一来,LLM的潜力就能被更充分地释放,而整个过程不需要人类干预。
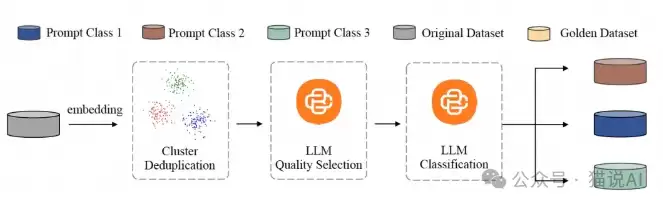
这个系统具体怎么实现的?关键在三个环节。
首先是数据集构建。团队从LMSYS-1M和WildChat两个数据集中筛选高质量提示,经过去重、质量筛选和分类,最终整理出一个包含9000个(提示,补充提示)配对的数据集。这个规模不算大,但胜在精。
然后是自动数据生成。他们设计了一条基于少样本学习的自动化管道,利用精选的“黄金数据”对每个类别的提示进行少样本学习,自动生成对应的补充提示。
最后是即插即用系统。用上面生成的数据集微调一个专门的LLM,让它具备自动输出补充提示的能力——这就是PAS模型的核心。
PAS的优势:不止是效果好,更是成本可控
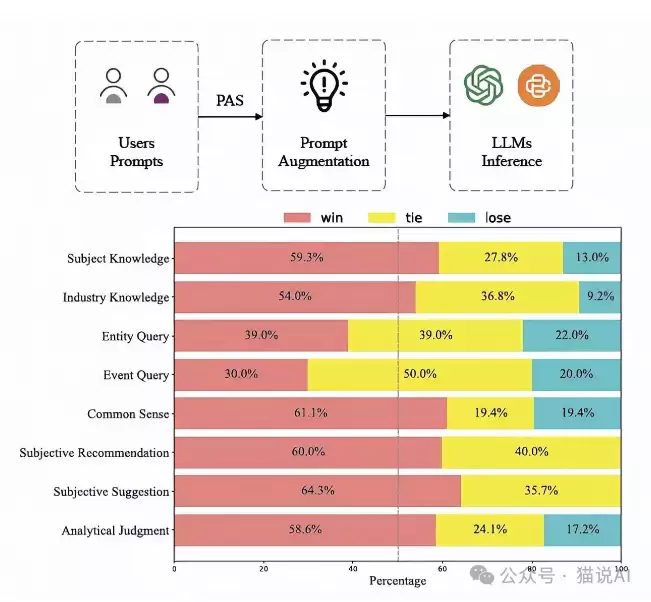
从实验结果来看,PAS系统的表现确实亮眼。和基础模型相比,它在所有指标上都有明显提升;即使是和已有的BPO模型对比,PAS在多数场景下也占据优势。而且,这种提升在不同规模的LLM上都能复现,不是只对某个特定模型有效。
人工评估的结果也印证了这一点。在多个应用场景中,PAS增强后的模型在回答的准确性、相关性和全面性上,都明显优于原始模型。
更值得关注的是它的数据效率。只用了9000条数据就实现了显著的性能提升,而不少同类方法动辄需要数万甚至数十万条数据。这在实际工程中,意味着更低的标注成本和更短的迭代周期。
另外,PAS的“即插即用”设计也让它的灵活性大大增强。不需要对目标LLM做任何重新训练或架构修改,直接集成即可。这一点,对于想要快速部署的企业来说,价值不言而喻。
未来还能怎么走?
PAS系统的出现,确实给提示工程领域带来了一些新思路。但要说它是否就宣告了提示工程师的“末日”,可能还为时过早。毕竟,这套系统目前还依赖于少样本学习的数据生成质量,而更强大的数据生成方法、更灵活的集成方式、更广泛的应用场景,都还需要进一步探索。
不过,一个趋势已经很明显:提示工程正在从一门“手艺”转向一套“系统”。从这个角度看,PAS的贡献不只是技术上的突破,更是对行业分工的一次重组信号。可以确定的是,大模型应用的门槛,正在被一点点降低。
