
非结构化数据解析 &GenAI的应用探索和实践(文字稿)
一、前言
今天的分享,从一堆看起来有点“脏”的数据开始——非结构化数据。
随着RAG+大模型的技术栈走红,大家有目共睹,大模型在处理文本这件事上确实让人眼前一亮。但在实际的企业应用场景里,大概有80%的时间,我们其实是在跟非结构化数据打交道。从各种Office文档到图片、音频,形态五花八门。而正是大模型的出现,让这些过去很难被程序高效理解和利用的数据,真正“活”了过来,在内容检索、理解和再利用上提升了整体效率。
本次分享将重点围绕三个方向展开:
- 第一,非结构化数据处理。做RAG产品,这条路基本从数据解析开始。这部分会聊聊技术中间件选型,以及PDF表格解析等具体细节。
- 第二,企业AI场景的落地应用。结合产品实践,谈谈我们的探索和思考。
- 第三,一些总结和个人感想。
二、非结构化数据的解析难点与细节
基于RAG进行技术栈开发时,遇到的第一个硬骨头就是非结构化数据的解析。我们需要把各种格式的数据解析成文本,再通过检索和Prompt设计,让大模型完成推理和生成,最终解决企业工作中的实际问题。这个过程里,挑战不少:
- 文件种类实在太多,范围太广。
- 老旧文件的支持问题,比如DOC、XLS、PPT这些老格式。
- 表格解析是最让人头疼的难点。
- OCR的启动时机,需要在成本、效率、性能之间反复权衡。
- PDF中布局识别能力的突破。
- 还有文件的字符编码问题等等。
实际开发中,细节远比列出来的要多。就拿PDF格式来说,光是1.7规范就有将近800页,想全部读完再完美解析,基本是天方夜谭。
在TorchV的整个技术架构中,Ja va占了近80%的份额,包括文件解析和内容提取。这一点可能和市面上常见的开源方案有些不同。

在Ja va生态里,针对上述文件解析问题,有三个Apache下的中间件表现非常突出,在RAG场景里扮演着重要角色。
- :早在2002年就进入了Apache基金会。最初主要处理Excel电子表格,后来逐步支持Word、PPT、Visio等多种格式。POI最大的优势在于对老文件的支持,像DOC、XLS、PPT这些,完全可以不依赖外部插件或中间件直接解析提取文本。相比Python生态,后者处理Office文件时,比如解析docx,通常需要先把doc转成docx再提取,依赖较多。Ja va靠着多年积累,在这方面显然更有底气。实际对接大客户时,老文件的占比确实不低。
Apache POI
- :一个综合性很强的文件解析项目。起初作为Apache Nutch的一部分,2007年独立发展为顶级项目。Tika封装了POI、PDFBox等依赖,能通过识别文件的魔法值自动判断文件类型,并提供标准输入流和转换方法。它还集成了OCR功能,解析文件时遇到图片资源会自动启用OCR提取。
Apache Tika
- :开源领域非常成熟完善的PDF处理中间件。2008年进入Apache基金会,对PDF规范支持到位,提供了高层次的抽象接口,方便开发者进行自定义扩展。
Apache PDFBOX
在整个非结构化数据提取过程中,这三个Apache项目基本能覆盖80%的业务场景。虽然用大模型直接识别文件听起来很酷,但在企业场景落地时,文件解析仍需要从成本、性能、效率多个维度去考虑。基于规则的提取在可解释性上往往更有优势。
从实际支持的格式来看,这三个中间件覆盖了HTML、Office、PDF、图片、音频、压缩包等,企业应用中完全够用。

在所有文件格式中,PDF无疑是最令开发者头痛的,尤以表格提取最为麻烦。借助Apache PDFBox,目前有两种有效方法可以高效提取表格内容,还原表格信息。

第一种:Tabula组件。
第二种:提取PDF内容流的线坐标、矩阵信息。
基于坐标信息,其实还可以拓展很多内容,后面的案例会提到。
基于上述表格提取方式,PDFBox的整体UML架构如下图所示:
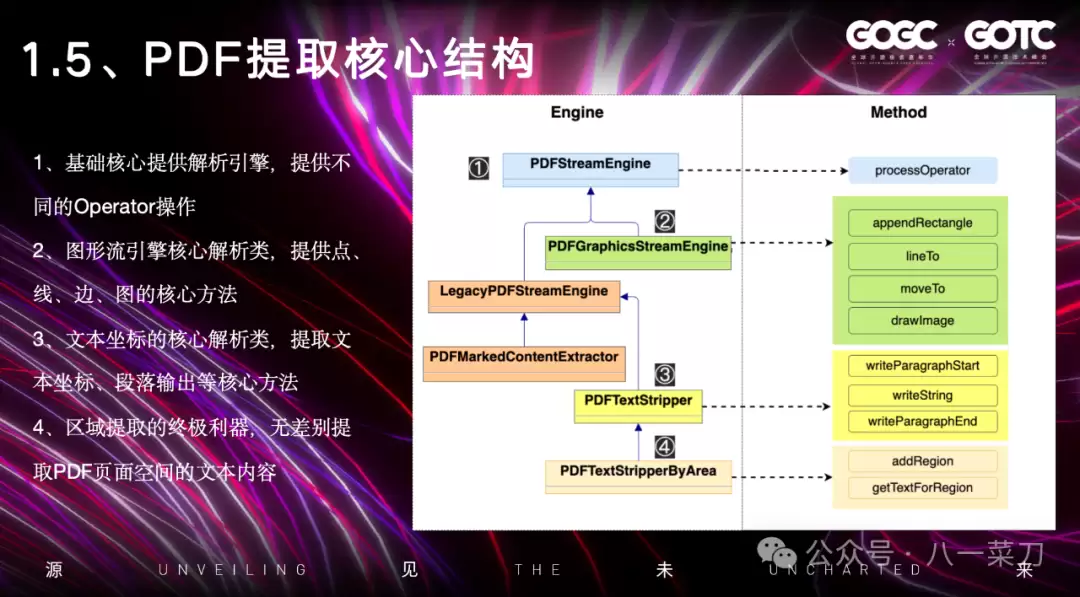
最顶部是PDF的基础引擎类。在PDF规范里包含大量Operator操作,而基于坐标、图片等信息的提取,都是通过这些Operator来扩展实现的。第二个引擎类专门用于提取内容流中的线、矩阵、图片等信息。最后是按文本坐标区域提取的核心类,这个方法非常实用,尤其在处理论文型PDF的双排排版时,通过大量实验验证,对文本排版空间的计算提取都很轻松。
三、应用探索与实践
场景一:知识库。
场景二:研报助手Assistant。

这本质是一个富文本编辑器。大模型在文本生成上已经很擅长了,输出效率比过去提升了数倍。但在企业严谨的场景下,模型输出有时会产生幻觉。RAG正是目前控制幻觉输出的理想技术手段,让模型基于给定的文本内容进行总结。Assistant结合了非结构化文本解析、向量检索、大模型归纳和富文本编辑器等多种技术。用户上传文档后,系统在文档内检索生成,特别适合需要严谨引用报告或大量文档阅读的场景,能极大提升编写效率。生成的文本还可以快速转换成饼图、柱状图、表格等不同图表形式。
场景三:规则匹配场景Comparison。
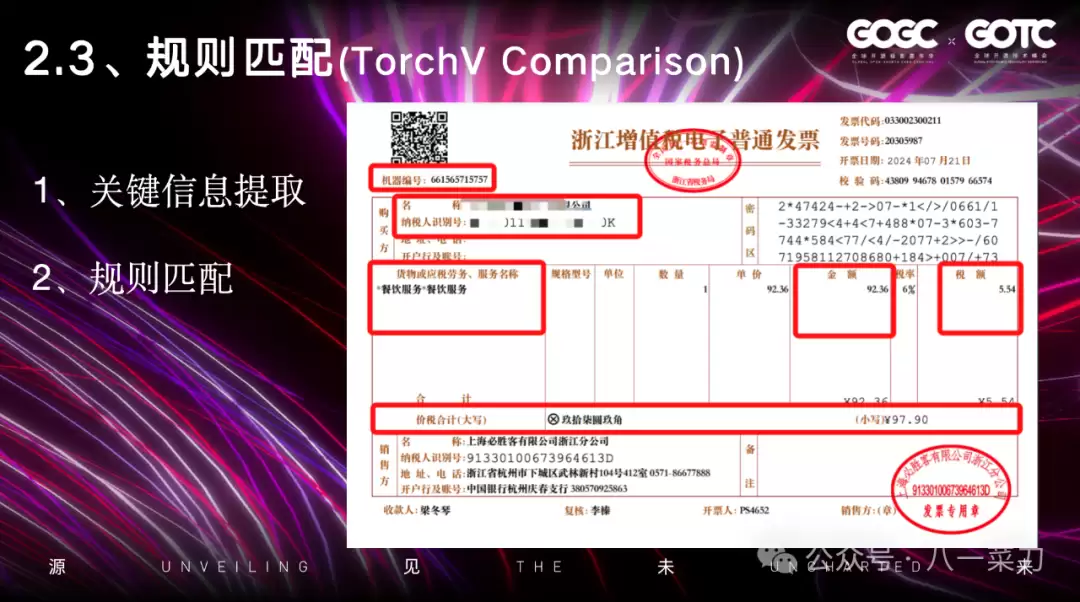
这一场景主要依靠之前处理PDF表格时的方法,可以根据区域信息无差别地提取关键字段。如果PDF是扫描版,会通过OCR进行区域信息提取,结合坐标空间相关算法将框定内容提取出来。此外,非结构化数据提取后,可以配合大模型的Agent能力,针对特定领域按规则提取关键信息。数据提取后,在应用层无论是校对还是总结,AI都能高效发挥作用,提升整体效率。
四、个人感想
第一个感想:AI技术栈很杂,是挑战,也是机遇。
要把RAG、大模型、向量检索这些技术栈真正落地,涉及的技术面非常广且杂。开发者不仅要关注数据处理,还要涉及检索、向量数据库、大模型Agent、Prompt、微调等多个领域。打造一个标准品并不容易,对企业和开发者都是不小的挑战。但正因有了AI大模型,今天的工作场景中涌现出很多有趣的应用和产品,这其中蕴藏着巨大机遇。在AI的加持下,开发者可以更大胆地畅想,这对探索和创新很有帮助。
第二个感想:数据质量是基石,重剑无锋。
数据质量是文本类AI应用的基石。无论是做RAG还是微调模型,在构建开发TorchV的过程中,大概80%的时间都花在了“怎样把数据处理好”这件事上——幂等地将非结构化数据最大程度提取和还原。这一步非常关键。RAG领域有句经典名言:Garbage in, Garbage out。所以,数据质量始终是必须着重关注的核心。
