
AI 驱动 + 亮数据赋能:揭秘亚马逊电商数据高效爬取的技术密码
网页抓取 API、网页解锁器、抓取浏览器、抓取函数、搜索引擎爬虫,这些工具一应俱全。不管是常规的网页数据提取,还是面对那些反爬策略层出不穷的棘手网站,开发者都能找到可用的武器。亮数据还搭建了数据集市场,提供现成或定制化的数据资源。技术底子上,它用先进的反封锁和验证码处理技术突破障碍,严格把控数据质量——这倒是实实在在地提升了开发效率。
但话说回来,如今互联网平台为了守住数据安全,纷纷祭出反爬虫机制:验证码、IP 限制、动态加载页面、复杂的 Ja vaScript 验证……这些招数层层叠叠。它们确实保护了网站数据,可也给合法数据采集者挖了一道又一道坑。采集者不得不投入更多人力、时间绕开这些障碍,效率大幅滑坡,严重的时候,采集工作直接卡死。尤其 IP 封锁和访问频率控制这一块——只要采集方对同一网站访问太频繁,服务器立刻拉警报,直接封 IP。对企业来说,这简直就是一场“噩梦”。IP 一封,数据采集中断,效率骤降不说,运营成本还蹭蹭上涨。再加上部分网站搞地域性 IP 封锁,数据采集的难度瞬间几何级增长。
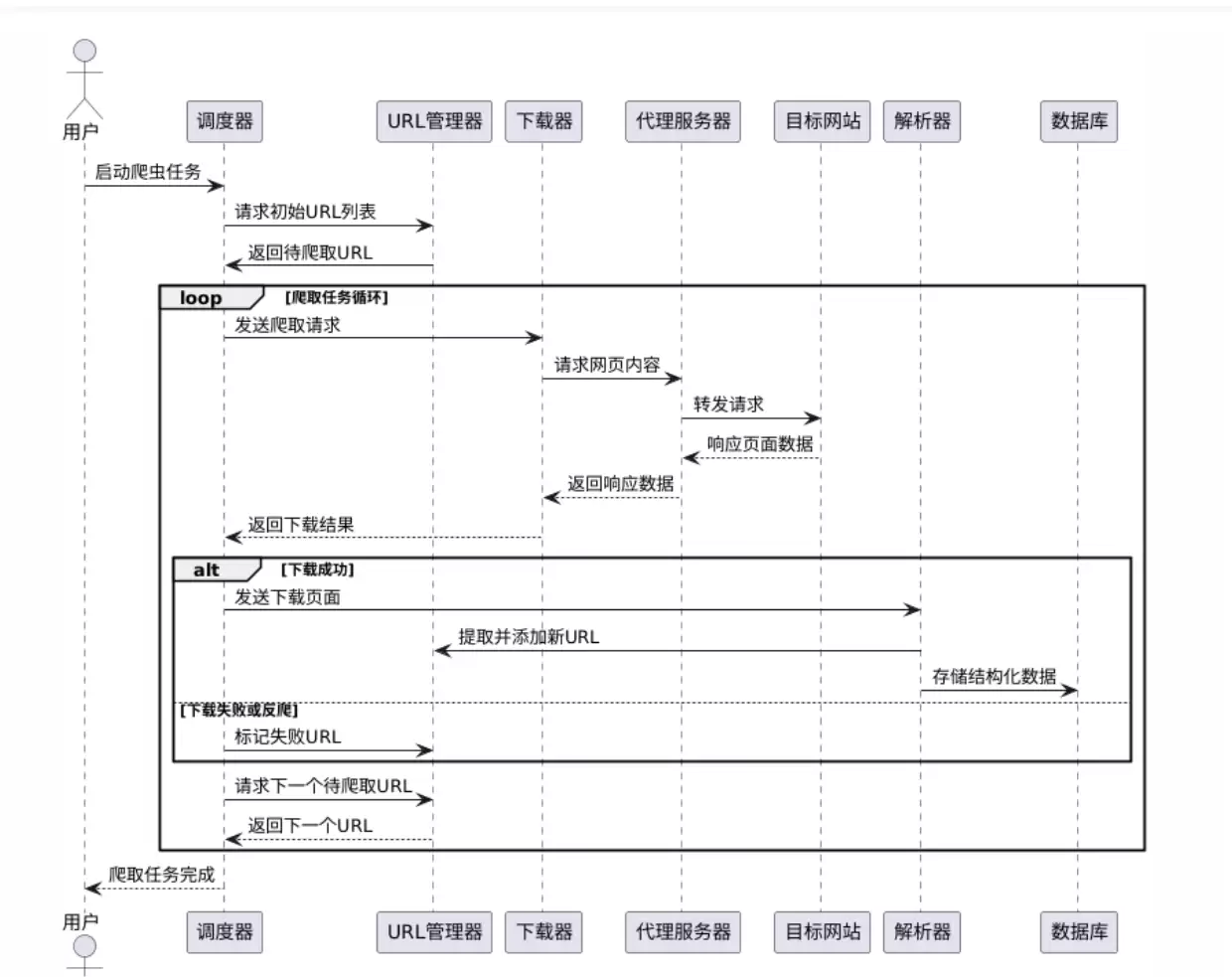
下方是传统的爬虫流程
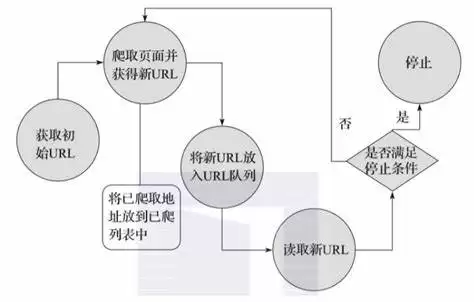
这时候,亮数据登场了。凭借先进的技术和完备的方案,它把反爬虫机制带来的种种难关一一攻克,帮助开发者与企业高效、合规地开展数据采集——为数据获取和利用铺出一条顺畅的通道。
亮数据简介
网络数据爬取的稳定性和功能强大性
亮数据(Bright Data)是一个专注提供先进网络数据抓取与解析服务的平台。它给用户提供了多种工具和技术,帮助他们在复杂的数据收集环境中快速、准确地拿到所需数据。通过亮数据的服务,用户可以轻松应对常见的抓取难题,比如 IP 限制、验证码、动态内容加载等等。
它的一大优势在于爬虫技术扎实。平台支持抓取各种数据源,包括电商平台、社交媒体、搜索引擎等。无论是基于 URL 抓取,还是通过关键字和搜索结果挖掘数据,它都能提供高效、可靠的方案。此外,亮数据还配备了袋里 IP、API 等技术支撑,帮助用户突破访问限制,确保数据采集的稳定性与效率。
使用界面简易,容易上手
使用方面,亮数据的界面做得简洁易用,新手也能快速上手。用户可以根据需求选择合适的工具和数据集,高效地抓取和分析。而且,计费方式灵活,按项目需求选就行,避免资源浪费。
亮数据防护墙功能
亮数据还推出了一个叫“Bright Shield”的防护系统,专门保护抓取过程中的风险。它能有效防止 IP 封锁、数据泄露等问题,确保大规模数据抓取时的安全性和稳定性。
整体来看,亮数据是一个功能强大的网络数据抓取平台,特别适合有大规摸、高效采集需求的企业与开发者。不管是电商、市场分析还是学术研究,它都能提供精准的数据支持和技术保障。
亮数据的内置 AI 回答
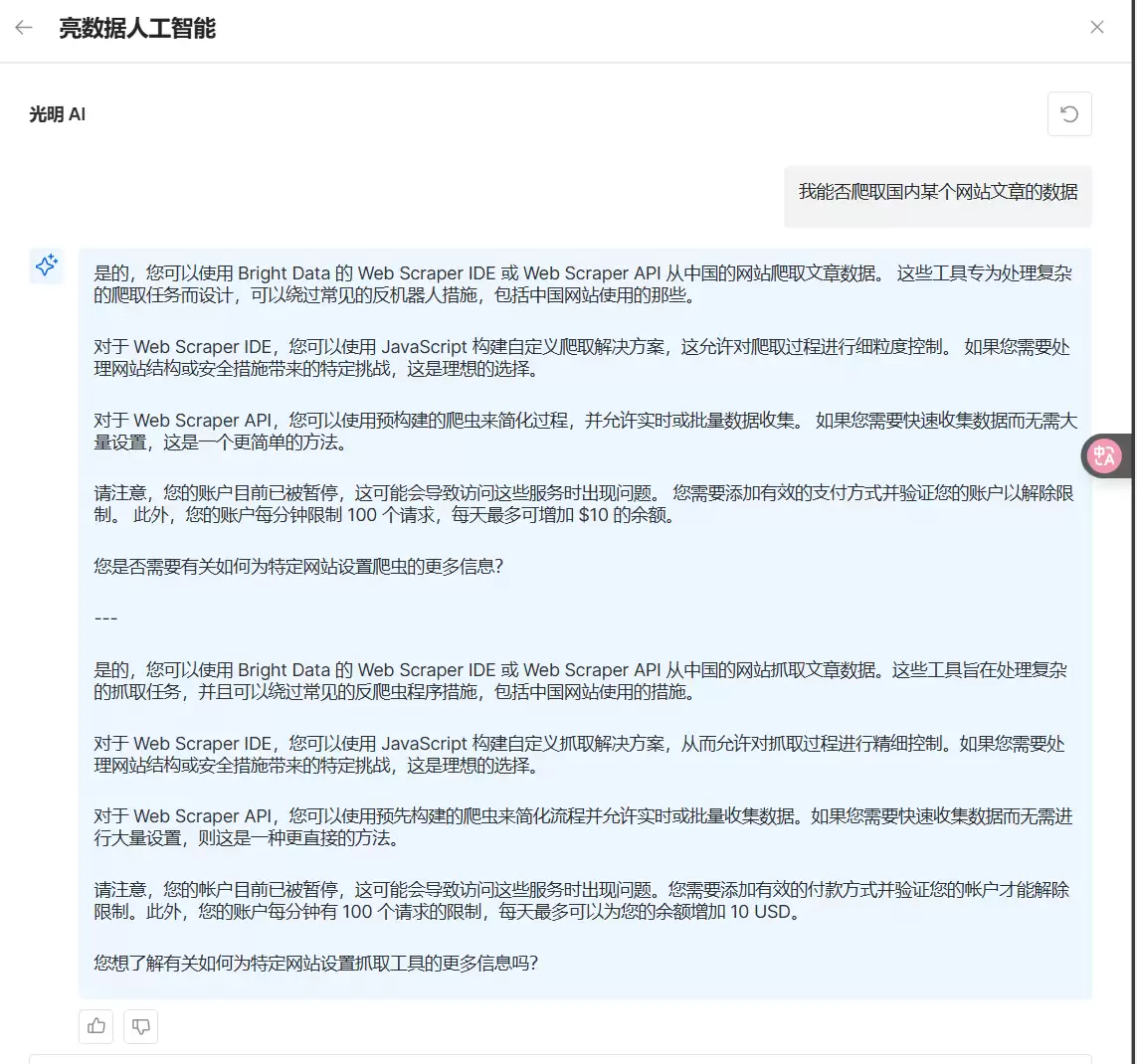
在亮数据的主页上,有一个 AI 回答小助手。对刚接触亮数据的同学来说很友好——不懂的随时可以问。
它会根据账号信息和实际问题,给出客观的评价分析。
亮数据实战:对亚马逊网站数据的爬取操作
电商行业竞争越来越白热化,精准的市场数据就是卖家的决策命脉。以亚马逊爬取为例——最初按常规流程走,以为掌握了基础教程就能高枕无忧,结果在实际业务中还是碰到了意想不到的挑战。
按照标准流程,完成了亚马逊某品类下大量商品页面的基础数据采集,包括商品标题、价格、销量等信息。可当把这些数据用于选品决策时,问题冒出来了:爬取的数据中,商品评价的关键词大量缺失,而这些关键词偏偏是反映消费者痛点和需求偏好的关键指标,对挖掘潜在爆款商品至关重要。排查后发现,亚马逊针对频繁访问设置了反爬虫机制,部分页面爬取时触发了验证环节,导致评价数据拿不全。
怎么解决?进一步优化了亮数据的使用策略。首先,利用亮数据的动态 IP 轮换功能,模拟不同地区、不同用户的访问行为,降低被识别为爬虫的概率。同时,结合智能袋里池,设置合理的请求间隔,避免短时间内大量请求同一页面。针对触发验证的页面,通过亮数据的会话管理功能,模拟真实用户手动操作流程,完成验证后再继续采集。这一系列优化下来,不仅成功获取了完整的商品评价关键词数据,还显著提高了数据采集的稳定性和准确性。基于这些完整数据,精确定位到了消费者对某类家居用品在材质环保性、收纳便捷性方面的强烈需求,据此调整选品策略,后续推出的新品在市场上获得出色销量表现,几乎是可以预见的。
具体的操作过程是怎样的呢?在 Proxies & Scraping 中找到浏览器 API,点击开始。可以对选中的浏览器进行抓取操作:运行和缩放远程浏览器,内置解锁功能用于 Web 导航、交互和数据提取。
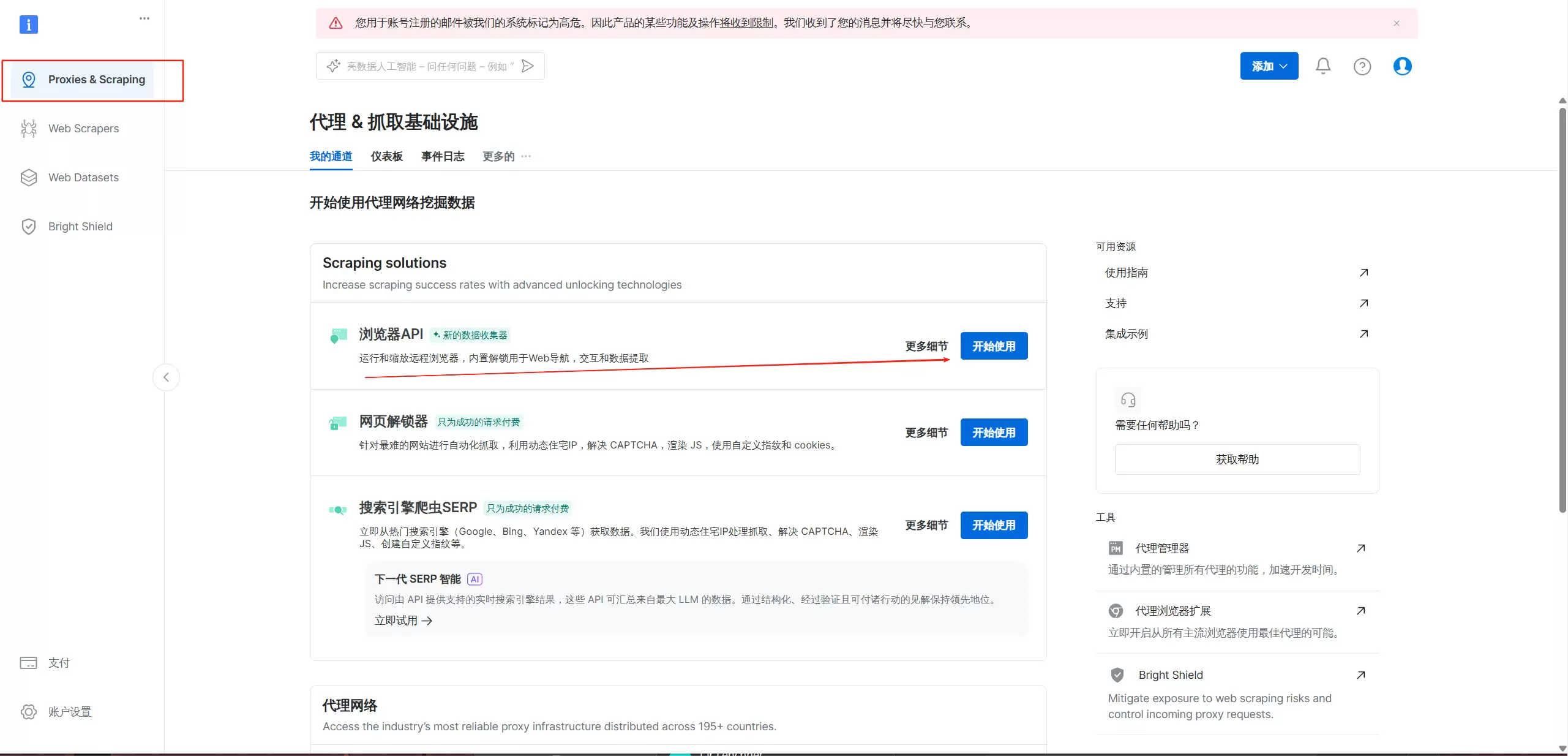
点击详情会发现,这个功能相当强大——全自动解锁,验证码、浏览器指纹都不在话下。
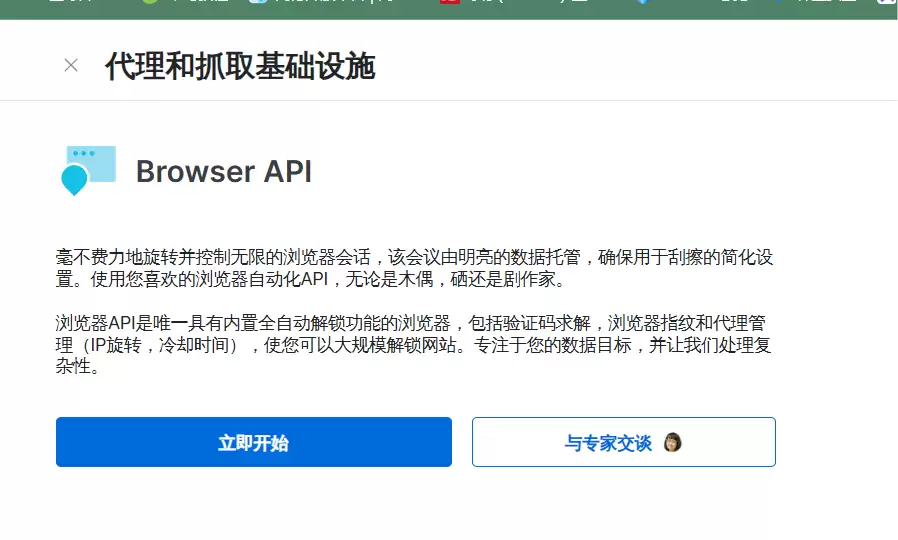
接着点击立即开始,进入设置界面后,根据自己的需求选择操作。注意后面两个选项是“只为成功的请求付费”——用多少扣多少,这样的模式很实在。
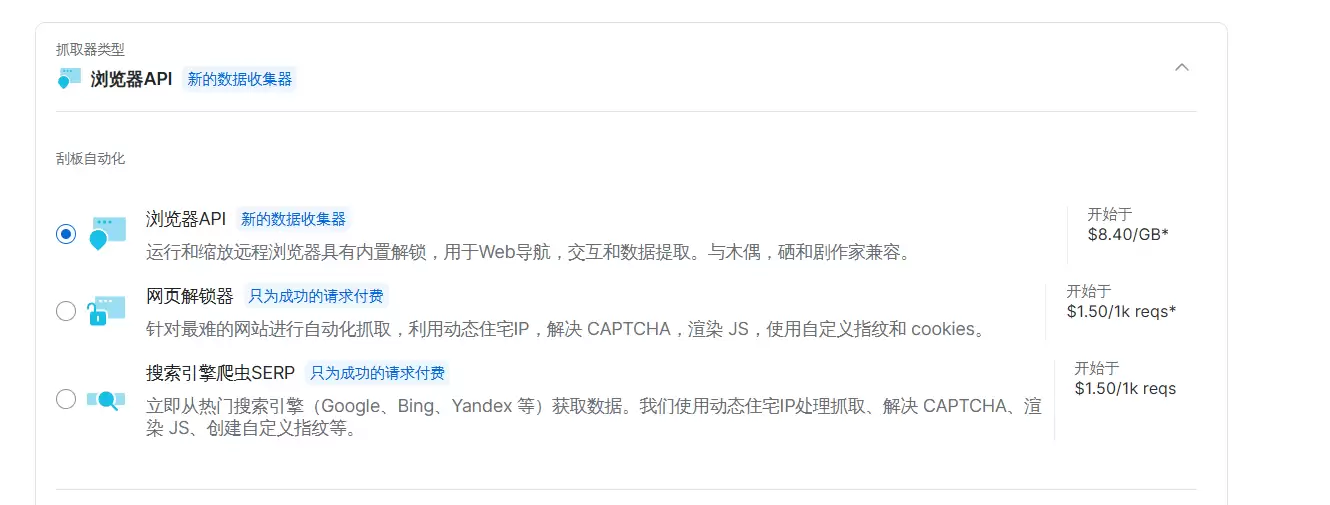
选择中间的“网页解锁器”就 ok 了。它专门针对最难的网站进行自动化抓取,利用动态住宅 IP,解决 CAPTCHA,渲染 JS,使用自定义指纹和 cookies。下面是几种抓取器的介绍。
底下的袋里选项,根据自己的需求变换选择,IP 可以随意变换,每个选项下面都有合理解释来辅助选择。

几种袋里的介绍如下。
接下来做基本设置:通道名称自定义(注意后期不能更改),通道描述可以随便填。
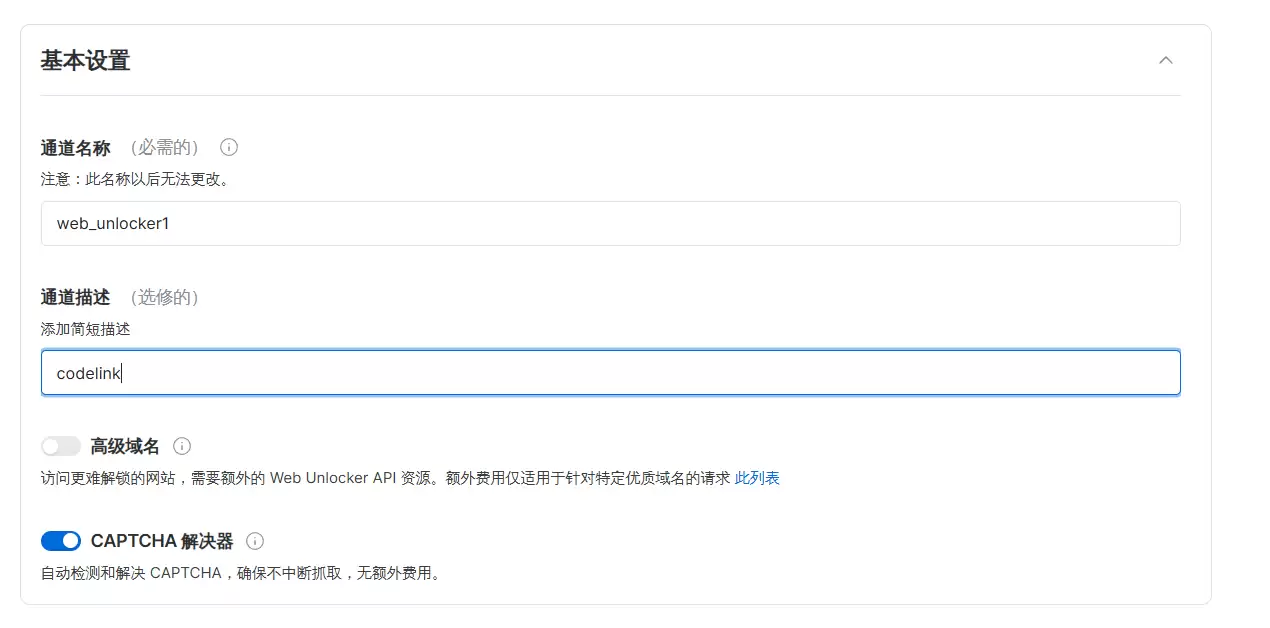
这里还有高级设置,按需调整。
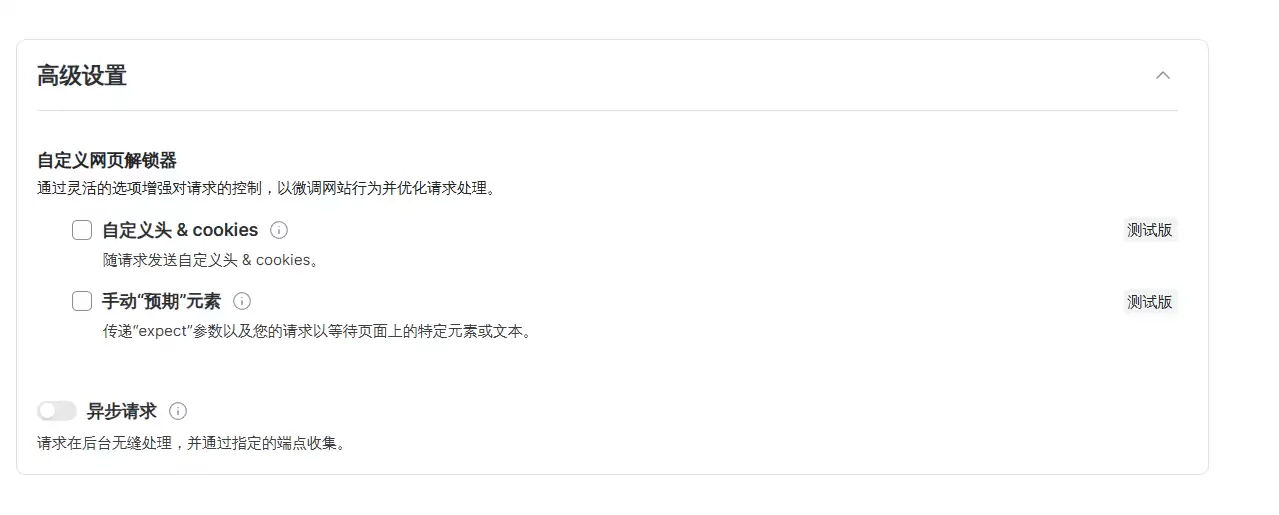
最后点击“添加操作”,把我们设置好的通道加进去。
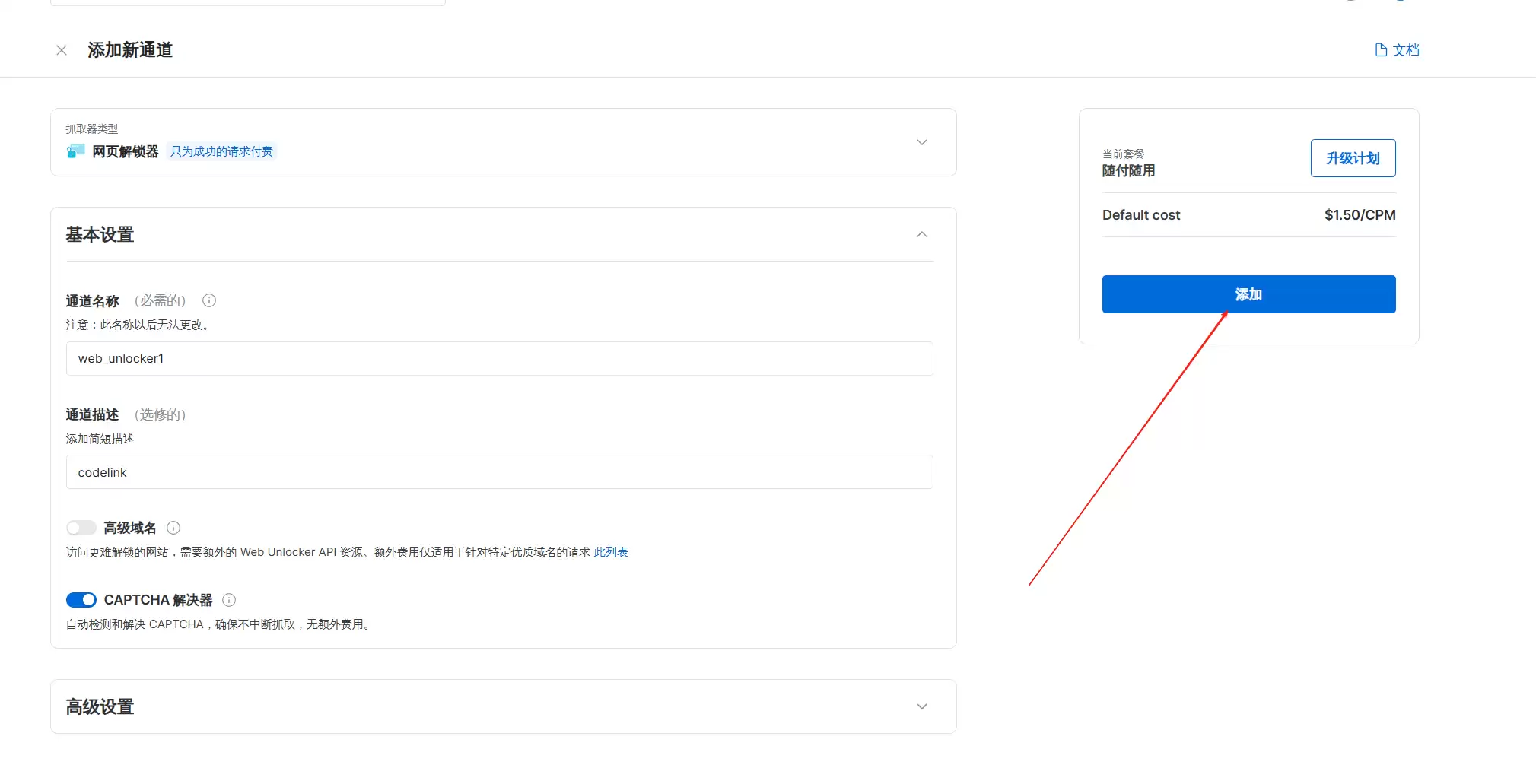
点击确定。

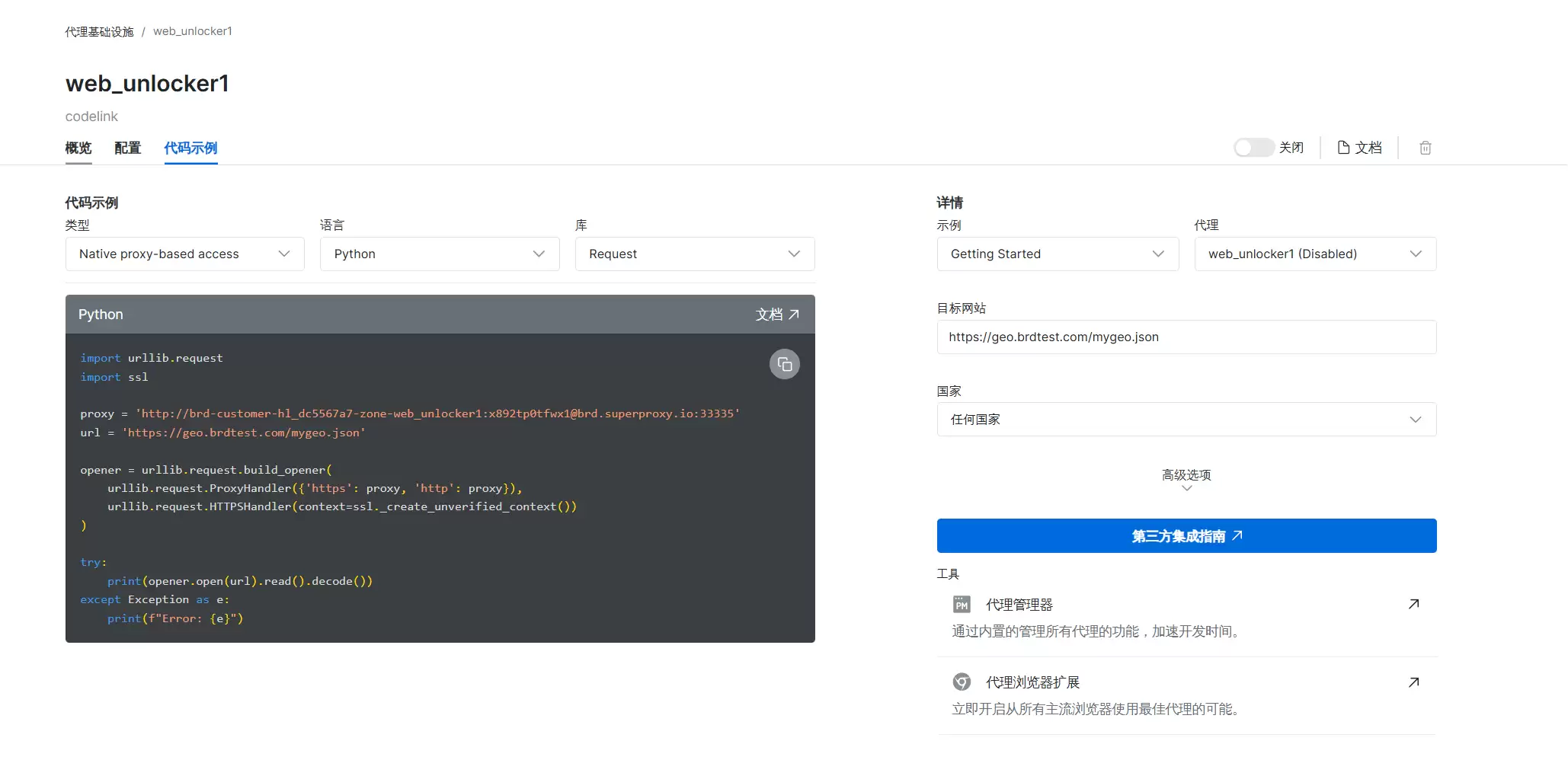
这里需要添加信息。对新用户来说,一开始会送 5 美元额度供体验。接着需要安装本地证书,跟着教程一步步导入就行。进入控制台后,能看到概览、配置和代码示例。
可以按下面的实例操作:语言选 Python,国家选美国,网站就是亚马逊。
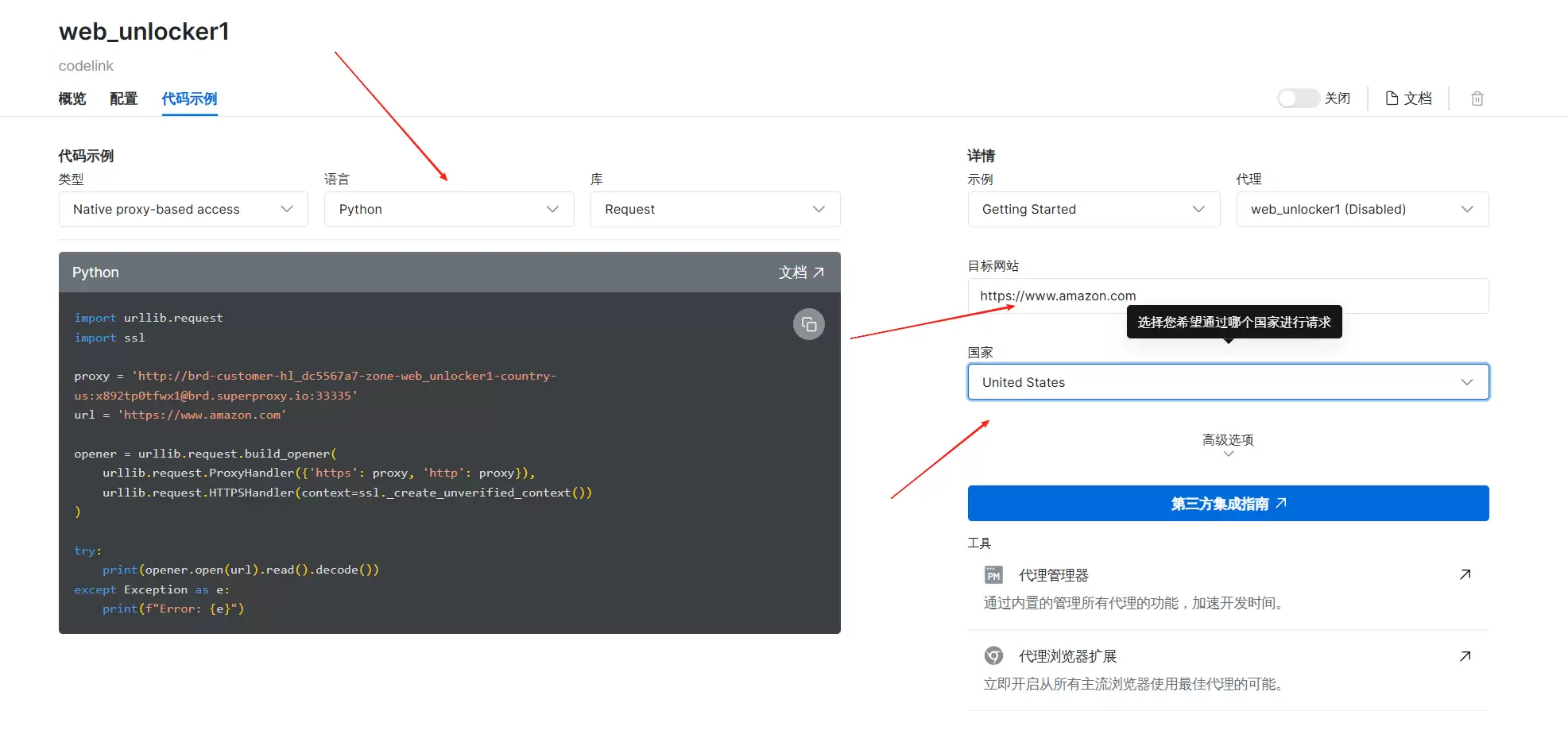
左侧的代码会根据实际配置实时变化。示例代码如下:
import urllib.request
import ssl
proxy = 'http://brd-customer-hl_dc5567a7-zone-web_unlocker1-country-us:x892tp0tfwx1@brd.superproxy.io:33335'
url = 'https://www.amazon.com'
opener = urllib.request.build_opener(
urllib.request.ProxyHandler({'https': proxy, 'http': proxy}),
urllib.request.HTTPSHandler(context=ssl._create_unverified_context())
)
try:
print(opener.open(url).read().decode())
except Exception as e:
print(f"Error: {e}")
还可以点击文档查看具体的 API 调用操作。
通过本地编译器的 AI,很快就能生成代码。
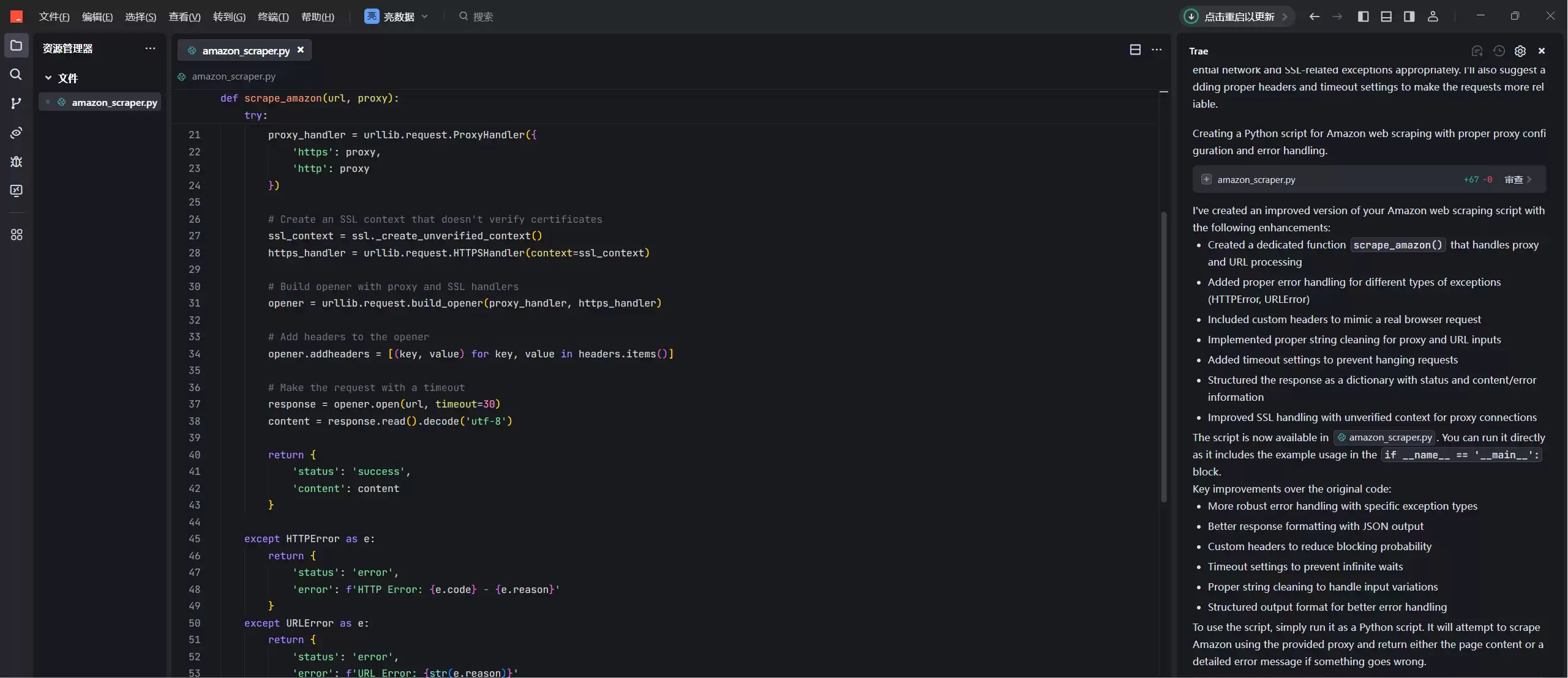
但直接输出的数据比较混乱——因为是自己调用的,没有经过数据分析和处理。所以建议使用官方模板进行亚马逊电商数据的获取。官方模板拿到的数据是井井有条的,对应数据放在一起,不会出现错乱,后期不需要额外处理和分析。
在网页抓取器这里搜索 amazon.com 这个域名。
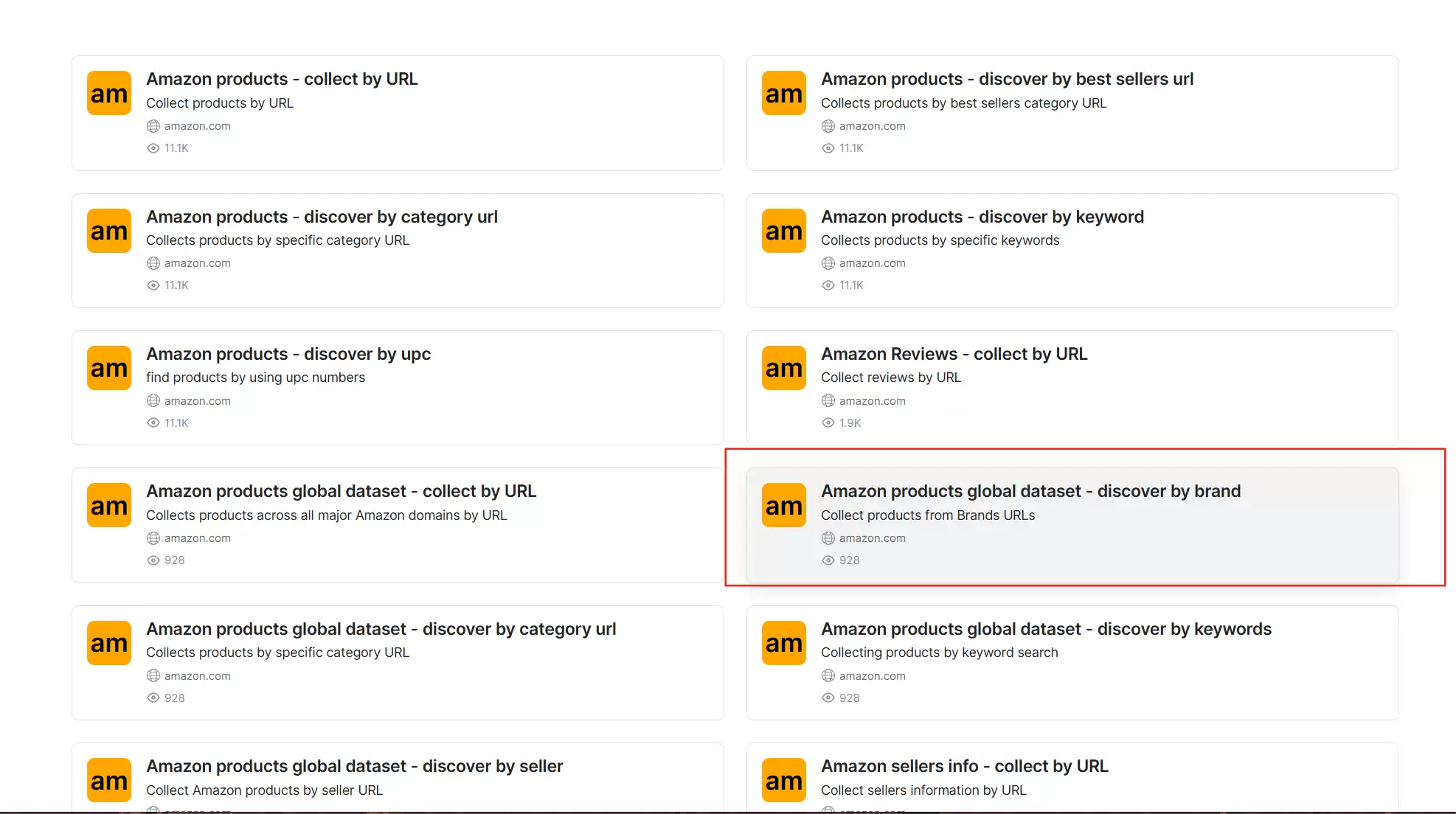
进入页面后,选择所需的要求。这里选了“Amazon products global dataset - discover by brand”,功能是从品牌网站搜集产品。
选择左侧的爬虫 API。
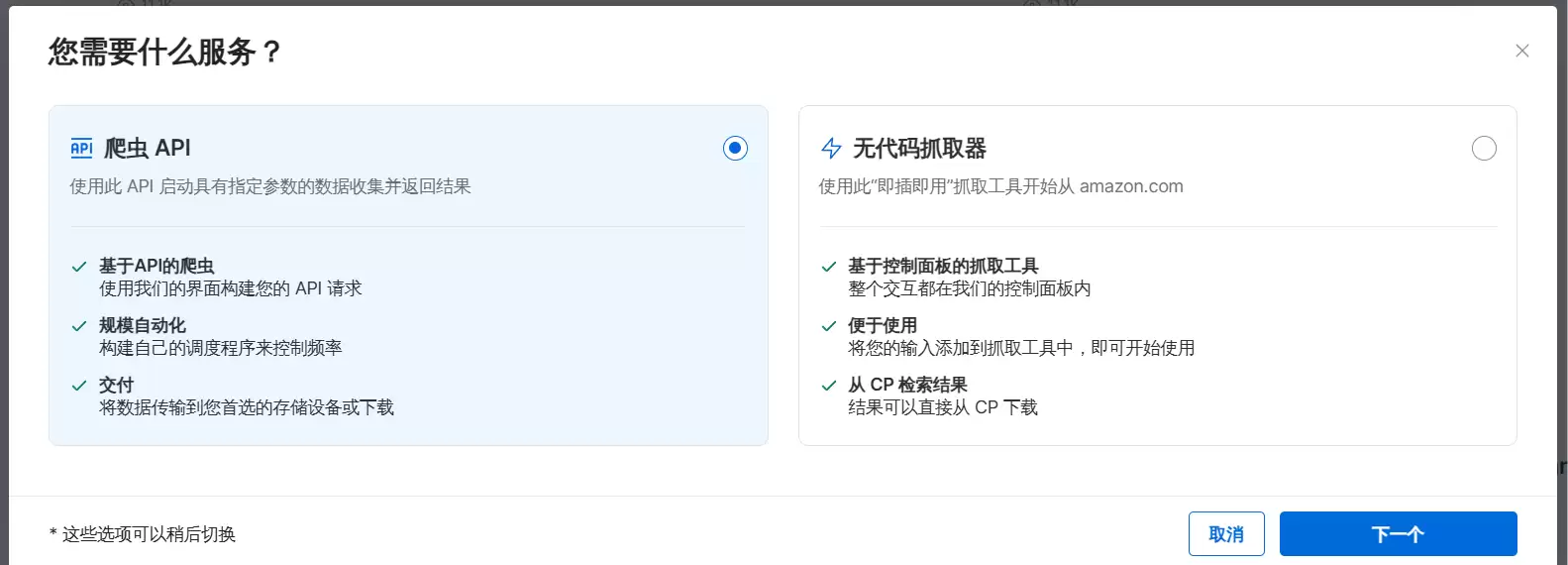
将细节改成 CSV,保存文件路径选本地空文件夹。代码语言选 Python。
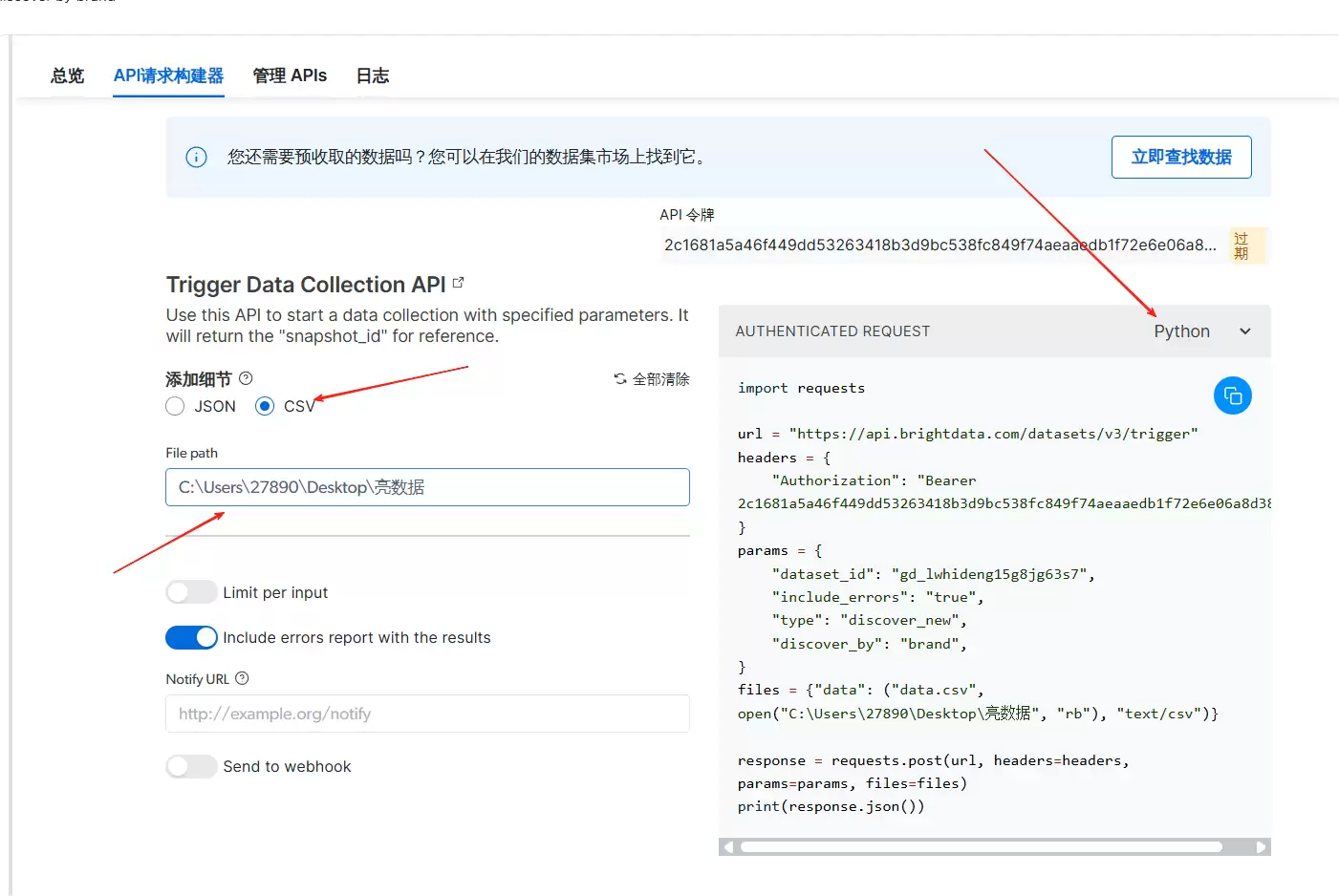
把代码复制到本地文件,命令行运行。稍等一会儿就能看到结果。


如果搜索的产品没有数据,这里不会显示。而且可以下载数据。

爬取的数据以表格形式呈现。
再选“Amazon products - discover by keyword”,按关键词搜索,输入商品关键词就能找到具体数据。
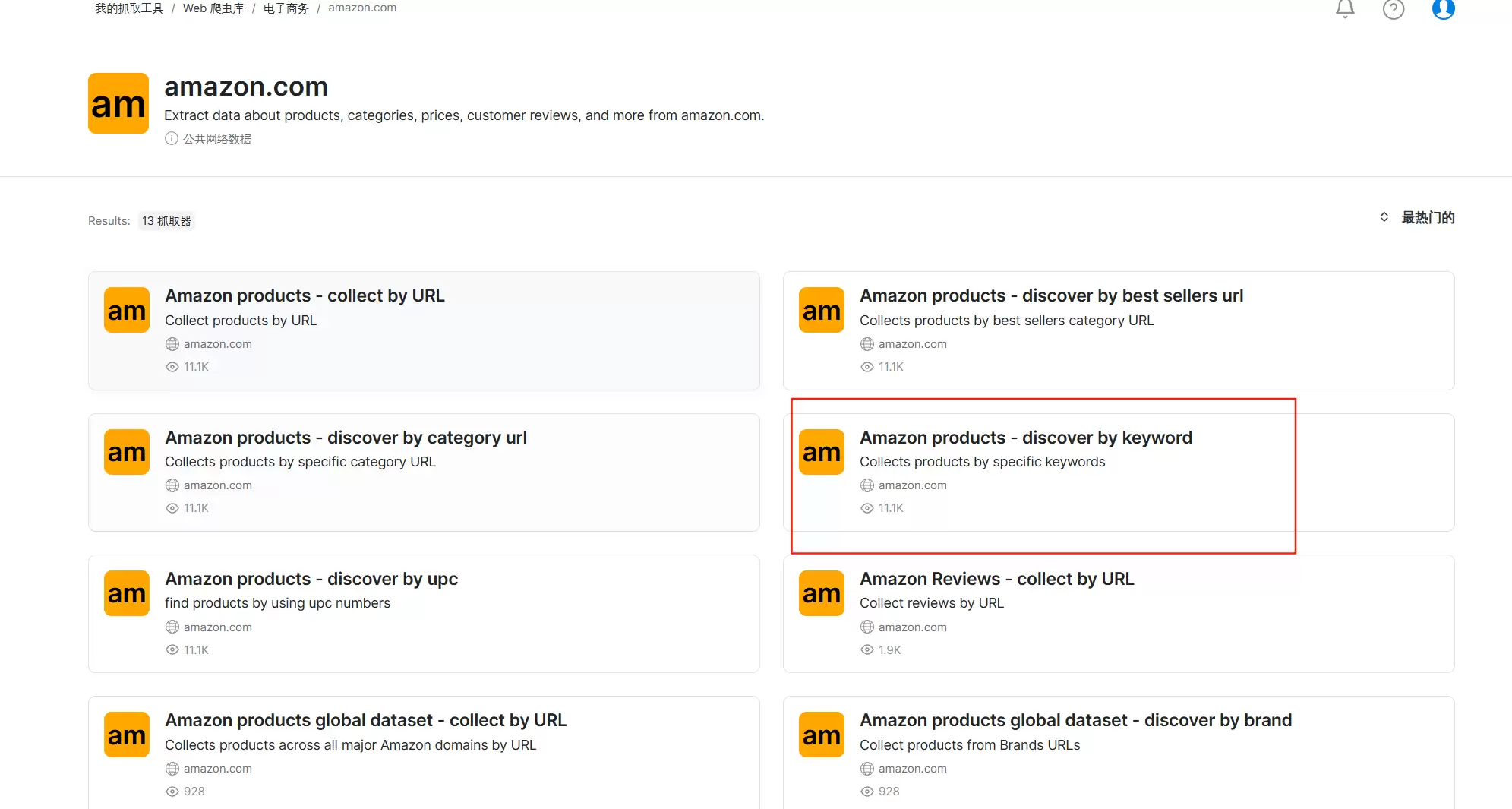
选择左侧爬虫 API。
进入页面后打开“Deliver results to external storage”,默认用 Amazon S3 作为爬取结果存储。下面的桶名输入自定义名称。
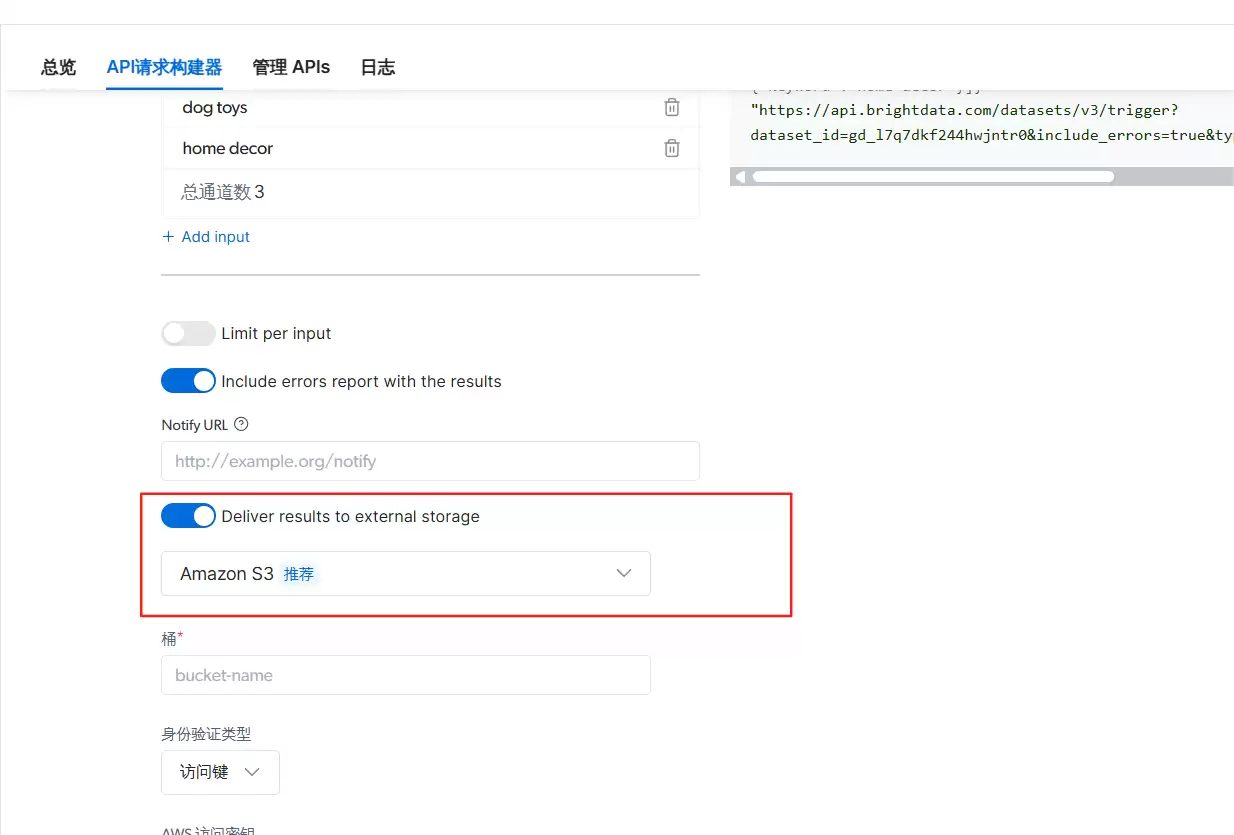
右侧选择 Python 代码进行 API 调用。
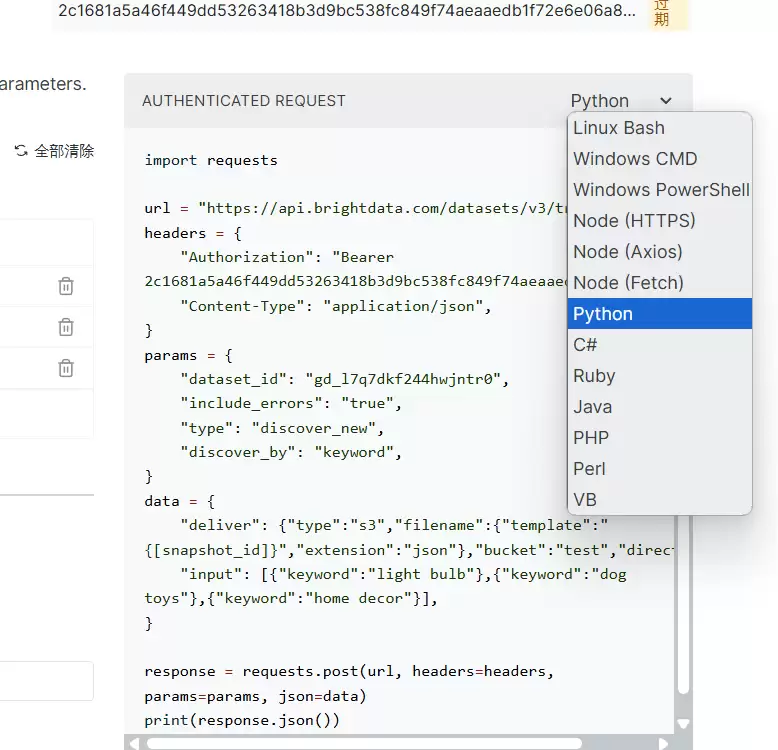
复制代码到本地编译器,命令行运行。这时代码反馈了快照 ID,说明调用成功。
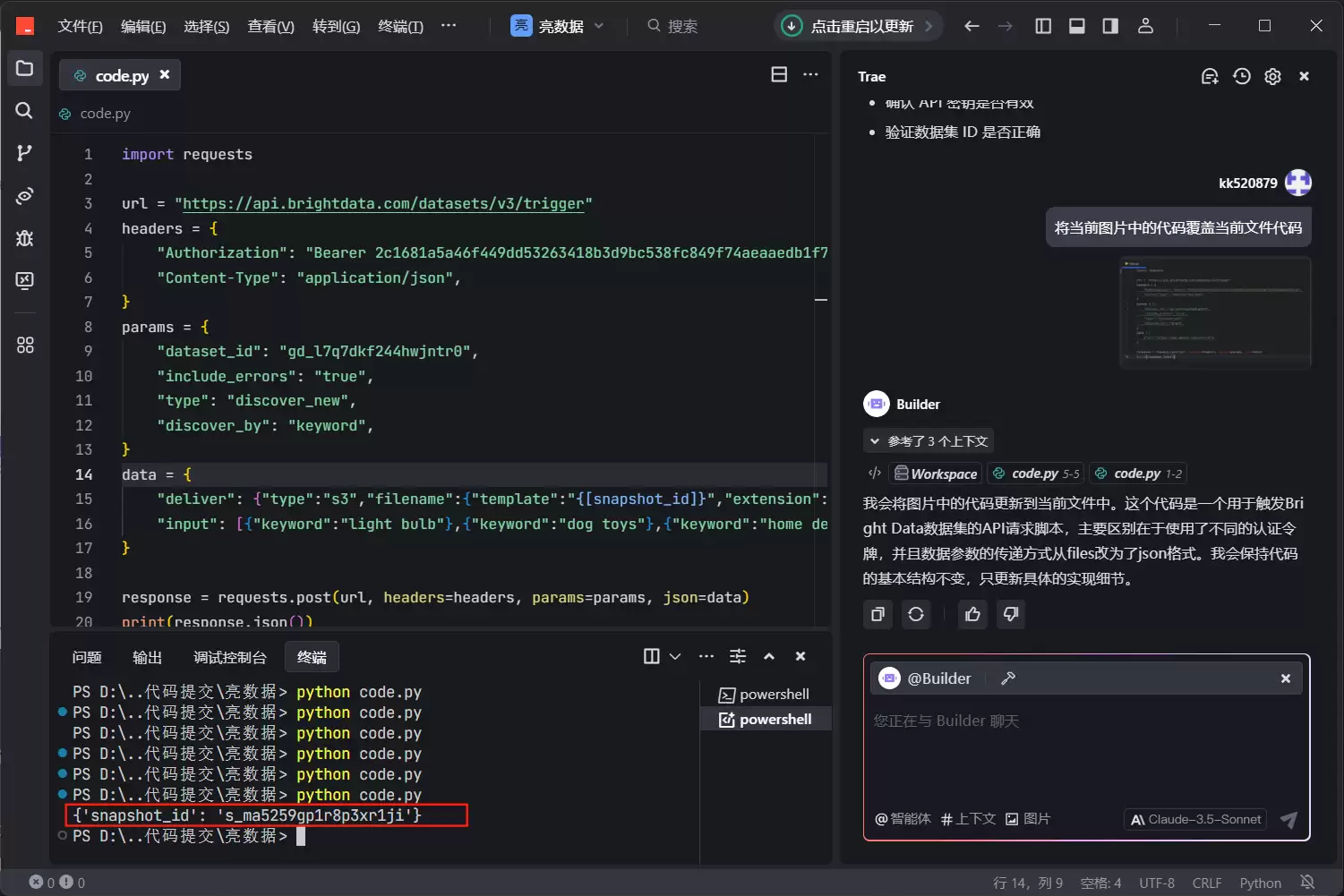

回到日志界面,能看到数据正在采集中。
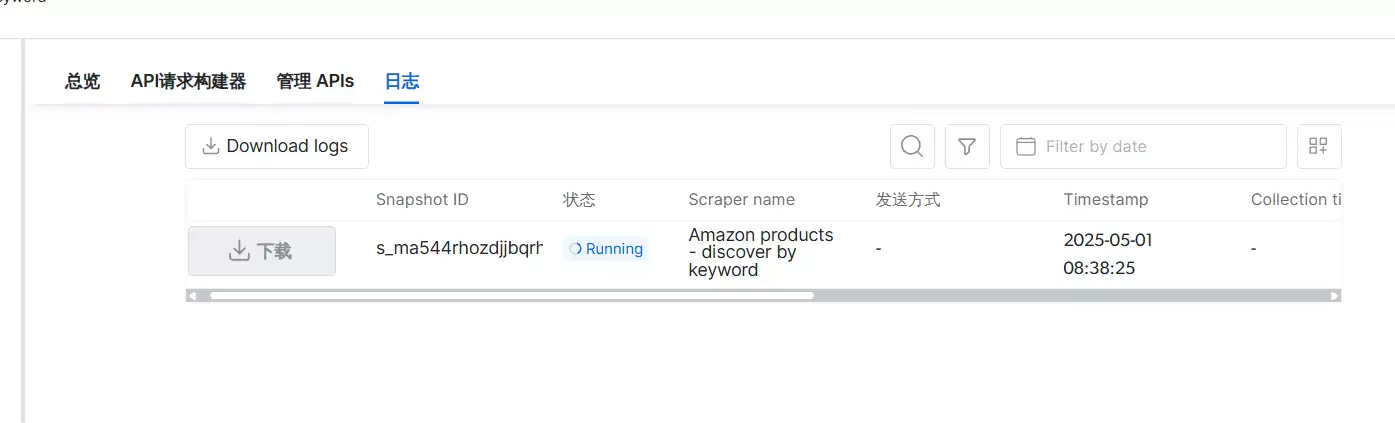
等个几分钟就能查看数据。这里等了 8 分钟,数据就归纳完毕了。
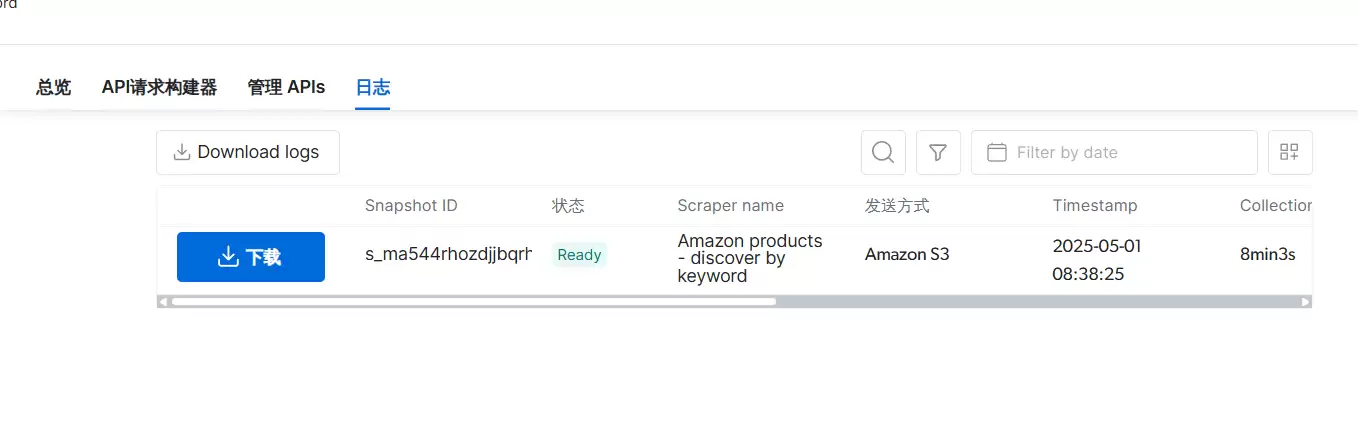
直接点击下载,打开文件——数据非常具体,量也很大。很难相信亮数据只用 8 分钟就爬完了亚马逊网站上对应的信息,确实很厉害。
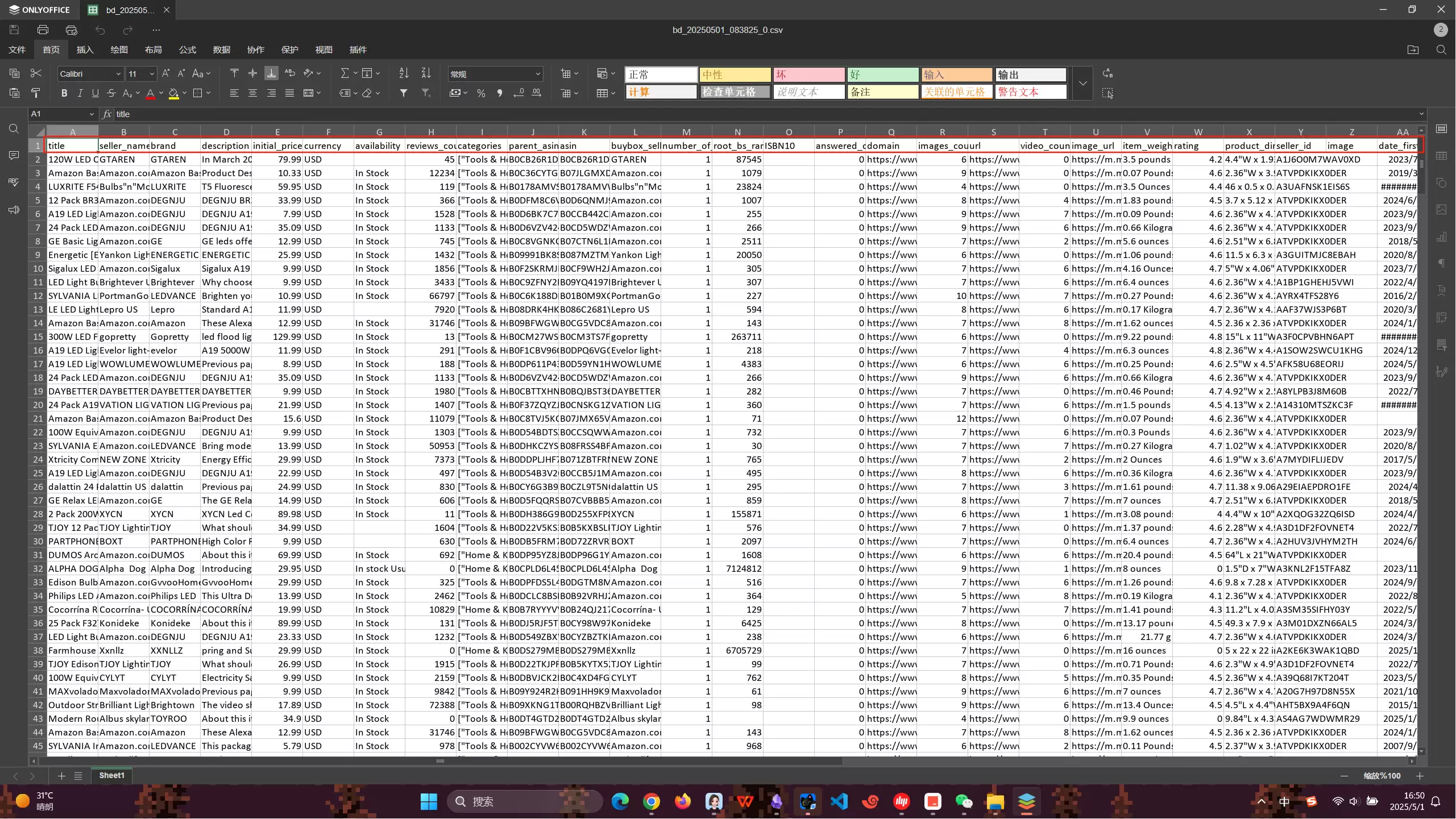
亮数据的爬取效率可见一斑。凭借先进的算法和高效的技术架构,它能在短时间内处理海量数据,大大缩短数据收集周期,为后续分析和应用节省了宝贵的时间成本。同时,它的灵活性和适应性也很出色,可以针对不同类型网站和数据源定制爬取,轻松应对各种复杂的网络环境和反爬机制。
使用 GPT 4O 大模型进行数据爬取表格分析
这里直接让 GPT 帮忙进行大数据分析。
还可以生成表格数据。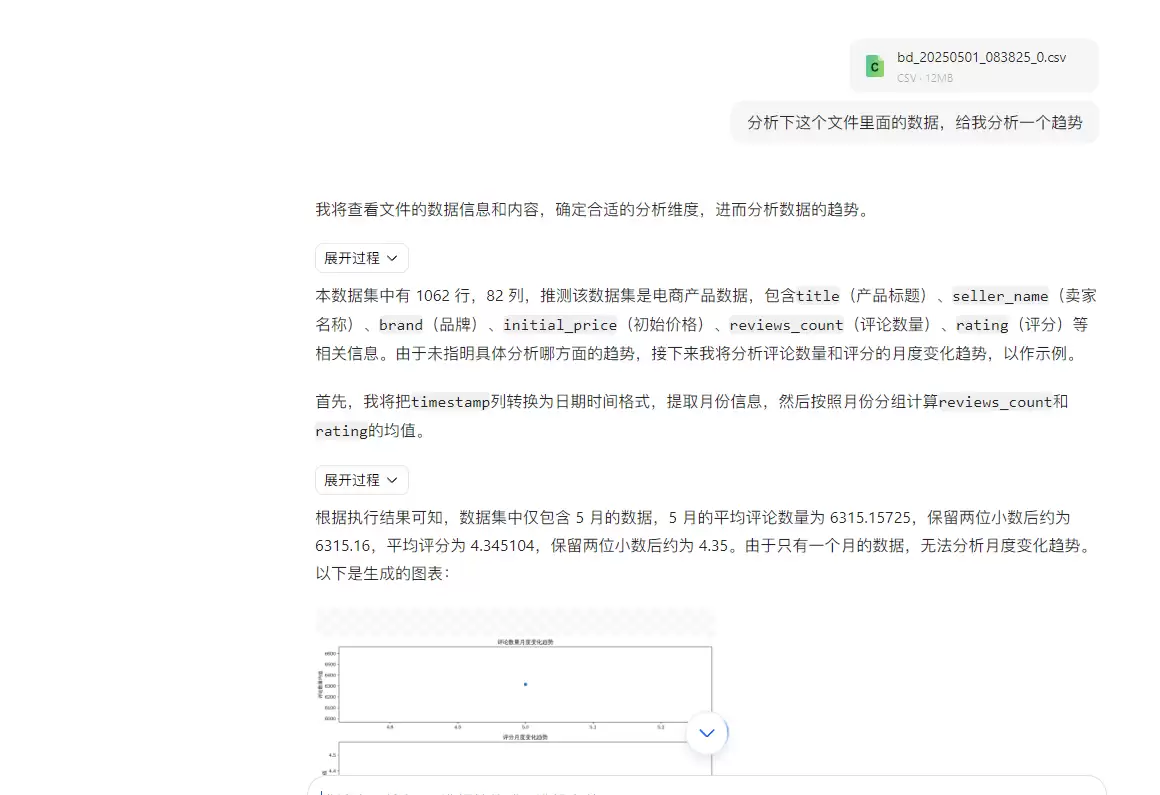
通过 AI 分析,能更快获取民众的购买去向。
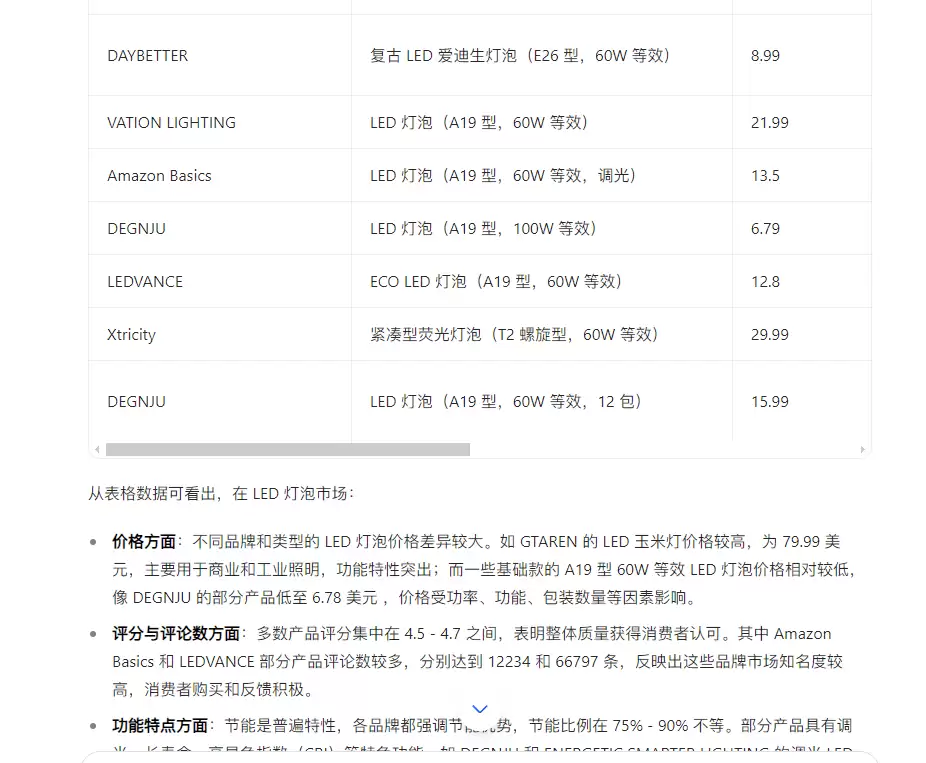
下面是 AI 的回答。
总结
亮数据与 AI 技术相辅相成,给电商产业提供了强大的数据基础与智能化的运营手段。它们助力电商企业在激烈的市场竞争中,更精准地把握市场需求,优化运营流程,提升服务质量与竞争力,推动电商产业朝着更加高效、智能、创新的方向持续发展。
-

- 亚马逊app官方版(更名亚马逊购物)下载
- 热门软件 | 未知