
微调框架Llama-factory和Unsloth:应该选择哪个?
大模型(比如GPT系列和Meta-Llama系列)在自然语言处理上的表现确实惊艳,但要说真正把它们的潜力“榨”出来,光有模型本身可不够。还得靠一些精细化的策略才行。提示词工程、微调(Fine-tuning)和RAG增强检索,就是目前最核心的三板斧。
提示词工程
RAG增强检索
微调
今天,我们就重点聊聊
微调框架的选择
微调的重要性:解锁模型潜能
微调,本质上就是把一个已经“通才”的预训练模型,打磨成一个“专才”的过程。好比一个受过良好教育的学生,他已经有了扎实的基础知识,现在想学一门新技能,比如弹钢琴或者说法语。他不需要从小学一年级重新学起,只需要在原有的知识基础上,进行有针对性的强化训练就好了。
举个例子,一个预训练的语言模型,它理解文字、生成文本的能力都很强。但如果你想让它做“情感分析”,判断一段评论是“正面”“负面”还是“中性”,那就得微调。方法就是找来大量已经标注好情感的文本数据(比如“这部电影太好看了!”标注为“正面”),让模型反复学习,它就能逐渐掌握识别不同情感的“诀窍”,最终的分析准确率自然就上去了。
这么做的好处显而易见:
- 比起从头开始训练一个专用模型,微调需要的训练数据和计算资源都少得多。开发周期能大幅缩短。
省时省力:
- 它能显著提升模型在特定任务上的性能和准确率,让通用模型落地到具体场景。
效果拔群:
所以,想把大模型用到实际业务中,微调是个绕不开的、非常重要的环节。
如何选择大模型微调框架
市面上的微调框架不少,但最主流、讨论度最高的,还得数
LLaMA-Factory
Unsloth
LLaMA-Factory
这个框架的优势在于“全面”。它支持市面上几乎所有主流模型,像LLaMA、LLaVA、Mistral、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi等等,全都能覆盖。社区生态非常活跃,想找学习资料和入门教程,随便一搜就是一大堆。
而且,它提供两种操作方式:一种是基于图形的WEB界面,像下图这样,你点点鼠标就能配置;另一种是命令行。选择很灵活。对于使用者来说,主要的精力可以放在研究参数、调整策略上。
Unsloth
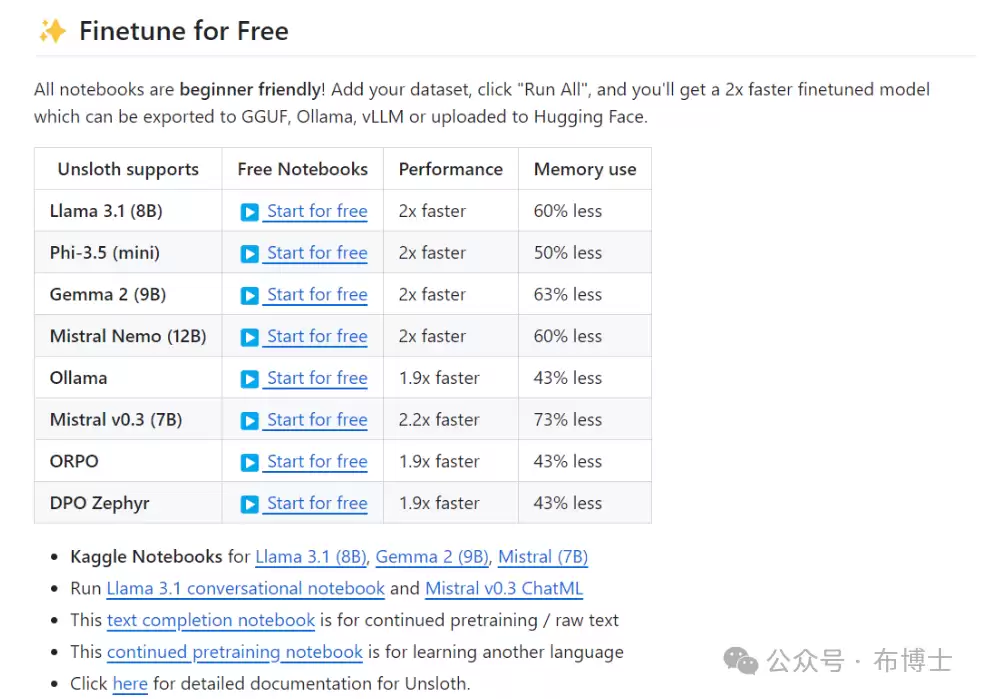
如果说LLaMA-Factory是“全面手”,那Unsloth就是“速度狂魔”。它的设计目标非常明确:让微调变得极其简单,且快得惊人。这个框架非常友好,即便你对算法没有太深的了解,只要懂一点大模型基础,就能用它轻松上手,微调主流模型。
它同样支持绝大多数主流模型。在Hugging Face上搜“Unsloth”,你会发现对Llama、Mistral以及很多国内大模型的支持都非常完善。社区支持也很充足。
LLAMA-FACTORY vs. UNSLOTH: 微调速度的对比
光说理论不够,实际跑一下数据才最有说服力。为了验证二者的速度差异,我最近用一个翻译任务做了测试:把现代汉语翻译成古文。数据集是经过处理的古文与现代文对照表,大约有1140万条记录。数据样例如下:
[{"instruction": "请把现代汉语翻译成古文","input": "世界及其所产生的一切现象,都是来源于物质。","output": "天地与其所产焉,物也。"},{"instruction": "请把现代汉语翻译成古文","input": "以概念来称谓事物而不超过事物的实际范围,只是概念的外延。","output": "物以物其所物而不过焉,实也。"}]
实测结果对比:
由于计算资源有限(只用了一张4090),测试做了对比:
微调设置:
- 使用约2万条数据,微调步长2940。
Llama-factory:
- 使用约45万条数据(考虑到它对GPU加速的支持),微调步长3000。
Unsloth:
耗时对比:
- 预测时间3.5小时,实际运行时间5小时。
Llama-factory:
- 预测时间约37分钟,实际运行时间约37分钟。
Unsloth:

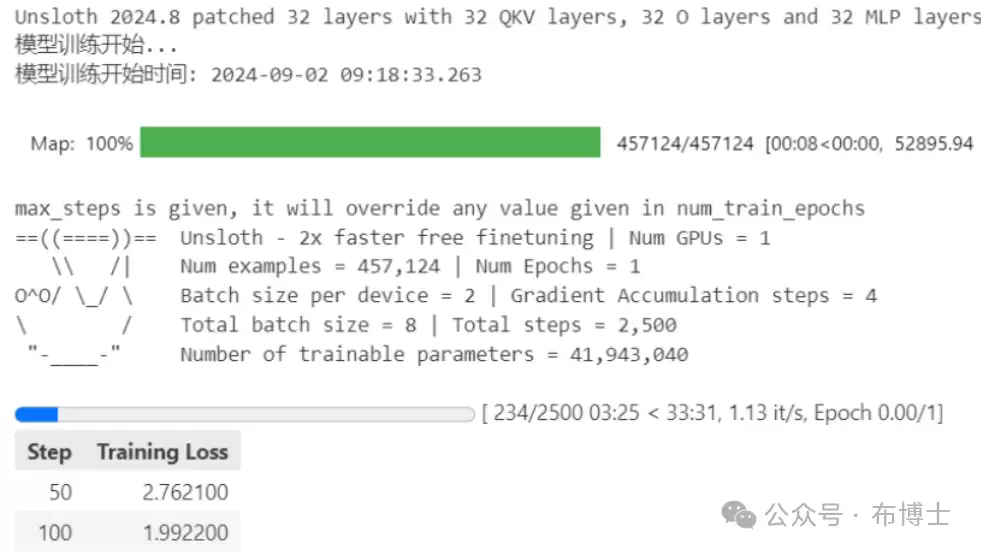
结果非常直观:即便Unsloth处理的数据量是LLaMA-Factory的20倍以上(45万条 vs 2万条),它的实际耗时却只有37分钟,比后者(5小时)快了大约10倍!而且它预测时间和实际时间几乎完全一致,这说明它对GPU的加速效果非常出色,资源利用率极高。
总结
从测试结果来看,LLaMA-Factory和Unsloth在社区支持、模型兼容性和易用性上旗鼓相当。但如果你对
