
重磅!MiniMax_M3_即将发布:稀疏注意力架构突破,百万_Token_上下文效率暴增
国内AI领域即将迎来一个重要节点。据最新消息,MiniMax即将正式发布其全新一代大模型M3。近日,MiniMax AI工程负责人Skyler Miao在社交平台低调预告,一句“Something BIG is coming!”,迅速点燃了整个行业的期待。
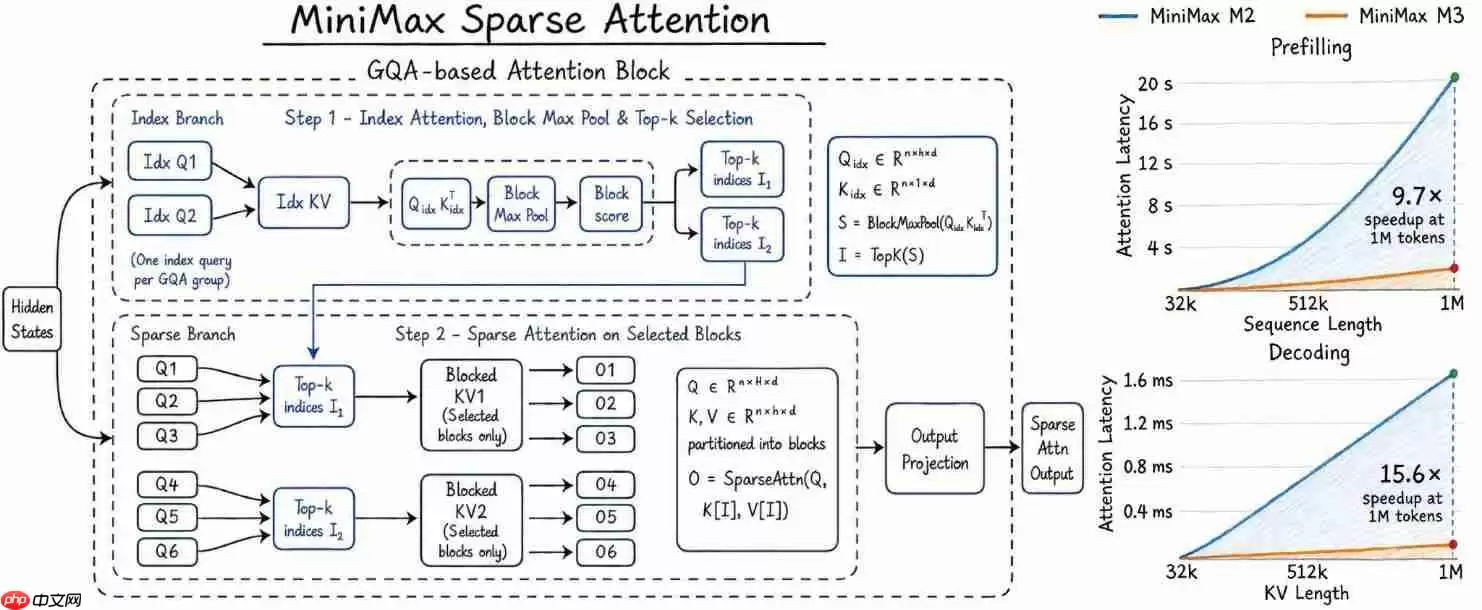
M3核心架构创新:稀疏注意力机制
多方信息证实,
M3将首次集成自研的稀疏注意力架构
要知道,在传统Transformer架构下,处理长序列的计算复杂度会呈平方级增长,这成了制约模型处理超长文本的“阿喀琉斯之踵”。而M3采用的这种结构化稀疏策略,能将关键计算压缩至近似线性规模。这意味着,在保持语义连贯性和推理准确率的前提下,模型对显存的占用和GPU的计算耗时都将大幅削减。这无疑为超长文档解析、跨会话深度对话、多源信息融合等高阶任务,提供了一个更坚实、更高效的底层支撑。
实测性能对比M2:推理效率实现阶跃式跃升
性能提升是硬道理。根据内部基准测试,相较于前代旗舰模型M2(原生支持100万Token上下文),M3展现出了碘伏性的效率提升:
Prefill阶段吞吐量提升高达9.7倍
Decoding阶段单步延迟降低至原水平的1/15.6,相当于速度提升了15.6倍
这些数字背后,是实实在在的商业价值。同等硬件条件下,M3能支撑更密集的并发请求;而在相同的服务等级协议约束下,企业则有望显著减少服务器集群的规模。这直接指向了云推理成本的下降,将加速AI能力向更广泛的中小企业及终端应用场景规模化渗透。
行业意义:定义长上下文时代的“高效智能”新范式
MiniMax此次通过架构创新而非单纯堆叠参数来推进M3,释放了一个清晰的信号:国产大模型的研发重心,正从追求“大而全”转向锻造“精而强”。稀疏注意力这类底层技术的突破,刷新的不仅是长文本处理的能效比天花板,更在推动一个行业共识的形成——
未来的核心竞争力,越来越取决于单位算力所能释放出的实用智能密度
这一转向至关重要。它意味着先进AI技术的接入门槛将被切实降低,从而真正加速千行百业智能化改造的纵深落地。目前,MiniMax官方尚未公布M3的确切发布日期和完整技术规格,但结合工程团队的预告节奏、实测数据的强度,以及近期一系列产业动态,业界普遍预期其将在2026年第二季度末至第三季度初正式亮相。这场由架构革新驱动的效率革命,值得我们持续关注。
