
大厂HR不敢说的秘密:2026校招技术简历上这3个词,看到直接扔
上个月帮公司筛校招简历,200多份技术岗,三个小时刷掉了160份。
这真不是HR手狠,而是简历上的用词太统一了,统一得像从同一个AI提示词里批量生成的。跟HR同事聊起这个现象,她苦笑着说:何止是学生,社招也一样。有些词现在只要出现在简历上,我们基本就不往下看了。
事实是,2026年的技术招聘,简历筛选的底层规则已经悄然改变。问题不在于HR变得更挑剔,而在于某些词汇本身已经彻底失去了信息价值。当一个词被所有人写在简历上时,它就不再是加分项,反而成了减分项。
一、哪些词正在成为简历毒药
过去三个月,结合内部几个技术招聘群的讨论和一份公开的招聘调研数据(某招聘平台2026年4月发布的《技术简历关键词有效性报告》),有三个词的“被嫌弃率”最高,都超过了75%。
第一个词:熟练掌握。
第二个词:负责。
第三个词:全栈。
这三类词的问题高度一致:它们都是“不可证伪”的陈述。你说什么我都无法反驳,但我也无法相信。
二、本质不是词的问题,是信息密度的问题
很多人以为简历被刷是因为能力不够。其实不全是。更常见的原因是:你提供的信息密度太低,HR在30秒内无法建立对你的能力画像。
要知道,HR筛简历时,每一份简历的实际停留时间大约只有15到30秒。这不是HR不认真,而是工作量决定的。大厂一个校招季收两万份简历,就算20个人筛,每人每天也要看几百份。30秒已经算是仁慈了。
在这宝贵的30秒内,HR在找什么?不是在找“优秀”,而是在找
确定性
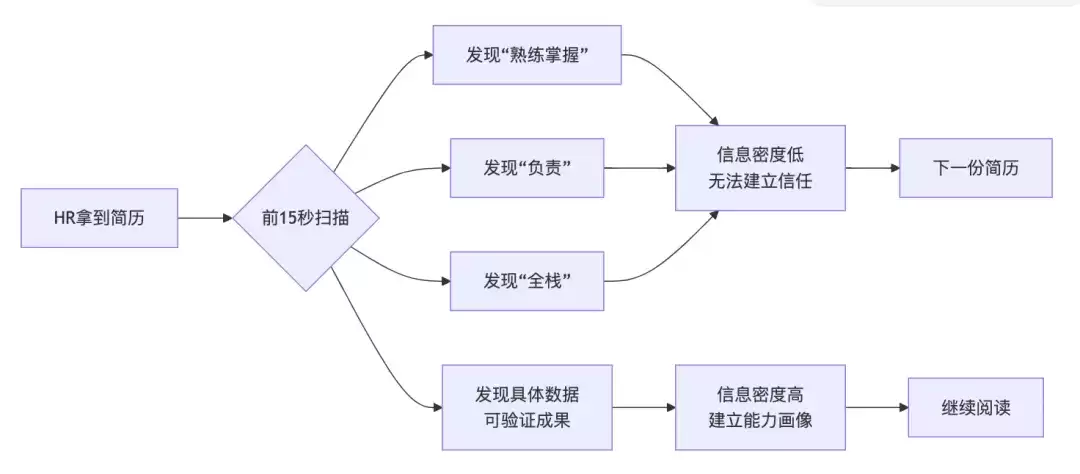
上面这张流程图清晰地解释了简历被扔和没被扔的分水岭:关键不是你
有没有
本质上,简历筛选是一个信息压缩与解压缩的过程。你把几年的经历压缩成两页纸,HR需要在几十秒内解压缩出你的能力模型。如果压缩算法用了太多冗余词汇,解压缩出来的就是一串毫无意义的噪声。
三、HR的简历筛选器到底怎么工作的
大厂HR筛简历并不是完全凭感觉。背后有一套隐性的评分模型,可以拆解为三层漏斗。
第一层:硬性过滤(约5秒)。
第二层:信息密度评估(约10秒)。
第三层:叙事一致性检查(约15秒)。
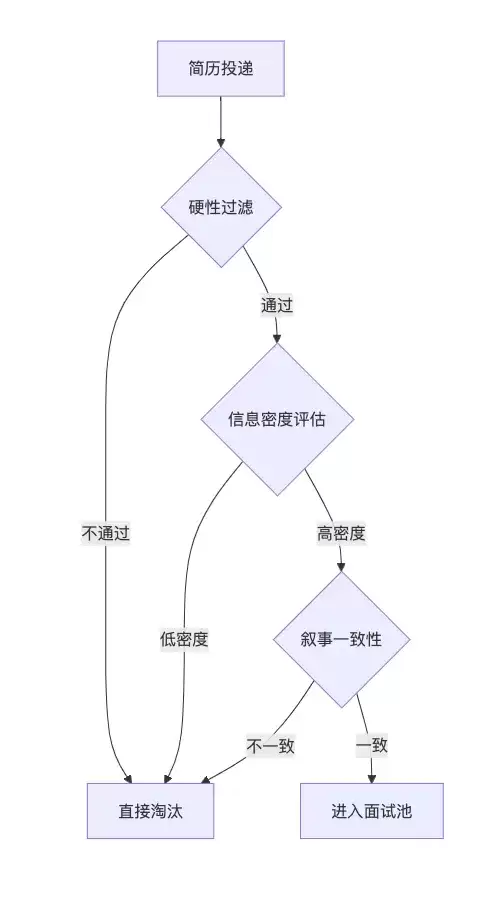
这三个层次里,最容易出问题的是第二层。很多技术不错的同学,写简历的时候用的是“代码注释思维”——写给自己看,或者写给懂上下文的人看。但HR没有你的上下文,他只能看你写出来的字。
四、两份简历的对比:一个被扔,一个被留下
用两个测试岗校招简历的真实改写案例来说明,区别一目了然。
改写前(被扔的那版):
“熟练掌握Python和Ja va,熟悉自动化测试框架。负责某电商项目的接口测试工作,编写测试用例,跟踪缺陷,保证项目质量。熟悉MySQL和Linux常用命令。”
这段文字的问题很明显:全是虚词。“熟练掌握”没法验证,“负责”没有结果,“保证项目质量”等于什么都没说。HR读完大概只知道:这个人做过测试。没了。
改写后(被留下的那版):
“实习期间独立维护某电商项目的接口自动化脚本(pytest+Allure)。将核心交易链路的用例覆盖率从45%提升到82%,发现并推动修复了7个潜在P0级缺陷。日常用Python处理测试数据,单次数据准备时间从1小时压缩到5分钟。”
区别在哪?每一句话都给了HR一个“可验证的证据”。覆盖率从45%到82%——你可以追问是怎么做到的。7个P0级缺陷——你可以追问是怎么发现的。1小时压缩到5分钟——你可以追问用了什么方法。这些追问点,就是面试官愿意继续聊下去的理由。
一句话总结:
简历不是岗位说明书,是你的能力证据清单。
五、怎么把自己写成“有信息量的简历”
首先,不要背模版。模版只会让你写出和别人一样的东西。建议用下面这个框架来组织你的每一个经历:
STAR-L框架
S (Situation) - 什么场景下做的
T (Task) - 你的任务是什么
A (Action) - 你具体做了什么技术动作
R (Result) - 可量化的结果是什么
L (Learning) - 你沉淀了什么方法论
测试岗的简历特别适合用这个框架,因为测试本身就是围绕“发现问题-解决问题-沉淀方法”来工作的。举一个例子:
S:
T:
A:
R:
L:
把每段经历都按这个结构写,你的简历就没有空间写“熟练掌握”这种废话了。
另外两个值得注意的细节:
细节一:动词的选用。
细节二:技术栈的展示方式。
六、一个你应该现在就去回答的问题
现在就拿一张纸,把你当前最拿得出手的一项技术工作写下来。然后问自己一个问题:
如果我把这段话给一个完全不了解我的人看,他能不能在20秒内判断出我到底做了什么、做出了什么结果、以及这件事有多大的难度?
如果你不敢肯定地回答“能”,那你的简历就需要重写。
最后一个问题不是问你的,是让你去问你的简历的:




