
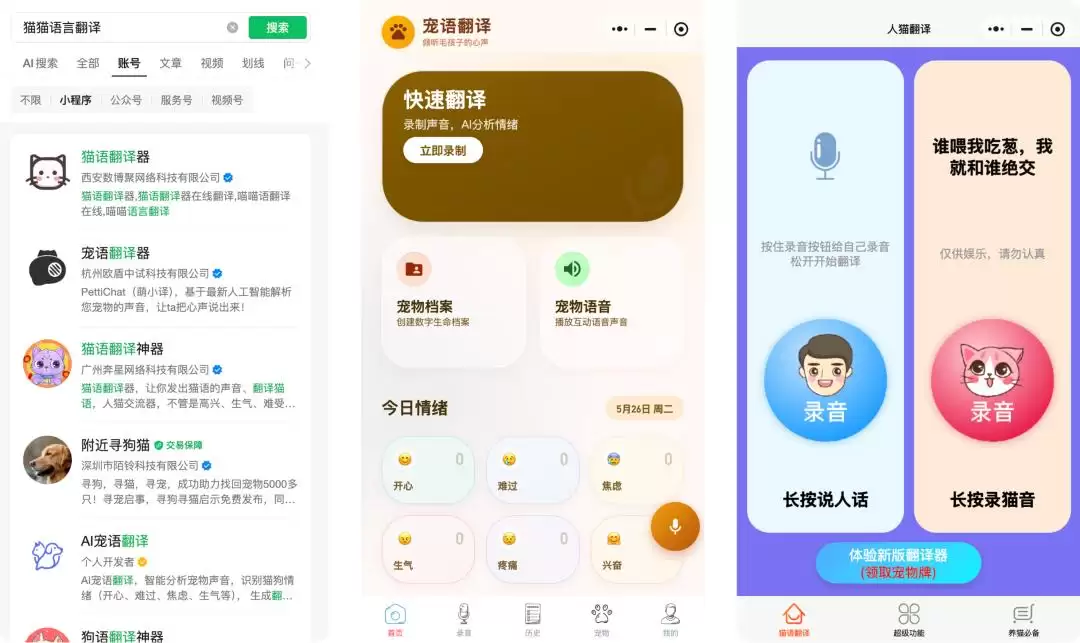
戴上800块的AI项圈,就能听懂喵星人的话?
哪个铲屎官没幻想过,能听懂自家毛孩子那几声“喵喵”或“汪汪”背后的真实想法?或者,能让它们真正理解我们的话?最近,杭州一家名为“萌小译”的公司,就把这个幻想包装成了一款售价约800元的产品——一款宣称能实现人宠双向翻译、且准确率高达94.6%的AI项圈。

它的工作原理听起来很直接:宠物佩戴的项圈负责收音和播放,配合手机App。项圈将宠物的叫声转换成文字显示在App对话框里;反过来,主人输入文字,项圈则会发出对应的“喵语”或“狗语”,试图让宠物理解。然而,这个构想一出来,就难免让人心里打鼓。毕竟,市面上打着“宠物翻译”旗号的小程序和应用比比皆是,有的干脆注明“仅供娱乐”,有的则用AI分析“情绪”,其科学性一直备受质疑。
问题的核心在于验证困难。我们无从得知猫狗的真实意图,翻译器大可用“我饿了”、“想出去玩”这类通用场景来应付,几乎永远“正确”。而将人话“翻译”成宠物语言后,宠物能否理解,同样难以证实。可就是这件如此“玄学”的事,如今竟有了一个高达94.6%的量化指标,这不禁让人好奇,这个数字究竟从何而来?

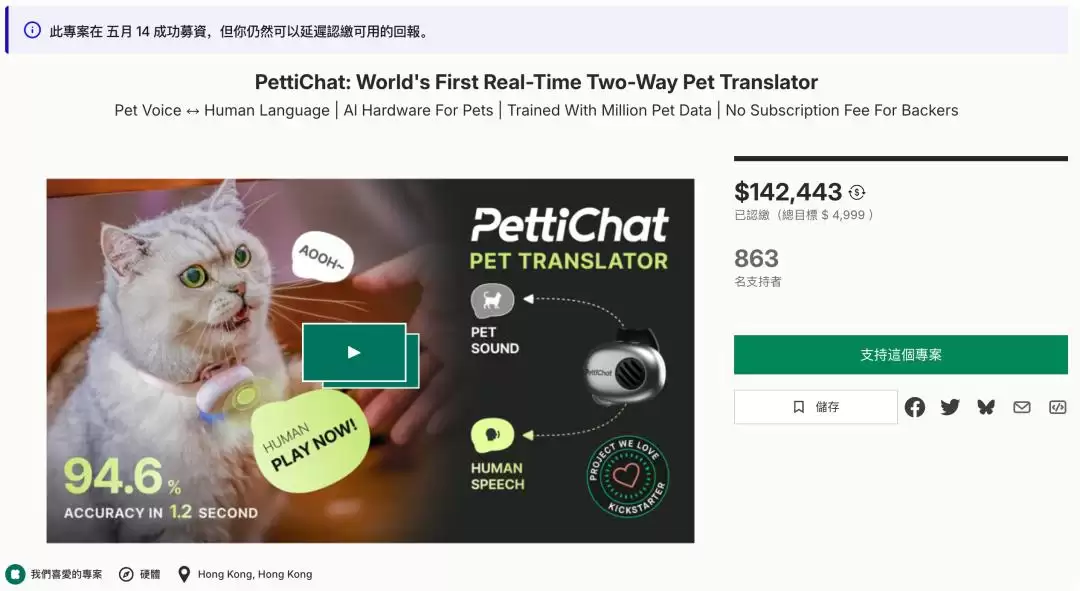
这款名为PettiChat的产品在海外平台X(原Twitter)上引发了热议,有网友一针见血地指出:“95%的准确率是基于你能核实他们所说的话的前提,而你根本无法核实。所以这纯粹是胡扯。”尽管争议不断,市场反响却颇为热烈。它在众筹平台Kickstarter上成功获得了863名支持者,筹集了约14万港币。众筹价119美元(约合软妹币800元),结束后零售价调整为149美元。
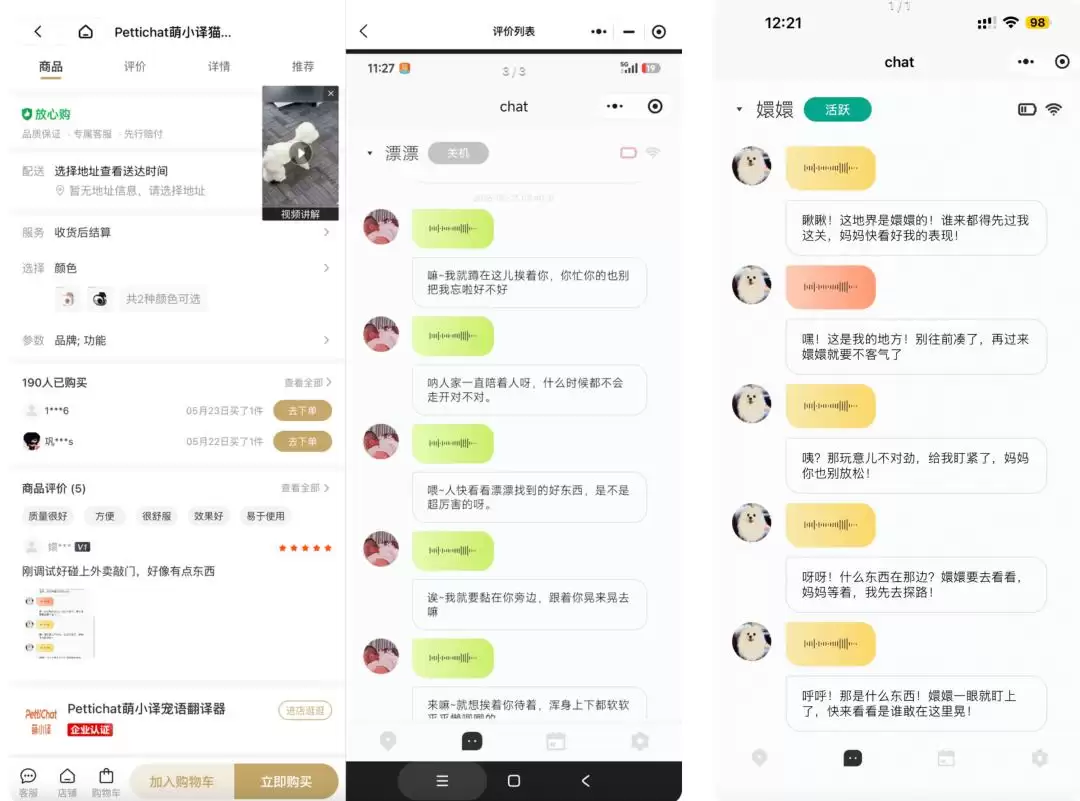
在其微信小店的预售页面上,显示已有190人购买。评论区有用户晒出“买家秀”,反馈“偶尔能听听毛孩子的想法很有意思”。从展示的翻译结果看,其“译”出的宠物语言充满了人性化色彩,不仅有“嘛~”、“呀呀”等语气词,甚至还有“不客气”、“别把我忘了”这类情绪饱满的句子。
这引出了一个根本问题:宠物真的能表达如此复杂的信息吗?PettiChat宣称的高准确率究竟如何衡量?这类产品,到底是通往理解的新桥梁,还是又一种精心包装的“智商税”?
一直被怀疑,一直在更新的宠物翻译设备
一直被怀疑,一直在更新的宠物翻译设备
宠物翻译这个概念并非新鲜事物。早在2002年,日本玩具公司Takara就推出过一款名为BowLingual的狗狗“情绪翻译”产品。它通过麦克风录音,将狗叫简单归类为“开心”、“焦虑”等几种情绪。虽然原理接近噱头,但它确实卖了出去,甚至还获得了“搞笑诺贝尔奖”,颁奖词戏称其“促进了人犬和平交流”。
二十年过去,随着AI和机器学习技术的发展,类似工具层出不穷。从各种小程序到独立应用,都试图通过分析声音模式为猫狗叫声打上标签。在今年初的CES展会上,也有公司推出了主打“人对狗”单向翻译的AI项圈。人类与宠物建立沟通的渴望似乎从未消退,技术演进反而让这种幻想显得越来越“可信”。
而这次PettiChat引发关注的关键在于,它比前辈们多做了一件事:拿出了一套看似严谨的测试数据来支撑其宣称的准确率。

从硬件看,这个重仅27克的项圈设备确实轻巧,宣称内置边缘计算芯片处理音频,延迟最低40毫秒,支持IP65防水,一次充电可进行1000次翻译和100小时GPS追踪。根据其众筹页面宣传,其声学模型基于超过150万条宠物叫声样本,并结合了动物行为学的同行评审研究。最终宣称,仅凭声音模式识别情绪状态的准确率达91-92%,加入姿态监测后,实验室综合准确率提升至94.6%。

500万+的宠物声纹数据与94.6%的真相
500万+的宠物声纹数据与94.6%的真相
要理解这个94.6%,得仔细审视其数据基础。众筹页面模糊的图表中提到了两篇关键论文。
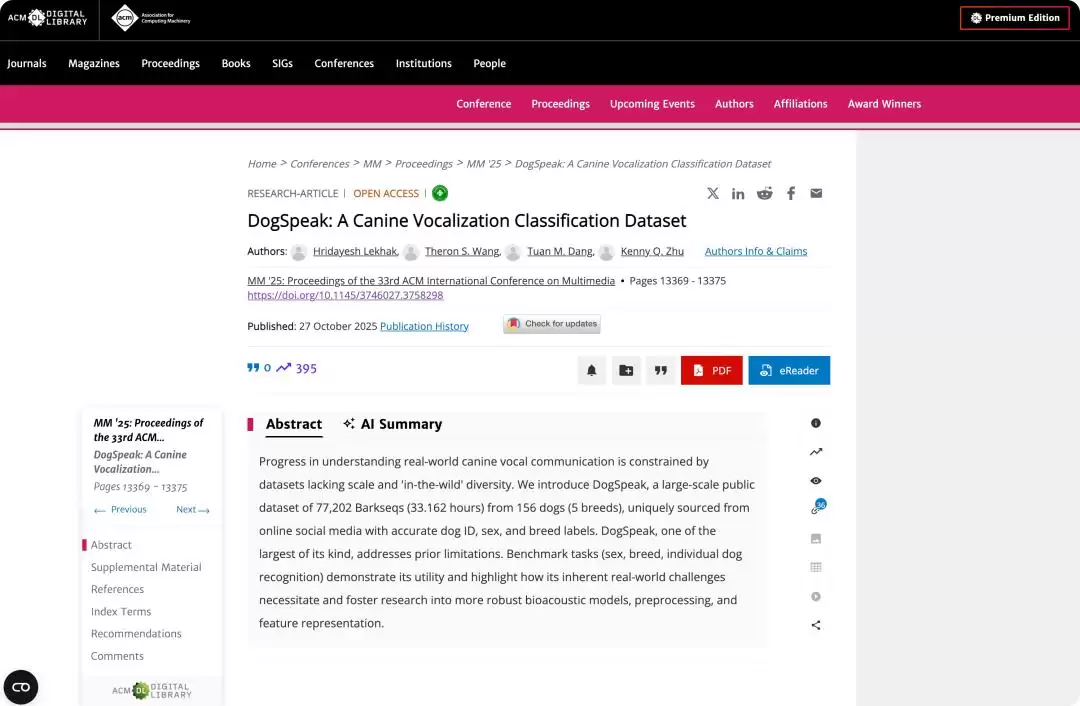
一篇是多媒体顶会MM 2025的《DogSpeak》论文,作者构建了一个大型狗叫声数据集,目标是通过叫声识别狗的性别、品种甚至个体身份。数据来源于社交媒体视频,最终包含156只狗、超过3.3万小时的纯狗叫声。值得注意的是,该研究明确指出,
仅靠“纯声学特征”很难完美解决真实复杂环境下的狗叫声识别

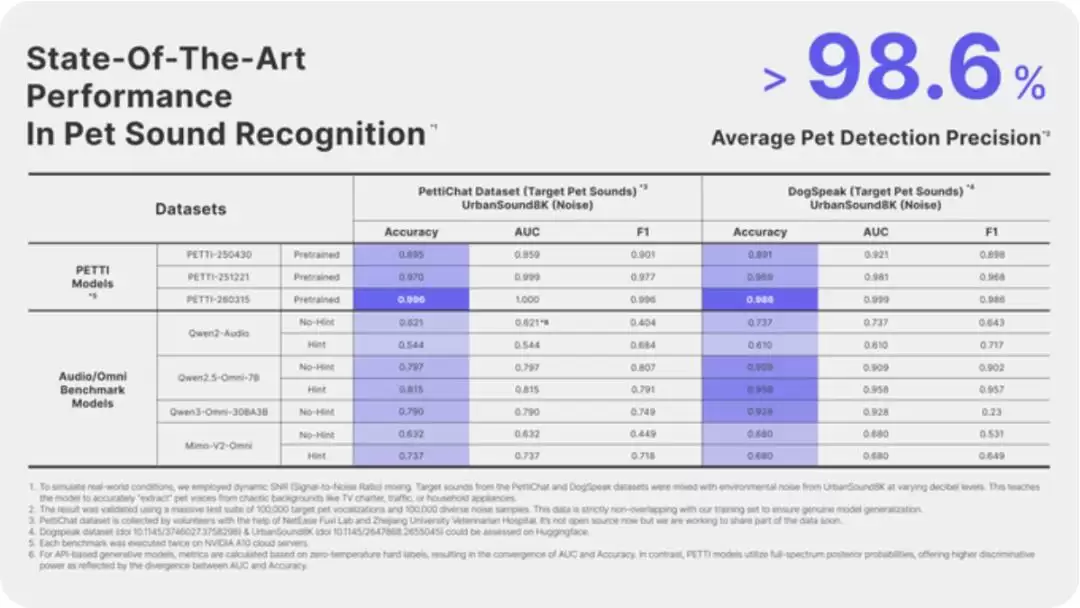
另一篇是MM 2014年的经典论文《UrbanSound8K》,主要贡献在于城市环境声音的分类数据集和方法。PettiChat宣称,其模型基于阿里云通义千问大模型,并联合浙江大学动物科学学院积累了超过500万条宠物声纹数据(约150万条标注),同时加入了UrbanSound的环境噪音数据以提升模型在真实环境中的鲁棒性。

那么,具体的测试是怎么做的?根据其描述,他们构建了一个大型独立测试集,其中包含叠加了电视声、车流声等背景噪音的宠物叫声样本,以及不含宠物声音的纯噪音样本。在这个测试集上,模型在“识别是否存在宠物声音”这一任务上,达到了平均98.6%的准确率。
请注意,这里测试的是“声音检测”,而非“语义翻译”。

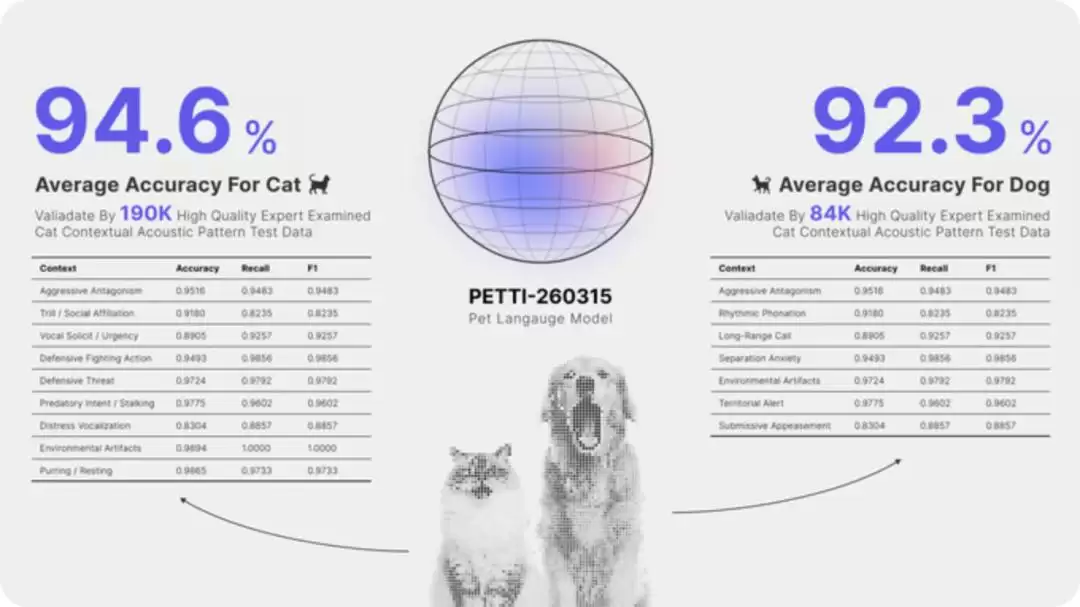
而重头戏,即那94.6%的准确率,则来自另一项“情境声音识别”测试。他们使用名为PETTI-260315的模型,在一个包含19万条猫叫和8.4万条狗叫的专家标注数据集上进行测试。这些声音被标注为“攻击/敌对”、“社交亲近”、“分离焦虑”、“领地警戒”等具体行为情境。测试结果显示,猫情境识别的平均准确率为94.6%,狗为92.3%。

这里的关键在于“Video Ground Truth”方法,即通过视频中宠物的行为、环境、姿态等视觉信息,来对齐和标注声音所对应的情境。例如,狗对着门口陌生人叫,声音就被标为“警戒/发现陌生人”;猫靠近食盆叫,则被标为“寻求食物”。
于是,真相浮出水面:
这94.6%实质上是“宠物声音情境分类准确率”,而非公众通常理解的“将一句宠物语言翻译乘人类句子的准确率”。
那么,从“行为标签”到我们看到的“拟人化翻译”,中间发生了什么?模型输出的原始结果可能只是一个“领地警戒”的标签,但在App中,它被渲染成了“有人来了,我要守住这里。”一段被识别为“急迫性请求”的猫叫,在对话框里则变成了“快看看我嘛,我有点着急。”这种从冷冰冰的学术标签到充满情感色彩的自然语言的“再加工”,正是产品变得有趣、亲切的关键,但也恰恰是94.6%这个数字无法覆盖的“模糊地带”。
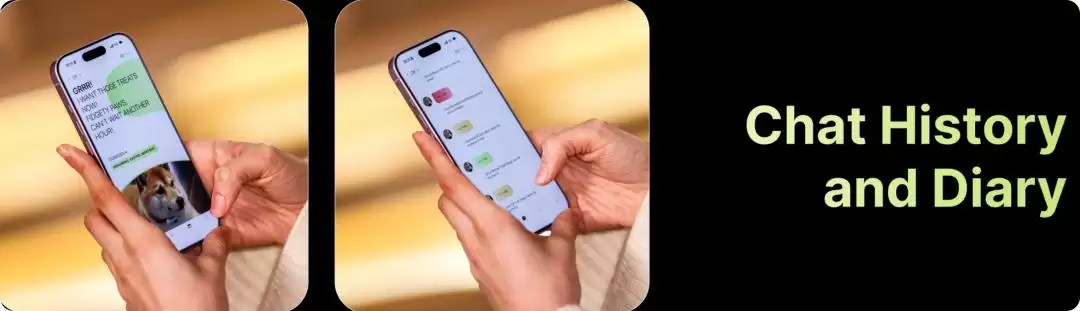
因为测试集中的标准答案,是“分离焦虑”这类行为标签,而非“别把我忘了”这样的句子。模型只需要判断声音更接近哪个标签,无需也无力证明宠物是否真的在想那句被翻译出来的话。
所以说,这类宠物翻译产品处在一个非常微妙的位置:它可能并非完全凭空捏造的“骗子”,其背后确实有基于大量数据的行为识别研究作为支撑;但它也远非我们想象中的、能实现跨物种精确对话的“翻译器”。它更像一个基于概率的行为推测器,加上了一层为了让人类用户感到亲切而精心设计的语言包装。对于消费者而言,理解这其中的区别,或许比纠结于那个诱人的百分比更为重要。
