
智能问数(Text2SQL)工业级落地,纯 AI 黑盒方案都没戏
如果你关注智能问数(Text2SQL)这个领域,可能会发现一个有趣的现象:相关的文章、演讲和视频层出不穷,许多厂商都宣称自己的方案准确率高达90%甚至95%。但当你真正想找一个公开的、可以直接上手测试的DEMO时,却会发现几乎无处可寻。
做一个DEMO的成本其实并不高,一个简单的网页加上后台API,对于任何技术团队来说都不是难事。那么,为什么公开的DEMO如此罕见?真正的原因在于,当前市面上绝大多数的Text2SQL技术,本质上都是“黑盒”方案。而黑盒方案,恰恰经不起用户的随意测试——AI模型随时可能给出一个离谱的错误答案,导致现场“翻车”。
这并非某个特定厂商的问题,而是所有纯粹依赖AI黑盒方案的共同困境。
黑盒方案的困境:不稳定的“90%”,企业承受不起
目前主流的Text2SQL方案,无论包装得多么华丽,其内核都可以归为两类黑盒模式。
早期的方案最为直接:用户输入一句话,大模型直接生成SQL语句。这种方式看似“纯粹”,但可控性也最差。模型幻觉、语法错误、表名混淆、JOIN关系错乱……你能想到的查询错误,它都可能犯。
后来,业界演进出了更复杂的方案:让AI先生成一个结构化的中间层(比如JSON或自定义的DSL),再由程序将这个中间层转换为SQL。相比直接生成SQL,中间层在一定程度上降低了复杂度,准确率也有所提升。过程中还可能引入RAG(检索增强生成)知识库等机制。
然而,无论提示词设计得多么精细,向量库构建得多么完善,最关键的那一步——从自然语言到结构化表示的转换——仍然是由AI完成的。只要AI的“幻觉”问题一天不解决,这个环节就永远无法做到100%可靠。现有的所有技术手段,都只能减少幻觉发生的概率,而无法从根本上根除它。
学术研究的数据已经敲响了警钟。在更贴近企业真实数据环境的Spider 2.0基准测试中,曾在Spider 1.0上达到86%准确率的GPT-4o,整体成功率骤降至6%;o1-preview模型更是从91.2%暴跌至21.3%。这其中的断崖式下跌,清晰地揭示了学术测试与企业真实需求之间的巨大鸿沟。
更严峻的是,连评估基准本身都可能靠不住。2026年1月的一项研究发现,BIRD Mini-Dev数据集的注释错误率高达52.8%,Spider 2.0-Snow的错误率也达到了62.8%。当基准数据都存在过半错误时,讨论模型的“准确率”本身就失去了稳固的根基。
问题的严重性远不止于数字上的差异。即便一个系统在90%的情况下都能输出正确的SQL,那剩下的10%错误也足以彻底摧毁企业对其的信任。当关键的业务决策依赖于数据查询结果时,“这次查询结果可能是错的”这种不确定性,本身就是不可接受的。
问题的根源在于执行链条的“黑盒”特性。用户输入一句话,得到一个结果,中间的推理过程完全不可见。大模型匹配了哪些表和字段?它为什么选择这样的JOIN路径?它理解的过滤条件是否与用户的真实意图一致?这一切都无法追溯和审计。当结果可疑时,技术人员或许还能把生成的SQL拿出来人工核对(尽管这也很费劲),但Text2SQL的目标用户往往是看不懂SQL的业务人员,给他们看生成的SQL语句也无济于事。中间层方案只是把SQL换成了JSON或DSL,业务人员同样看不懂。连问题出在哪里都搞不清楚,更谈不上指导系统改进了。
因此,黑盒方案的困境是结构性的:关键决策点依赖概率模型,输出结果不确定、无法审计、无法解释。而企业级应用所要求的稳定性、可重现性和可解释性,恰恰是黑盒方案无法提供的。
白盒方案的根本区别:把AI关进笼子,留出人类审核位
要解决黑盒问题,不能寄希望于AI突然变得完美无缺,而是要在系统设计层面就承认AI的局限性,并将其约束在一个可控的范围内。
白盒方案的核心原则有两条:
- 必须存在一个人类可读、可确认的中间层。AI只负责将自然语言翻译成这个中间层,之后必须经过人(或业务专家)的确认,才能进入下一步。
- 从中间层到SQL的转换,必须使用确定的规则进行编译,绝不能再次使用AI。这样才能保证后续环节100%准确。
这可以概括为“用自然语言对抗自然语言”——用一个人类能看懂的中介语言,将AI的不确定性阻挡在确认环节之前。一旦确认通过,后续就是纯规则的、确定性的编译过程,没有幻觉,也没有猜测。
润乾NLQ走的就是这条白盒路线。它的中间层被称为“规范文本”,是一种介于口语和SQL之间的结构化表达。例如:
- 用户口语:帮我查一下去年北京发往青岛的订单
- 规范文本:去年 北京 发往 青岛 订单
规范文本支持动词表达,上例的完整语义是“去年 发货 城市 北京 收货 城市 青岛 订单”。人眼一看就能理解其意图。用户确认“对,我就是这个意思”之后,系统再用规则引擎将规范文本确定性地编译成MQL,最终转换为SQL执行。从规范文本到SQL的整个后半段,准确率是100%的,不存在“这次对、下次错”的随机性。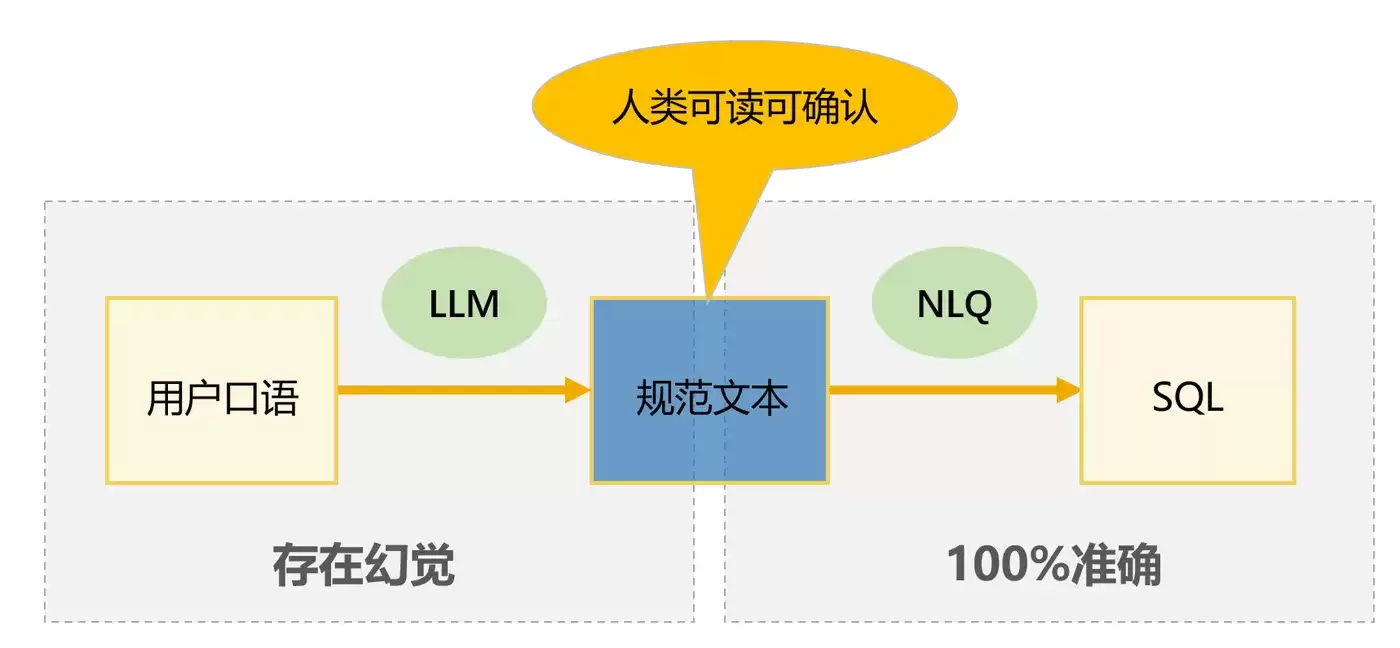
正因为有这样的确定性保障,润乾NLQ才敢于放出公开DEMO。它可能会遇到无法理解的问句而拒绝查询,但只要用户确认了规范文本,返回的结果就一定是正确的。即便程序偶有BUG导致出错,也可以追踪调试并解决,错误会越来越少。
例如,在DEMO中直接查询:
- 商品名称 ‘龙虾’ 且 库存量小于50 商品 编码 名称 单价
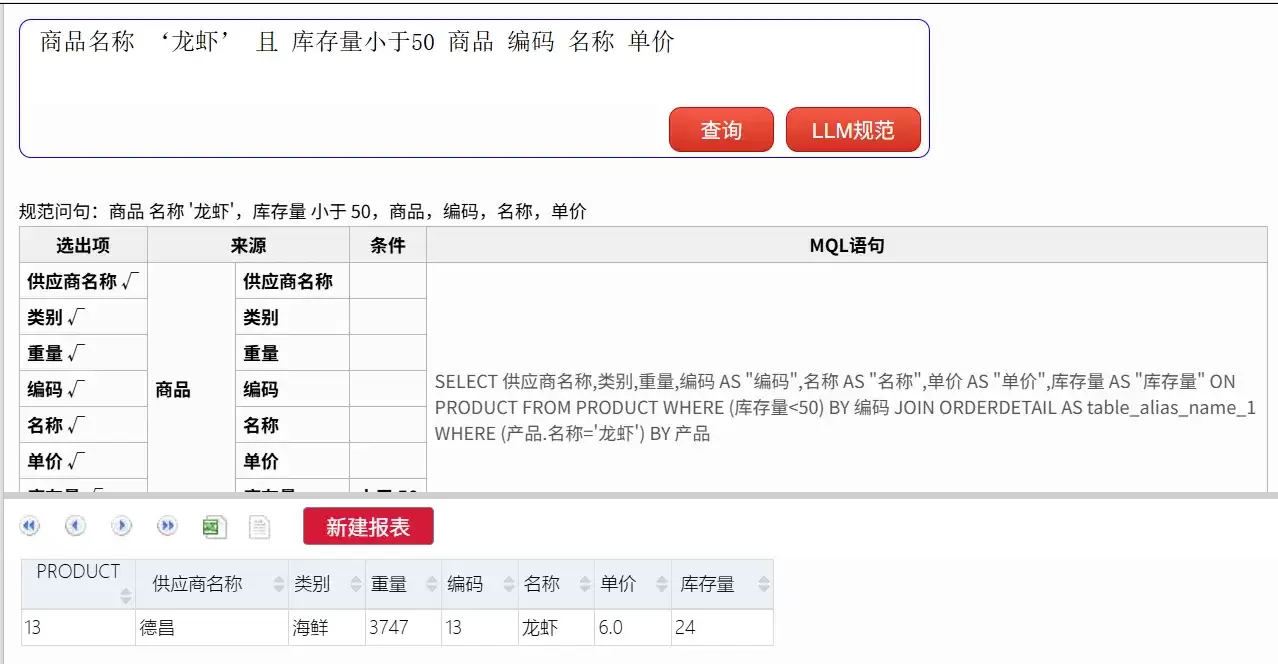
这个规范文本清晰地表达了包含多个过滤条件的明细查询。
再查询:
- 2025年 金额最大10 订单
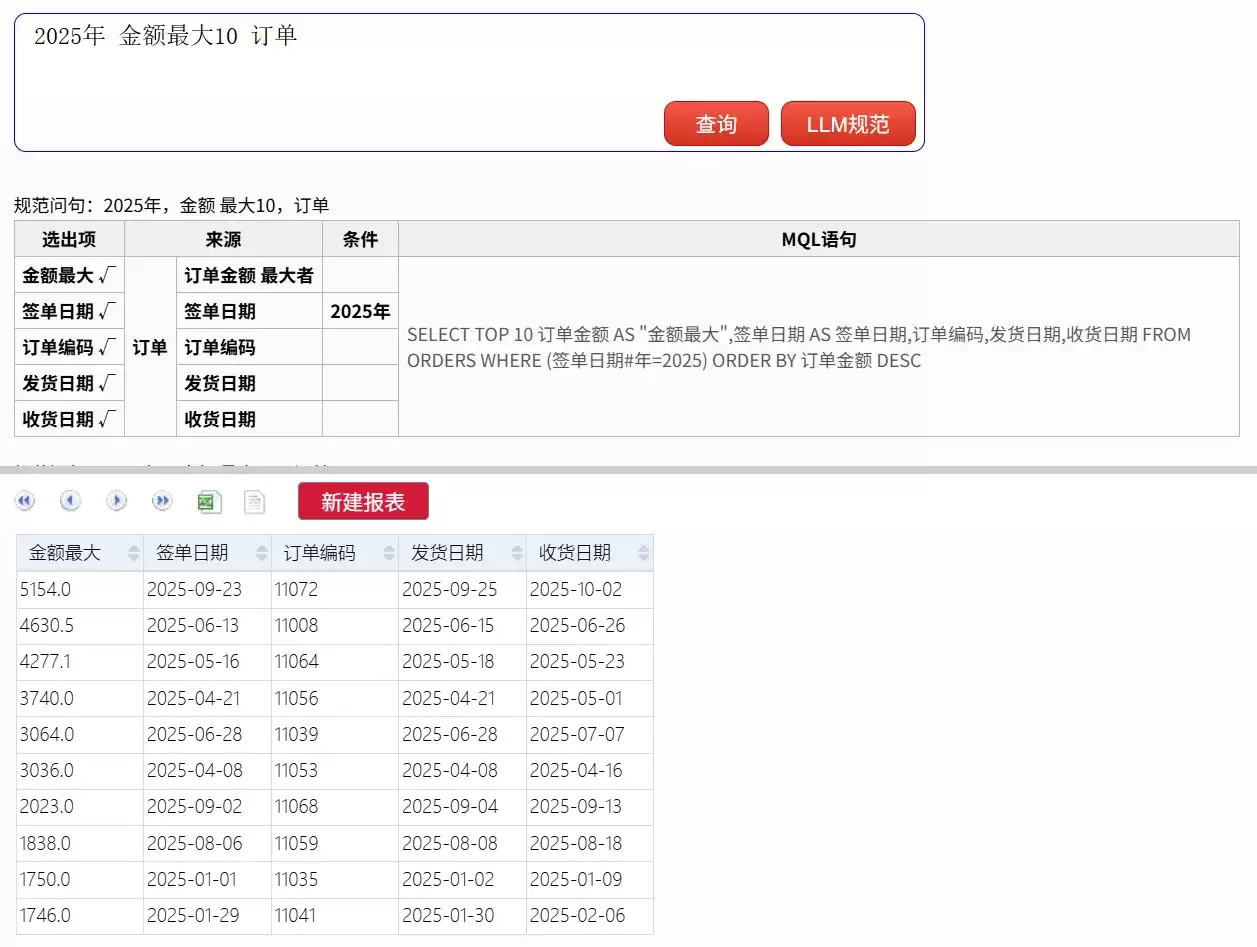
这种单表聚合(TopN)类的查询,用规范文本也能轻松表达。
还有涉及多表关联、带有聚合后过滤的复杂查询:
- 去年 北京发货 订单数 大于1 客户信息
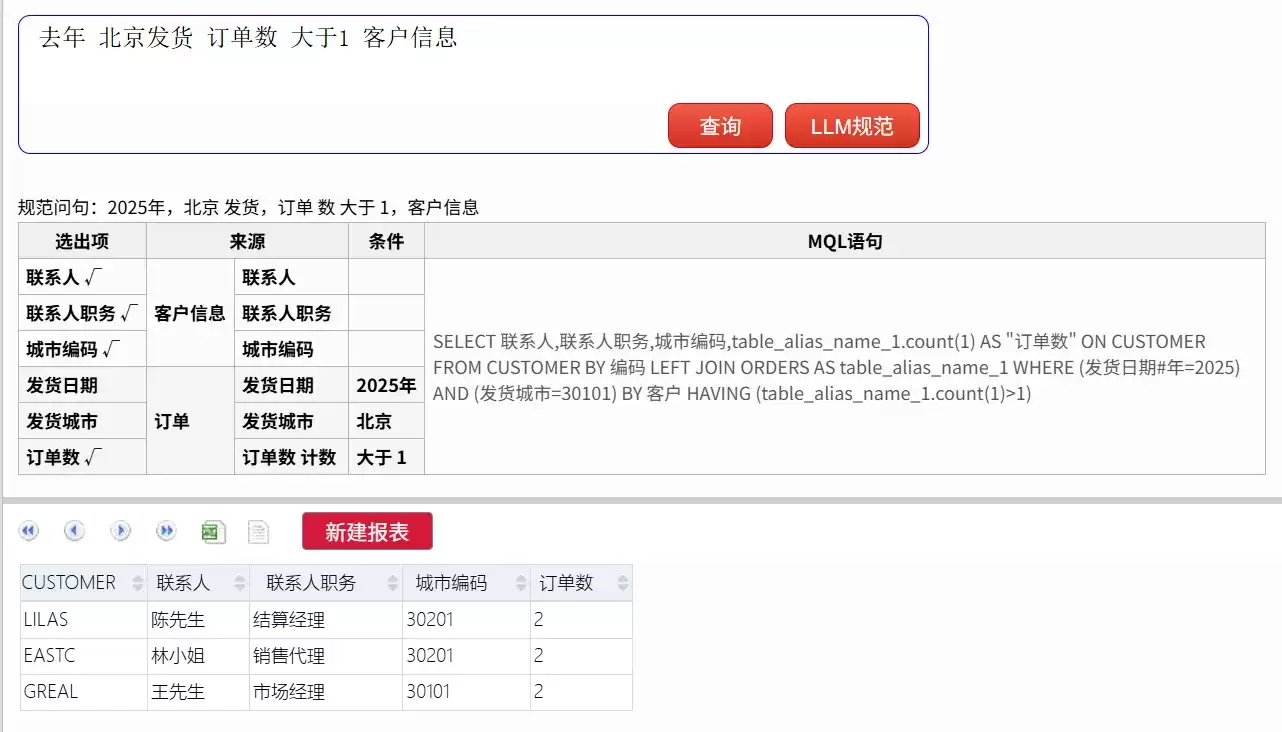
当然,一些过于口语化的表达(非规范文本)可能无法直接查询,例如:
- 我需要查询商品表中单价在9块五毛钱到等于12块钱的

这时,用户需要将其改写为规范文本,或者利用DEMO提供的“LLM规范”功能,借助大模型将口语翻译成规范文本。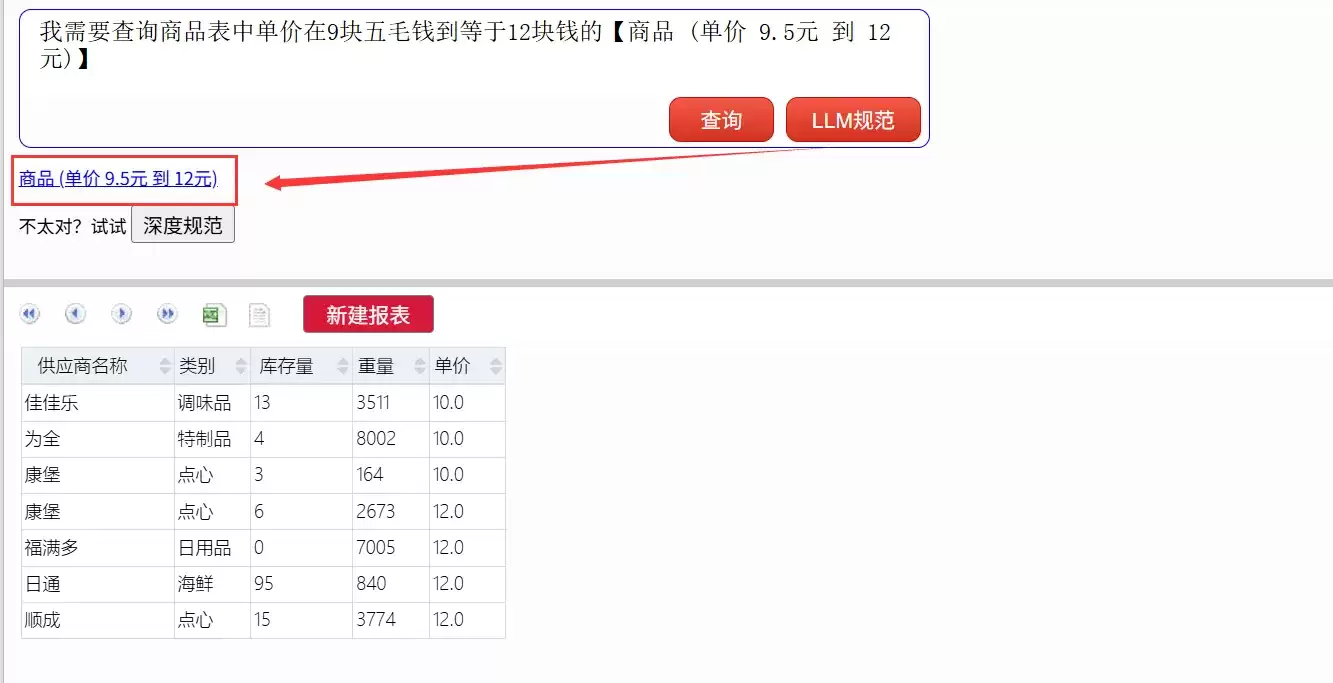 DEMO还提供了“深度规范”选项,如果初次转换结果不理想(毕竟LLM仍有幻觉),尝试深度规范可以进行更精准的转换。
DEMO还提供了“深度规范”选项,如果初次转换结果不理想(毕竟LLM仍有幻觉),尝试深度规范可以进行更精准的转换。
白盒方案的挑战:通过率
那么,纯AI方案是否也能引入类似的“人类确认”机制呢?理论上,如果AI生成的中间层或SQL足够简单,简单到业务人员能读懂,那确实可以确认。但这又引出了另一个矛盾:中间层设计得太简单,能表达的查询范围就会严重缩水,导致通过率很低;如果设计得复杂,业务人员又无法理解和确认。
有人可能会想:让AI先把中间层“翻译”成一段自然语言描述给用户确认,确认后再执行。但这并不是真正的白盒方案,因为那段用于确认的自然语言描述仍然是AI生成的,它可能与中间层的实际逻辑不一致。用户确认的只是AI的描述,而不是将要执行的逻辑本身,幻觉问题只是换了个位置,并未被消除。
白盒方案的核心在于:用于确认的文本本身,必须是由规则引擎生成的,或者其本身就是人类可读的确定性表达。并且,确认之后的执行路径必须是完全确定性的。润乾NLQ直接使用规范文本作为中间层,它既是规则引擎的确定性输入,又是人类可直接确认的自然语言,一举两得。
目前,规范文本的设计已经足够丰富,支持四种主要的查询范式(单表明细、单表聚合、主子实体、多维对齐汇总),配合词典中的字段词、实体、宏词、动词、指标等配置,能够覆盖BI场景中绝大部分的查询需求。这不是一个拍脑袋想出来的简单格式,而是一个经过实践检验的、在保持人机可读性的同时具备足够表达能力的中间语言。
可以通过以下示例感受规范文本的能力范围:
一、单表明细
1. 零售价 包装方式 零件
2. 所在国家 中国 客户 名称 账户余额
3. 去年 订单
4. 零售价 小于 50元 零件
5. 订单状态 未完成 订单
6. 市场细分 汽车 客户
7. 区域 欧洲 供应商
8. 零件编号 名称 品牌 零件
9. 今年 3月 订单
10. 发货日期 等于 上周一 订单明细
11. 实际到货日期 大于 承诺到货日期 订单明细
12. 账户余额 大于 10000元 客户
13. 品牌 "Brand#" 开头 零件
14. 零售价 100元 到 200元 零件
15. 名称 联系电话 供应商
二、单表聚合
16. 平均 零售价
17. 上个月 客户 订单总金额 总和
18. 订单总金额 最大的5个 订单
19. 品牌 零件 数
20. 国家 客户 数
21. 所在国家 中国 客户 账户余额 总和
22. 最小 订单总金额 最大 订单总金额 平均 订单总金额
23. 订单日期 最早
24. 零件类型 零售价 最大
三、主子实体
25. 客户 订单 数
26. 没有 订单 客户
27. 客户 零件 大型抛光钢
28. 去年 有 订单 客户
29. 供应商 零件 数
30. 订单总金额 总和 大于 100000 客户
31. 上个月 没有 订单 客户
32. 零件 客户 数
33. 有 已退货明细 订单
34. 订单状态 未完成 客户 订单 数
四、多维对齐汇总
35. 国家 客户 数,供应商 数
36. 订单优先级 (已完成 订单 数) (未完成 订单 数)
37. 品牌 零件 数,供应商 数
38. 行业 (客户 数) (订单总金额 总和)
39. 年 区域 订单总金额 总和
深入讨论通过率,需要区分两种场景:
如果不接入LLM
如果接入LLM
无论是否接入LLM,润乾NLQ都保留了最终的确定性兜底。LLM在这里扮演的角色只是一个翻译工具(或者由人工直接书写),负责将口语转成规范文本。一旦规范文本被确认并交给规则引擎,后续就是确定性的执行。大模型是翻译官,而不是决策者。
即便如此,仍然会有一些查询是当前规范文本描述不了的。例如“按订单金额从高到低排序”。NLQ的处理方案是在查询结果界面上,点击列标题就能实现排序,支持多字段、升降序。排序本身不是能力问题,用自然语言描述复杂的排序逻辑其实很别扭:“先按金额降序,金额相同的再按订单日期升序”,写出来比用鼠标点几下复杂得多。对于这类操作,界面交互往往比自然语言更高效。
类似的还有跨行组计算(如环比、同比、累计、占比、排名等)。这类复杂运算可能涉及不同层次的范围,用SQL生成时还会用到繁琐且兼容性不佳的窗口函数。硬要在NLQ里用自然语言处理,不仅用户描述起来不便,生成的难度也很高。对于这种情况,润乾的解决方案不是硬撑,而是承认边界,并用NLR(自然语言报表)来补足。
例如,要计算每个月的销售额增长率,可以先用NLQ查出结果集,然后在NLR里通过汉语命令计算增长率: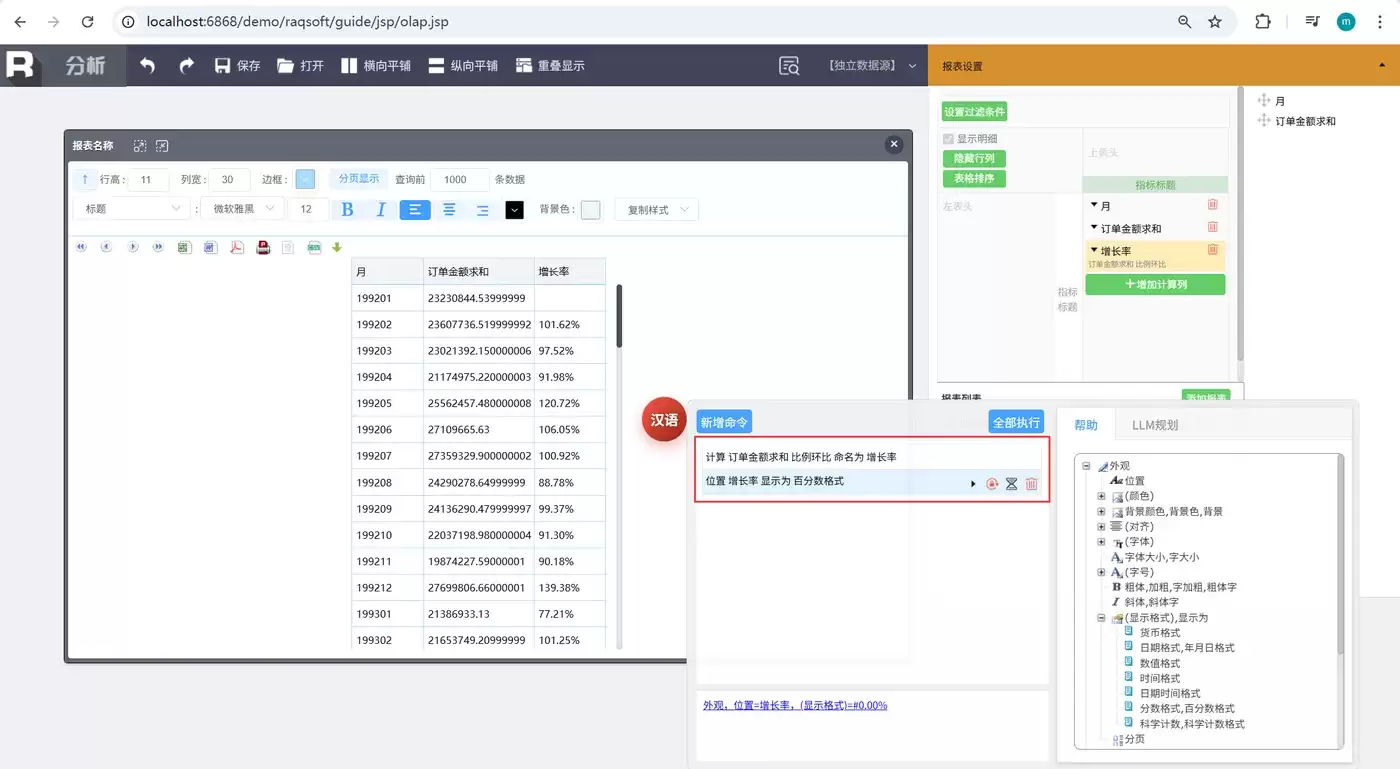
输入两条汉语命令就能搞定:
- 计算 订单金额求和 比例环比 命名为 增长率
- 位置 增长率 显示为 百分数格式
NLQ负责把数据查出来,NLR负责在结果集上继续用汉语进行加工:计算环比、排名、设置格式、生成图表。再加上界面排序等辅助功能,就形成了一个从查询到分析再到展示的完整闭环。
只有采用这种白盒机制,引入人类确认环节,Text2SQL才能真正实现工业级落地。它不是靠宣称100%准确,而是依靠设计上的确定性来保证准确,依靠规范文本的丰富表达能力来保证通过率。
润乾NLQ的AI并不一定比别人的更聪明,它的关键在于不把命运完全交给AI。白盒方案的本质,是用确定性规则兜底,将AI的不确定性限制在人类可确认的范围内。这条路看起来没有黑盒方案那么“炫酷”和“智能”,但在追求稳定可靠的企业级应用落地上,这或许是唯一走得通的路。
